Difference between revisions of "Grammar, context-free"
(Importing text file) |
Ulf Rehmann (talk | contribs) m (tex encoded by computer) |
||
| Line 1: | Line 1: | ||
| + | <!-- | ||
| + | g0447801.png | ||
| + | $#A+1 = 71 n = 1 | ||
| + | $#C+1 = 71 : ~/encyclopedia/old_files/data/G044/G.0404780 Grammar, context\AAhfree, | ||
| + | Automatically converted into TeX, above some diagnostics. | ||
| + | Please remove this comment and the {{TEX|auto}} line below, | ||
| + | if TeX found to be correct. | ||
| + | --> | ||
| + | |||
| + | {{TEX|auto}} | ||
| + | {{TEX|done}} | ||
| + | |||
''CF-grammar'' | ''CF-grammar'' | ||
| − | A context-sensitive grammar (cf. [[Grammar, context-sensitive|Grammar, context-sensitive]]) all rules of which have the form | + | A context-sensitive grammar (cf. [[Grammar, context-sensitive|Grammar, context-sensitive]]) all rules of which have the form $ A \rightarrow \theta $, |
| + | where $ A $ | ||
| + | is a non-terminal symbol and $ \theta $ | ||
| + | is a non-empty string (the so-called context-free rules). Languages generated by such grammars are said to be context-free languages. Thus, the language $ \{ {a ^ {n} b ^ {n} } : {n = 1, 2 ,\dots } \} $ | ||
| + | is generated by the context-free grammar with rules $ I \rightarrow aIb $, | ||
| + | $ I \rightarrow ab $, | ||
| + | where $ I $ | ||
| + | is an initial symbol. | ||
| − | The condition that | + | The condition that $ \theta $ |
| + | be non-empty may be omitted from the definition of a context-free language without materially altering the class of languages thereby (the only additional languages are those obtained from context-free languages by addition of the empty string). Context-free grammars constitute the class of formal grammars (cf. [[Grammar, formal|Grammar, formal]]) which is most frequently employed in applications; they are extensively used in the construction of mathematical models of natural languages (cf. [[Mathematical linguistics|Mathematical linguistics]]) and in the description of programming languages. The class of context-free languages is a proper subclass of the class of context-sensitive languages (e.g. the context-sensitive language $ \{ {a ^ {n} b ^ {n} c ^ {n} } : {n = 1, 2 ,\dots } \} $ | ||
| + | is not context-free, cf. [[Grammar, context-sensitive|Grammar, context-sensitive]]) and coincides with the class of languages accepted by so-called push-down automata. | ||
| − | Each context-free grammar can be transformed, in an equivalent way, into Chomsky normal form — a context-free grammar all rules of which have the form | + | Each context-free grammar can be transformed, in an equivalent way, into Chomsky normal form — a context-free grammar all rules of which have the form $ A \rightarrow BC $ |
| + | and $ A \rightarrow a $, | ||
| + | and also into Greibach normal form, all rules of which have the form $ A \rightarrow a B C $, | ||
| + | $ A \rightarrow aB $ | ||
| + | and $ A \rightarrow a $( | ||
| + | in both cases $ A, B, C $ | ||
| + | are non-terminal symbols, while $ a $ | ||
| + | is a terminal symbol). Context-free languages are also defined by categorial grammars, dominating grammars and dependency grammars (cf. [[Grammar, categorial|Grammar, categorial]]; [[Grammar, dominating|Grammar, dominating]]). Context-free languages are also sometimes defined by so-called normal systems of equations in languages, which are another form of notation of context-free grammars. The class of context-free languages is closed with respect to union, concatenation, permutation, and truncated iteration (and, in the presence of rules with an empty right-hand side, also with respect to iteration), and are not closed under intersection and complementation. A context-free grammar $ \Gamma $ | ||
| + | is called unambiguous if for each string of the language $ L ( \Gamma ) $ | ||
| + | there is a unique derivation tree in $ \Gamma $. | ||
| + | A context-free language is called unambiguous if it is generated by some unambiguous context-free grammar; otherwise it is called ambiguous (or inherently ambiguous). The following is an example of an ambiguous context-free language: | ||
| − | + | $$ | |
| + | \{ {a ^ {n} b ^ {n} c ^ {m} } : {n, m = 1, 2 ,\dots } \} | ||
| + | \cup \{ {a ^ {m} b ^ {n} c ^ {n} } : {n, m = 1, 2 ,\dots } \} . | ||
| + | $$ | ||
| − | If, for any context-free grammar generating a context-free language | + | If, for any context-free grammar generating a context-free language $ L $ |
| + | and for any natural number $ n $, | ||
| + | it is possible to find a string in $ L $ | ||
| + | with more than $ n $ | ||
| + | derivation trees in the given grammar, then $ L $ | ||
| + | is said to have infinite degree of ambiguousness; an example is the language $ \{ {x \widehat{x} y \widehat{y} } : {x, y \in \{ a _ {1} , a _ {2} \} ^ {+} } \} $, | ||
| + | where $ \widehat{ {}} $ | ||
| + | indicates reversal (i.e. if $ x = a _ {i _ {1} } \dots a _ {i _ {k} } $, | ||
| + | then $ \widehat{x} = a _ {i _ {k} } \dots a _ {i _ {1} } $). | ||
| − | A context-free language is said to be deterministic if it is accepted by some deterministic push-down automaton. Any deterministic language is unambiguous, but the converse is not true; for example, the unambiguous language | + | A context-free language is said to be deterministic if it is accepted by some deterministic push-down automaton. Any deterministic language is unambiguous, but the converse is not true; for example, the unambiguous language $ \{ {x \widehat{x} } : {x \in \{ a _ {1} , a _ {2} \} ^ {+} }\} $ |
| + | is not deterministic. | ||
==Complexity of derivation.== | ==Complexity of derivation.== | ||
| − | For any context-free grammar, the time complexity (number of elementary derivation steps) and the space complexity (maximal length intermediate phrase in derivation) of a derivation (cf. [[Grammar, generative|Grammar, generative]]) are bounded by linear functions from above and from below. For this reason other specific characteristics of the complexity of derivation are also introduced in the classification of context-free grammars. These characteristics are of two types: some of them ( "tree-like" characteristics) are constructed by representing the result in the form of a tree (cf. [[Grammar, context-sensitive|Grammar, context-sensitive]]), others ( "chain-like" characteristics) are based on the number or the distribution of the occurrences of non-terminal symbols into the individual steps of the derivation; in a number of important cases the "tree-like" characteristics may be connected to the "chain-like" characteristics with the same order of growth. Of the "tree-like" characteristics, the finest classification is given by the thickness, which is defined as follows. 1) To each vertex | + | For any context-free grammar, the time complexity (number of elementary derivation steps) and the space complexity (maximal length intermediate phrase in derivation) of a derivation (cf. [[Grammar, generative|Grammar, generative]]) are bounded by linear functions from above and from below. For this reason other specific characteristics of the complexity of derivation are also introduced in the classification of context-free grammars. These characteristics are of two types: some of them ( "tree-like" characteristics) are constructed by representing the result in the form of a tree (cf. [[Grammar, context-sensitive|Grammar, context-sensitive]]), others ( "chain-like" characteristics) are based on the number or the distribution of the occurrences of non-terminal symbols into the individual steps of the derivation; in a number of important cases the "tree-like" characteristics may be connected to the "chain-like" characteristics with the same order of growth. Of the "tree-like" characteristics, the finest classification is given by the thickness, which is defined as follows. 1) To each vertex $ \alpha $ |
| + | of a finite rooted tree is assigned a density of $ \alpha $, | ||
| + | a number $ \mu ( \alpha ) $, | ||
| + | such that: if $ \alpha $ | ||
| + | is a terminal vertex, then $ \mu ( \alpha ) = 0 $; | ||
| + | if $ \beta _ {1} \dots \beta _ {s} $ | ||
| + | are all the vertices entered into by arcs from $ \alpha $, | ||
| + | if $ s > 0 $ | ||
| + | and if $ m = \max \{ \mu ( \beta _ {1} ) \dots \mu ( \beta _ {s} ) \} $, | ||
| + | then: a) if $ m = \mu ( \beta _ {i} ) $ | ||
| + | only for one $ i = 1 \dots s $, | ||
| + | then $ \mu ( \alpha ) = m $; | ||
| + | b) otherwise $ \mu ( \alpha ) = m + 1 $. | ||
| + | 2) The thickness of the root of the tree is said to be the thickness of the tree. 3) If $ \Gamma $ | ||
| + | is a context-free grammar, its thickness $ \mu _ \Gamma ( n) $ | ||
| + | is defined similarly to the time complexity, replacing the length of the derivation by the thickness of the derivation tree. The same order of growth as the thickness (for a context-free grammar) is displayed by the active capacity $ I _ \Gamma ( n) $, | ||
| + | which is definable similarly to the capacity, the length of the string $ \omega _ {i} $ | ||
| + | being replaced by the number of occurrences of the non-terminal symbols in $ \omega _ {i} $. | ||
| + | The thickness of all context-free grammars is bounded from above by a logarithmic function. There exist context-free languages for which the thicknesses of arbitrary context-free grammars by which they are generated have logarithmic order of growth, such as the set of all possible "regular sequences of parentheses" (i.e. sequences of left and right round brackets distributed in a manner which is accepted in mathematical expressions). At the same time the languages generated by context-free grammars whose thickness is bounded by constants constitute an extensive class, coinciding with the closure of the class of linear languages (cf. [[Grammar, linear|Grammar, linear]]) with respect to permutations. There exist infinite sequences of functions with order of growth intermediate between constant and logarithmic and such that for any two successive terms of the sequence it is possible to find a context-free language for which the lowest-order thickness of its generating context-free grammar is comprised between these functions. Other characteristics of complexity of derivation in context-free grammars are also employed. | ||
Another subject of intensive study in context-free grammars is controlling derivations. Many different concepts of controlling derivations in context-free grammars have been proposed (a large part of which also being applicable to wider classes of grammars). Thus, a matrix grammar is obtained if some set of finite sequences of grammatical rules — "matrices" — is specified and if the derivations which are considered admissible are those for which the sequence of applications of the rules can be subdivided into the matrices (i.e. the rules are applied by "groups" only). In an ordered grammar a partial order is specified on the set of rules, and it is decided to employ at each step only those for which none of the rules which precede them in the sequence are applicable to the string obtained at this moment. In a programmed grammar two sets of rules are juxtaposed with each rule: "successful" and "unsuccessful" sets, and each rule is applied in two stages. The first stage consists of a check as to whether or not the left-hand side of the rule forms part of the string obtained at the moment; if it does, the second stage consists in replacing the left-hand side of the rule by its right-hand side and selecting the rule to be employed in the following step out of the "successful" set; if it does not, the second stage consists of the selection of the rule to be employed in the following stage out of the "unsuccessful" set. The class of languages generated by programmed context-free grammars without rules with an empty right-hand side is a proper subclass of the class of context-sensitive languages and contains the class of languages generated by context-free matrix grammars and ordered context-free grammars; both these classes are more extensive than the class of context-free languages. In the presence of rules with an empty right-hand side, programmed context-free grammars generate arbitrary recursively-enumerable languages. | Another subject of intensive study in context-free grammars is controlling derivations. Many different concepts of controlling derivations in context-free grammars have been proposed (a large part of which also being applicable to wider classes of grammars). Thus, a matrix grammar is obtained if some set of finite sequences of grammatical rules — "matrices" — is specified and if the derivations which are considered admissible are those for which the sequence of applications of the rules can be subdivided into the matrices (i.e. the rules are applied by "groups" only). In an ordered grammar a partial order is specified on the set of rules, and it is decided to employ at each step only those for which none of the rules which precede them in the sequence are applicable to the string obtained at this moment. In a programmed grammar two sets of rules are juxtaposed with each rule: "successful" and "unsuccessful" sets, and each rule is applied in two stages. The first stage consists of a check as to whether or not the left-hand side of the rule forms part of the string obtained at the moment; if it does, the second stage consists in replacing the left-hand side of the rule by its right-hand side and selecting the rule to be employed in the following step out of the "successful" set; if it does not, the second stage consists of the selection of the rule to be employed in the following stage out of the "unsuccessful" set. The class of languages generated by programmed context-free grammars without rules with an empty right-hand side is a proper subclass of the class of context-sensitive languages and contains the class of languages generated by context-free matrix grammars and ordered context-free grammars; both these classes are more extensive than the class of context-free languages. In the presence of rules with an empty right-hand side, programmed context-free grammars generate arbitrary recursively-enumerable languages. | ||
==Algorithmic problems.== | ==Algorithmic problems.== | ||
| − | There exist algorithms by means of which it is possible to tell whether a language generated by some context-free grammar is empty or finite. However, the following properties of languages and relations between different languages are undecidable for the class of context-free grammars: whether the complement is empty, finite or context-free; whether the language is ambiguous, deterministic, linear, or regular; | + | There exist algorithms by means of which it is possible to tell whether a language generated by some context-free grammar is empty or finite. However, the following properties of languages and relations between different languages are undecidable for the class of context-free grammars: whether the complement is empty, finite or context-free; whether the language is ambiguous, deterministic, linear, or regular; $ L _ {1} = L _ {2} $; |
| + | $ L _ {1} \subseteq L _ {2} $. | ||
| + | There also exist context-free grammars $ \Gamma _ {1} $ | ||
| + | and $ \Gamma _ {2} $ | ||
| + | for which there are no algorithms by which it is possible to recognize, for arbitrary strings $ x $ | ||
| + | and $ y $ | ||
| + | in the basic alphabet $ V _ {1} $ | ||
| + | of $ \Gamma _ {1} $( | ||
| + | or in the basic alphabet $ V _ {2} $ | ||
| + | of $ \Gamma _ {2} $), | ||
| + | whether $ y $ | ||
| + | can be substituted for $ x $ | ||
| + | with respect to $ V _ {1} $ | ||
| + | and $ L ( \Gamma _ {1} ) $( | ||
| + | or whether $ x $ | ||
| + | and $ y $ | ||
| + | are interchangeable with respect to $ V _ {2} $ | ||
| + | and $ L ( \Gamma _ {2} ) $; | ||
| + | cf. [[Analytic model of a language|Analytic model of a language]]). | ||
==Complexity of recognition.== | ==Complexity of recognition.== | ||
| Line 28: | Line 107: | ||
====References==== | ====References==== | ||
<table><TR><TD valign="top">[1]</TD> <TD valign="top"> S. Ginsburg, "The mathematical theory of context-free languages" , McGraw-Hill (1966)</TD></TR></table> | <table><TR><TD valign="top">[1]</TD> <TD valign="top"> S. Ginsburg, "The mathematical theory of context-free languages" , McGraw-Hill (1966)</TD></TR></table> | ||
| − | |||
| − | |||
====Comments==== | ====Comments==== | ||
| Line 36: | Line 113: | ||
The most common form of a context-free grammar with a control of derivations is the attribute grammar introduced by D.E. Knuth. For further information on controlled grammars see [[#References|[a9]]]. | The most common form of a context-free grammar with a control of derivations is the attribute grammar introduced by D.E. Knuth. For further information on controlled grammars see [[#References|[a9]]]. | ||
| − | With respect to the complexity of recognizing the strings in a deterministic context-free grammar, the main achievement of the past decade has been the design of a recognition algorithm which simultaneously operates in polynomial time and space | + | With respect to the complexity of recognizing the strings in a deterministic context-free grammar, the main achievement of the past decade has been the design of a recognition algorithm which simultaneously operates in polynomial time and space $ O ( \mathop{\rm log} ^ {2} ( n) ) $ |
| + | by Cook. Parsing algorithms for general context-free languages which operate in time $ O ( n ^ {3} ) $ | ||
| + | have been described by J. Earley, T. Kasami and D.H. Younger. L.G. Valiant has shown that the time complexity for context-free recognition can be reduced to $ O ( n ^ \gamma ) $, | ||
| + | where $ \gamma $ | ||
| + | denotes the famous matrix-multiplication exponent (currently, $ \gamma = 2. 38 \dots $). | ||
See also [[Formal languages and automata|Formal languages and automata]]. | See also [[Formal languages and automata|Formal languages and automata]]. | ||
Revision as of 19:42, 5 June 2020
CF-grammar
A context-sensitive grammar (cf. Grammar, context-sensitive) all rules of which have the form $ A \rightarrow \theta $, where $ A $ is a non-terminal symbol and $ \theta $ is a non-empty string (the so-called context-free rules). Languages generated by such grammars are said to be context-free languages. Thus, the language $ \{ {a ^ {n} b ^ {n} } : {n = 1, 2 ,\dots } \} $ is generated by the context-free grammar with rules $ I \rightarrow aIb $, $ I \rightarrow ab $, where $ I $ is an initial symbol.
The condition that $ \theta $ be non-empty may be omitted from the definition of a context-free language without materially altering the class of languages thereby (the only additional languages are those obtained from context-free languages by addition of the empty string). Context-free grammars constitute the class of formal grammars (cf. Grammar, formal) which is most frequently employed in applications; they are extensively used in the construction of mathematical models of natural languages (cf. Mathematical linguistics) and in the description of programming languages. The class of context-free languages is a proper subclass of the class of context-sensitive languages (e.g. the context-sensitive language $ \{ {a ^ {n} b ^ {n} c ^ {n} } : {n = 1, 2 ,\dots } \} $ is not context-free, cf. Grammar, context-sensitive) and coincides with the class of languages accepted by so-called push-down automata.
Each context-free grammar can be transformed, in an equivalent way, into Chomsky normal form — a context-free grammar all rules of which have the form $ A \rightarrow BC $ and $ A \rightarrow a $, and also into Greibach normal form, all rules of which have the form $ A \rightarrow a B C $, $ A \rightarrow aB $ and $ A \rightarrow a $( in both cases $ A, B, C $ are non-terminal symbols, while $ a $ is a terminal symbol). Context-free languages are also defined by categorial grammars, dominating grammars and dependency grammars (cf. Grammar, categorial; Grammar, dominating). Context-free languages are also sometimes defined by so-called normal systems of equations in languages, which are another form of notation of context-free grammars. The class of context-free languages is closed with respect to union, concatenation, permutation, and truncated iteration (and, in the presence of rules with an empty right-hand side, also with respect to iteration), and are not closed under intersection and complementation. A context-free grammar $ \Gamma $ is called unambiguous if for each string of the language $ L ( \Gamma ) $ there is a unique derivation tree in $ \Gamma $. A context-free language is called unambiguous if it is generated by some unambiguous context-free grammar; otherwise it is called ambiguous (or inherently ambiguous). The following is an example of an ambiguous context-free language:
$$ \{ {a ^ {n} b ^ {n} c ^ {m} } : {n, m = 1, 2 ,\dots } \} \cup \{ {a ^ {m} b ^ {n} c ^ {n} } : {n, m = 1, 2 ,\dots } \} . $$
If, for any context-free grammar generating a context-free language $ L $ and for any natural number $ n $, it is possible to find a string in $ L $ with more than $ n $ derivation trees in the given grammar, then $ L $ is said to have infinite degree of ambiguousness; an example is the language $ \{ {x \widehat{x} y \widehat{y} } : {x, y \in \{ a _ {1} , a _ {2} \} ^ {+} } \} $, where $ \widehat{ {}} $ indicates reversal (i.e. if $ x = a _ {i _ {1} } \dots a _ {i _ {k} } $, then $ \widehat{x} = a _ {i _ {k} } \dots a _ {i _ {1} } $).
A context-free language is said to be deterministic if it is accepted by some deterministic push-down automaton. Any deterministic language is unambiguous, but the converse is not true; for example, the unambiguous language $ \{ {x \widehat{x} } : {x \in \{ a _ {1} , a _ {2} \} ^ {+} }\} $ is not deterministic.
Complexity of derivation.
For any context-free grammar, the time complexity (number of elementary derivation steps) and the space complexity (maximal length intermediate phrase in derivation) of a derivation (cf. Grammar, generative) are bounded by linear functions from above and from below. For this reason other specific characteristics of the complexity of derivation are also introduced in the classification of context-free grammars. These characteristics are of two types: some of them ( "tree-like" characteristics) are constructed by representing the result in the form of a tree (cf. Grammar, context-sensitive), others ( "chain-like" characteristics) are based on the number or the distribution of the occurrences of non-terminal symbols into the individual steps of the derivation; in a number of important cases the "tree-like" characteristics may be connected to the "chain-like" characteristics with the same order of growth. Of the "tree-like" characteristics, the finest classification is given by the thickness, which is defined as follows. 1) To each vertex $ \alpha $ of a finite rooted tree is assigned a density of $ \alpha $, a number $ \mu ( \alpha ) $, such that: if $ \alpha $ is a terminal vertex, then $ \mu ( \alpha ) = 0 $; if $ \beta _ {1} \dots \beta _ {s} $ are all the vertices entered into by arcs from $ \alpha $, if $ s > 0 $ and if $ m = \max \{ \mu ( \beta _ {1} ) \dots \mu ( \beta _ {s} ) \} $, then: a) if $ m = \mu ( \beta _ {i} ) $ only for one $ i = 1 \dots s $, then $ \mu ( \alpha ) = m $; b) otherwise $ \mu ( \alpha ) = m + 1 $. 2) The thickness of the root of the tree is said to be the thickness of the tree. 3) If $ \Gamma $ is a context-free grammar, its thickness $ \mu _ \Gamma ( n) $ is defined similarly to the time complexity, replacing the length of the derivation by the thickness of the derivation tree. The same order of growth as the thickness (for a context-free grammar) is displayed by the active capacity $ I _ \Gamma ( n) $, which is definable similarly to the capacity, the length of the string $ \omega _ {i} $ being replaced by the number of occurrences of the non-terminal symbols in $ \omega _ {i} $. The thickness of all context-free grammars is bounded from above by a logarithmic function. There exist context-free languages for which the thicknesses of arbitrary context-free grammars by which they are generated have logarithmic order of growth, such as the set of all possible "regular sequences of parentheses" (i.e. sequences of left and right round brackets distributed in a manner which is accepted in mathematical expressions). At the same time the languages generated by context-free grammars whose thickness is bounded by constants constitute an extensive class, coinciding with the closure of the class of linear languages (cf. Grammar, linear) with respect to permutations. There exist infinite sequences of functions with order of growth intermediate between constant and logarithmic and such that for any two successive terms of the sequence it is possible to find a context-free language for which the lowest-order thickness of its generating context-free grammar is comprised between these functions. Other characteristics of complexity of derivation in context-free grammars are also employed.
Another subject of intensive study in context-free grammars is controlling derivations. Many different concepts of controlling derivations in context-free grammars have been proposed (a large part of which also being applicable to wider classes of grammars). Thus, a matrix grammar is obtained if some set of finite sequences of grammatical rules — "matrices" — is specified and if the derivations which are considered admissible are those for which the sequence of applications of the rules can be subdivided into the matrices (i.e. the rules are applied by "groups" only). In an ordered grammar a partial order is specified on the set of rules, and it is decided to employ at each step only those for which none of the rules which precede them in the sequence are applicable to the string obtained at this moment. In a programmed grammar two sets of rules are juxtaposed with each rule: "successful" and "unsuccessful" sets, and each rule is applied in two stages. The first stage consists of a check as to whether or not the left-hand side of the rule forms part of the string obtained at the moment; if it does, the second stage consists in replacing the left-hand side of the rule by its right-hand side and selecting the rule to be employed in the following step out of the "successful" set; if it does not, the second stage consists of the selection of the rule to be employed in the following stage out of the "unsuccessful" set. The class of languages generated by programmed context-free grammars without rules with an empty right-hand side is a proper subclass of the class of context-sensitive languages and contains the class of languages generated by context-free matrix grammars and ordered context-free grammars; both these classes are more extensive than the class of context-free languages. In the presence of rules with an empty right-hand side, programmed context-free grammars generate arbitrary recursively-enumerable languages.
Algorithmic problems.
There exist algorithms by means of which it is possible to tell whether a language generated by some context-free grammar is empty or finite. However, the following properties of languages and relations between different languages are undecidable for the class of context-free grammars: whether the complement is empty, finite or context-free; whether the language is ambiguous, deterministic, linear, or regular; $ L _ {1} = L _ {2} $; $ L _ {1} \subseteq L _ {2} $. There also exist context-free grammars $ \Gamma _ {1} $ and $ \Gamma _ {2} $ for which there are no algorithms by which it is possible to recognize, for arbitrary strings $ x $ and $ y $ in the basic alphabet $ V _ {1} $ of $ \Gamma _ {1} $( or in the basic alphabet $ V _ {2} $ of $ \Gamma _ {2} $), whether $ y $ can be substituted for $ x $ with respect to $ V _ {1} $ and $ L ( \Gamma _ {1} ) $( or whether $ x $ and $ y $ are interchangeable with respect to $ V _ {2} $ and $ L ( \Gamma _ {2} ) $; cf. Analytic model of a language).
Complexity of recognition.
A string can be recognized as belonging to the language generated by a given context-free grammar with the aid of Cook's algorithm, which can be run on a Turing machine with one tape and one head, the duration of the run then being proportional to the fourth power of the string length (or to the third power if the number of tapes or heads is increased to three).
See also Grammar, regular; Grammar, linear.
References
| [1] | S. Ginsburg, "The mathematical theory of context-free languages" , McGraw-Hill (1966) |
Comments
The active capacity is also called the index (cf. [a9]).
The most common form of a context-free grammar with a control of derivations is the attribute grammar introduced by D.E. Knuth. For further information on controlled grammars see [a9].
With respect to the complexity of recognizing the strings in a deterministic context-free grammar, the main achievement of the past decade has been the design of a recognition algorithm which simultaneously operates in polynomial time and space $ O ( \mathop{\rm log} ^ {2} ( n) ) $ by Cook. Parsing algorithms for general context-free languages which operate in time $ O ( n ^ {3} ) $ have been described by J. Earley, T. Kasami and D.H. Younger. L.G. Valiant has shown that the time complexity for context-free recognition can be reduced to $ O ( n ^ \gamma ) $, where $ \gamma $ denotes the famous matrix-multiplication exponent (currently, $ \gamma = 2. 38 \dots $).
See also Formal languages and automata.
References
| [a1] | J.E. Hopcroft, J.D. Ulman, "Introduction to automata theory, languages and computation" , Addison-Wesley (1979) |
| [a2] | D.E. Knuth, "Semantics of context-free languages" Math. Syst. Theory , 2 (1968) pp. 127–145 |
| [a3] | A.V. Aho, J.D. Ullman, "The theory of parsing, translation and compiling" , 1–2 , Prentice-Hall (1973) |
| [a4] | H.R. Lewis, C.H. Papadimitriou, "Elements of the theory of computation" , Prentice-Hall (1981) |
| [a5] | J. Earley, "An effective context-free parsing algorithm" Commun. ACM , 13 (1970) pp. 94–102 |
| [a6] | T. Kasami, "An effective recognition and syntax algorithm for context-free languages" , Report AFCRL-65–758 , Air Force Cambridge Research Lab. (1965) |
| [a7] | D.H. Younger, "Recognition and parsing context-free languages in time 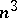 " Inf. and Control , 10 (1967) pp. 189–208 " Inf. and Control , 10 (1967) pp. 189–208 |
| [a8] | L.G. Valiant, "General context-free recognition in less than cubic time" J. Comput. System Sci. , 10 (1975) pp. 308–315 |
| [a9] | A. Salomaa, "Formal languages" , Acad. Press (1973) |
Grammar, context-free. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Grammar,_context-free&oldid=47116