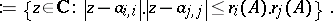|
|
| Line 1: |
Line 1: |
| | + | <!--This article has been texified automatically. Since there was no Nroff source code for this article, |
| | + | the semi-automatic procedure described at https://encyclopediaofmath.org/wiki/User:Maximilian_Janisch/latexlist |
| | + | was used. |
| | + | If the TeX and formula formatting is correct, please remove this message and the {{TEX|semi-auto}} category. |
| | + | |
| | + | Out of 130 formulas, 128 were replaced by TEX code.--> |
| | + | |
| | + | {{TEX|semi-auto}}{{TEX|partial}} |
| | ''Gerschgorin theorem, Geršgorin theorem'' | | ''Gerschgorin theorem, Geršgorin theorem'' |
| | | | |
| − | Given a complex <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g1300601.png" />-matrix, <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g1300602.png" />, with <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g1300603.png" />, then finding the eigenvalues of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g1300604.png" /> is equivalent to finding the <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g1300605.png" /> zeros of its associated characteristic polynomial | + | Given a complex $( n \times n )$-matrix, $A = [ a_{i, j} ]$, with $n \geq 2$, then finding the eigenvalues of $A$ is equivalent to finding the $n$ zeros of its associated characteristic polynomial |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g1300606.png" /></td> </tr></table>
| + | \begin{equation*} p _ { n } ( z ) : = \operatorname { det } \{ z I - A \}, \end{equation*} |
| | | | |
| − | where <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g1300607.png" /> is the identity <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g1300608.png" />-matrix (cf. also [[Matrix|Matrix]]; [[Eigen value|Eigen value]]). But for <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g1300609.png" /> large, finding these zeros can be a daunting problem. Is there an "easy" procedure which estimates these eigenvalues, without having to explicitly form the characteristic polynomial <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006010.png" /> above and then to find its zeros? This was first considered in 1931 by the Russian mathematician S. Gershgorin, who established the following result [[#References|[a1]]]. If <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006011.png" /> denotes the closed complex disc having centre <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006012.png" /> and radius <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006013.png" />, then Gershgorin showed that for each eigenvalue <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006014.png" /> of the given complex <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006015.png" />-matrix <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006016.png" /> there is a positive integer <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006017.png" />, with <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006018.png" />, such that <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006019.png" />, where | + | where $I$ is the identity $( n \times n )$-matrix (cf. also [[Matrix|Matrix]]; [[Eigen value|Eigen value]]). But for $n$ large, finding these zeros can be a daunting problem. Is there an "easy" procedure which estimates these eigenvalues, without having to explicitly form the characteristic polynomial $p _ { n } ( z )$ above and then to find its zeros? This was first considered in 1931 by the Russian mathematician S. Gershgorin, who established the following result [[#References|[a1]]]. If $\Delta _ { \delta } ( \alpha ) : = \{ z \in \mathbf{C} : | z - \alpha | \leq \delta \}$ denotes the closed complex disc having centre $\alpha$ and radius $\delta$, then Gershgorin showed that for each eigenvalue $\lambda$ of the given complex $( n \times n )$-matrix $A = [ a_{i, j} ]$ there is a positive integer $i$, with $1 \leq i \leq n$, such that $\lambda \in G _ { i } ( A )$, where |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006020.png" /></td> <td valign="top" style="width:5%;text-align:right;">(a1)</td></tr></table>
| + | \begin{equation} \tag{a1} G _ { i } ( A ) : = \Delta _ { r _ { i } ( A )} ( a _ { i , i } ) \end{equation} |
| | | | |
| | with | | with |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006021.png" /></td> </tr></table>
| + | \begin{equation*} r _ { i } ( A ) : = \sum _ { j = 1 \atop j \neq i } ^ { n } | a _ { i , j } |. \end{equation*} |
| | | | |
| − | (<img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006022.png" /> is called the <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006023.png" />th Gershgorin disc for <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006024.png" />.) As this is true for each eigenvalue <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006025.png" /> of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006026.png" />, it is evident that if <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006027.png" /> denotes the set of all eigenvalues of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006028.png" />, then | + | ($G _ { r_ i } ( A )$ is called the $i$th Gershgorin disc for $A$.) As this is true for each eigenvalue $\lambda$ of $A$, it is evident that if $\sigma ( A )$ denotes the set of all eigenvalues of $A$, then |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006029.png" /></td> <td valign="top" style="width:5%;text-align:right;">(a2)</td></tr></table>
| + | \begin{equation} \tag{a2} \sigma ( A ) \subseteq \cup _ { i = 1 } ^ { n } G _ { i } ( A ). \end{equation} |
| | | | |
| − | Indeed, let <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006030.png" /> be any eigenvalue of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006031.png" />, so that there is a complex vector <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006032.png" />, with <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006033.png" />, such that <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006034.png" />. As <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006035.png" />, then <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006036.png" />, and there is an <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006037.png" />, with <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006038.png" />, such that <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006039.png" />. Taking the <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006040.png" />th component of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006041.png" /> gives <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006042.png" />, or equivalently | + | Indeed, let $\lambda$ be any eigenvalue of $A = [ a_{i, j} ]$, so that there is a complex vector $\mathbf x = [ x _ { 1 } \ldots x _ { n } ] ^ { T }$, with $ \mathbf{x} \neq \mathbf{O}$, such that $A \mathbf{x} = \lambda \mathbf{x}$. As $ \mathbf{x} \neq \mathbf{O}$, then $\operatorname { max } _ { 1 \leq j \leq n } | x _ { j } | > 0$, and there is an $i$, with $1 \leq i \leq n$, such that $| x _ { i } | = \operatorname { max } _ { 1 \leq j \leq n } | x _ { j } |$. Taking the $i$th component of $A \mathbf{x} = \lambda \mathbf{x}$ gives $\sum _ { j = 1 } ^ { n } a _ { i ,\, j }\, x _ { j } = \lambda x _ { i }$, or equivalently |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006043.png" /></td> </tr></table>
| + | \begin{equation*} ( \lambda - a _ { i , i} ) x _ { i } = \sum _ { j = 1 \atop j \neq i } ^ { n } a _ { i ,\, j } x _ { j }. \end{equation*} |
| | | | |
| | On taking absolute values in the above expression and using the triangle inequality, this gives | | On taking absolute values in the above expression and using the triangle inequality, this gives |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006044.png" /></td> <td valign="top" style="width:5%;text-align:right;">(a3)</td></tr></table>
| + | \begin{equation} \tag{a3} | \lambda - a _ { i , i} | . | x _ { i } | \leq \sum _ { \substack{j = 1 \\ j \neq i }} ^ { n } | a _ { i , j} | . | x _ { j } | \leq r _ { i } ( A ) . | x _ { i } |, \end{equation} |
| | | | |
| − | the last inequality following from the definition of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006045.png" /> in (a1) and the fact that <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006046.png" /> for all <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006047.png" />. Dividing through by <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006048.png" /> in (a3) gives that <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006049.png" />. | + | the last inequality following from the definition of $r _ { i } ( A )$ in (a1) and the fact that $| x _ { j } | \leq | x _ { i }|$ for all $1 \leq j \leq n$. Dividing through by $| x _ { i } | > 0$ in (a3) gives that $\lambda \in G _ { i } ( A )$. |
| | | | |
| − | In the same paper, Gershgorin also established the following interesting result: If the <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006050.png" /> discs <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006051.png" /> of (a2) consist of two non-empty disjoint sets <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006052.png" /> and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006053.png" />, where <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006054.png" /> consists of the union of, say, <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006055.png" /> discs and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006056.png" /> consists of the union of the remaining <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006057.png" /> discs, then <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006058.png" /> contains exactly <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006059.png" /> eigenvalues (counting multiplicities) of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006060.png" />, while <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006061.png" /> contains exactly <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006062.png" /> eigenvalues of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006063.png" />. (The proof of this depends on the fact that the zeros of the characteristic polynomial <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006064.png" /> vary continuously with the entries <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006065.png" /> of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006066.png" />.) | + | In the same paper, Gershgorin also established the following interesting result: If the $n$ discs $G _ { i } ( A )$ of (a2) consist of two non-empty disjoint sets $S$ and $T$, where $S$ consists of the union of, say, $k$ discs and $T$ consists of the union of the remaining $n - k$ discs, then $S$ contains exactly $k$ eigenvalues (counting multiplicities) of $A$, while $T$ contains exactly $n - k$ eigenvalues of $T$. (The proof of this depends on the fact that the zeros of the characteristic polynomial $p _ { n } ( z )$ vary continuously with the entries $a_{i,\,j}$ of $A$.) |
| | | | |
| − | One of the most beautiful results in this area, having to do with the sharpness of the inclusion of (a2), is a result of O. Taussky [[#References|[a2]]], which depends on the following use of directed graphs (cf. also [[Graph, oriented|Graph, oriented]]). Given a complex <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006067.png" />-matrix <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006068.png" />, with <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006069.png" />, let <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006070.png" /> be <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006071.png" /> distinct points, called vertices, in the plane. Then, for each <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006072.png" />, let <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006073.png" /> denote an arc from vertex <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006074.png" /> to vertex <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006075.png" />. The collection of all these arcs defines the directed graph of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006076.png" />. Then the matrix <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006077.png" />, with <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006078.png" />, is said to be irreducible if, given any distinct vertices <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006079.png" /> and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006080.png" />, there is a sequence of abutting arcs from <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006081.png" /> to <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006082.png" />, i.e., | + | One of the most beautiful results in this area, having to do with the sharpness of the inclusion of (a2), is a result of O. Taussky [[#References|[a2]]], which depends on the following use of directed graphs (cf. also [[Graph, oriented|Graph, oriented]]). Given a complex $( n \times n )$-matrix $A = [ a_{i, j} ]$, with $n \geq 2$, let $\{ P _ { i } \} _ { i = 1 } ^ { n }$ be $n$ distinct points, called vertices, in the plane. Then, for each $a _ { i , j } \neq 0$, let $\overset{\rightharpoonup} { P _ { i } P _ { j } }$ denote an arc from vertex $i$ to vertex $j$. The collection of all these arcs defines the directed graph of $A$. Then the matrix $A = [ a_{i, j} ]$, with $n \geq 2$, is said to be irreducible if, given any distinct vertices $i$ and $j$, there is a sequence of abutting arcs from $i$ to $j$, i.e., |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006083.png" /></td> </tr></table>
| + | \begin{equation*} \overrightarrow{ P _ { i } P _ { \text{l}_1 } } , \overrightarrow{ P _ { \text{l}_1 } P _ { \text{l}_2 } } , \dots , \overrightarrow{ P _ { \text{l}_m } P _ { \text{l}_{m+1} } }, \end{equation*} |
| | | | |
| − | where <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006084.png" />. | + | where $\text{l} _ { m + 1 } = j $. |
| | | | |
| − | Taussky's theorem is this. Let <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006085.png" /> be any irreducible complex <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006086.png" />-matrix, with <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006087.png" />. If <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006088.png" /> is an eigenvalue of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006089.png" /> which lies on the boundary of the union of the Gershgorin discs of (a2), then <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006090.png" /> lies on the boundary of each Gershgorin circle, i.e., from (a1) it follows that | + | Taussky's theorem is this. Let $A = [ a_{i, j} ]$ be any irreducible complex $( n \times n )$-matrix, with $n \geq 2$. If $\lambda$ is an eigenvalue of $A$ which lies on the boundary of the union of the Gershgorin discs of (a2), then $\lambda$ lies on the boundary of each Gershgorin circle, i.e., from (a1) it follows that |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006091.png" /></td> </tr></table>
| + | \begin{equation*} | \lambda - a _ { i , i} | = r _ { i } ( A ) \text { for each } 1 \leq i \leq n. \end{equation*} |
| | | | |
| − | Next, there is related work of A. Brauer [[#References|[a3]]] on estimating the eigenvalues of a complex <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006092.png" />-matrix (<img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006093.png" />), which uses Cassini ovals instead of discs. For any integers <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006094.png" /> and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006095.png" /> (<img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006096.png" />) with <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006097.png" />, the <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006098.png" />th Cassini oval is defined by (cf. also [[Cassini oval|Cassini oval]]) | + | Next, there is related work of A. Brauer [[#References|[a3]]] on estimating the eigenvalues of a complex $( n \times n )$-matrix ($n \geq 2$), which uses Cassini ovals instead of discs. For any integers $i$ and $j$ ($1 \leq i , j \leq n$) with $i \neq j$, the $( i , j )$th Cassini oval is defined by (cf. also [[Cassini oval|Cassini oval]]) |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g13006099.png" /></td> <td valign="top" style="width:5%;text-align:right;">(a4)</td></tr></table>
| + | \begin{equation} \tag{a4} K _ {i ,\, j } ( A ) : = \end{equation} |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060100.png" /></td> </tr></table> | + | <table class="eq" style="width:100%;"> <tr><td style="width:94%;text-align:center;" valign="top"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060100.png"/></td> </tr></table> |
| | | | |
| − | Then Brauer's theorem is that, for any eigenvalue <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060101.png" /> of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060102.png" />, there exist <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060103.png" /> and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060104.png" />, with <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060105.png" />, such that <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060106.png" />, and this now gives the associated eigenvalue inclusion | + | Then Brauer's theorem is that, for any eigenvalue $\lambda$ of $A$, there exist $i$ and $j$, with $i \neq j$, such that $\lambda \in K _ { i ,\, j } ( A )$, and this now gives the associated eigenvalue inclusion |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060107.png" /></td> <td valign="top" style="width:5%;text-align:right;">(a5)</td></tr></table>
| + | \begin{equation} \tag{a5} \sigma ( A ) \subseteq \cup _ { i , j = 1 \atop i \neq j } ^ { n } K _ { i , j } ( A ). \end{equation} |
| | | | |
| − | Note that there are now <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060108.png" /> such Cassini ovals in (a5), as opposed to the <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060109.png" /> Gershgorin discs in (a2). But it is equally important to note that the eigenvalue inclusions of (a2) and (a5) use the exact same data from the matrix <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060110.png" />, i.e., <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060111.png" /> and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060112.png" />. So, which of the eigenvalue inclusions of (a2) and (a5) is smaller and hence better? It turns out that | + | Note that there are now $n ( n - 1 ) / 2$ such Cassini ovals in (a5), as opposed to the $n$ Gershgorin discs in (a2). But it is equally important to note that the eigenvalue inclusions of (a2) and (a5) use the exact same data from the matrix $A = [ a_{i, j} ]$, i.e., $\{ a_{i , i} \} _ { i = 1 } ^ { n }$ and $\{ r _ { i } ( A ) \} _ { i = 1 } ^ { n }$. So, which of the eigenvalue inclusions of (a2) and (a5) is smaller and hence better? It turns out that |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060113.png" /></td> <td valign="top" style="width:5%;text-align:right;">(a6)</td></tr></table>
| + | \begin{equation} \tag{a6} \bigcup _ { i , j = 1 \atop i \neq j } ^ { n } K _ { i ,\, j} ( A ) \subseteq \bigcup _ { i = 1 } ^ { n } G _ { i } ( A ), \end{equation} |
| | | | |
| − | for any complex <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060114.png" />-matrix <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060115.png" />, so that the Cassini ovals are always at least as good as the Gershgorin discs. (The result (a6) was known to Brauer, but was somehow neglected in the literature.) | + | for any complex $( n \times n )$-matrix $A$, so that the Cassini ovals are always at least as good as the Gershgorin discs. (The result (a6) was known to Brauer, but was somehow neglected in the literature.) |
| | | | |
| − | Finally, as both eigenvalue inclusions (a2) and (a5) depend only on the row sums <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060116.png" />, it is evident that these inclusions apply not to just the single matrix <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060117.png" />, but to a whole class of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060118.png" />-matrices, namely, | + | Finally, as both eigenvalue inclusions (a2) and (a5) depend only on the row sums $r _ { i } ( A )$, it is evident that these inclusions apply not to just the single matrix $A$, but to a whole class of $( n \times n )$-matrices, namely, |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060119.png" /></td> </tr></table>
| + | \begin{equation*} \Omega ( A ) : = \end{equation*} |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060120.png" /></td> </tr></table>
| + | \begin{equation*} : = \{ B = [ b _ { i , j } ] : b _ { i , i } = a _ { i , i } , \text { and } r _ { i } ( B ) = r _ { i } ( A ) , 1 \leq i \leq n \}. \end{equation*} |
| | | | |
| | Thus, | | Thus, |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060121.png" /></td> </tr></table>
| + | \begin{equation*} \sigma ( B ) \subseteq \cup _ { i , j = 1 \atop i \neq j } ^ { n } K _ { i ,\, j } ( A ) \subseteq \cup _ { i = 1 } ^ { n } G _ { i } ( A ) \end{equation*} |
| | | | |
| − | for each <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060122.png" /> in <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060123.png" />. Then, if <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060124.png" /> denotes the set of all eigenvalues of all <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060125.png" /> in <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060126.png" />, it follows that | + | for each $B$ in $\Omega ( A )$. Then, if $\sigma ( \Omega ( A ) )$ denotes the set of all eigenvalues of all $B$ in $\Omega ( A )$, it follows that |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060127.png" /></td> <td valign="top" style="width:5%;text-align:right;">(a7)</td></tr></table>
| + | \begin{equation} \tag{a7} \sigma ( \Omega ( A ) ) \subseteq \cup _ { i , j = 1 \atop j \neq j } ^ { n } K _ { i,\, j } ( A ) \subseteq \cup _ { i = 1 } ^ { n } G _ { i } ( A ). \end{equation} |
| | | | |
| | How sharp is the first inclusion of (a7)? It was shown in 1999 by R.S. Varga and A. Krautstengl [[#References|[a4]]] that | | How sharp is the first inclusion of (a7)? It was shown in 1999 by R.S. Varga and A. Krautstengl [[#References|[a4]]] that |
| | | | |
| − | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060128.png" /></td> <td valign="top" style="width:5%;text-align:right;">(a8)</td></tr></table>
| + | \begin{equation} \tag{a8} \sigma ( \Omega ( A ) ) = \left\{ \begin{array} { c c } { \text { boundary of } K _ { 1,2 } ( A ) } & { n = 2; } \\ { \cup _ { i ,\, j = 1 , i \neq j } ^ { n } K _ { i ,\, j } ( A ) } & { n \geq 3. } \end{array} \right. \end{equation} |
| | | | |
| − | Thus, for <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/g/g130/g130060/g130060129.png" />, it can be said that the Cassini ovals give "perfect" results. | + | Thus, for $n \geq 3$, it can be said that the Cassini ovals give "perfect" results. |
| | | | |
| | Gershgorin's discs and Brauer's Cassini ovals are mentioned in [[#References|[a5]]], [[#References|[a6]]]. A more detailed treatment of these topics can be found in [[#References|[a7]]]. | | Gershgorin's discs and Brauer's Cassini ovals are mentioned in [[#References|[a5]]], [[#References|[a6]]]. A more detailed treatment of these topics can be found in [[#References|[a7]]]. |
| | | | |
| | ====References==== | | ====References==== |
| − | <table><TR><TD valign="top">[a1]</TD> <TD valign="top"> S. Gerschgorin, "Ueber die Abgrenzung der Eigenwerte einer Matrix" ''Izv. Akad. Nauk. SSSR Ser. Mat.'' , '''1''' (1931) pp. 749–754</TD></TR><TR><TD valign="top">[a2]</TD> <TD valign="top"> O. Taussky, "Bounds for the characteristic roots of matrices" ''Duke Math. J.'' , '''15''' (1948) pp. 1043–1044</TD></TR><TR><TD valign="top">[a3]</TD> <TD valign="top"> A. Brauer, "Limits for the characteristic roots of a matrix" ''Duke Math. J.'' , '''13''' (1946) pp. 387–395</TD></TR><TR><TD valign="top">[a4]</TD> <TD valign="top"> R.S. Varga, A. Krautstengl, "On Geršgorin-type problems and ovals of Cassini" ''Electron. Trans. Numer. Anal.'' , '''8''' (1999) pp. 15–20</TD></TR><TR><TD valign="top">[a5]</TD> <TD valign="top"> R.S. Varga, "Matrix iterative analysis" , Springer (2000) (Edition: Second)</TD></TR><TR><TD valign="top">[a6]</TD> <TD valign="top"> R.A. Horn, C.R. Johnson, "Matrix analysis" , Cambridge Univ. Press (1985)</TD></TR><TR><TD valign="top">[a7]</TD> <TD valign="top"> R.S. Varga, "Geršgorin and his circles" , Springer (to appear)</TD></TR></table> | + | <table><tr><td valign="top">[a1]</td> <td valign="top"> S. Gerschgorin, "Ueber die Abgrenzung der Eigenwerte einer Matrix" ''Izv. Akad. Nauk. SSSR Ser. Mat.'' , '''1''' (1931) pp. 749–754</td></tr><tr><td valign="top">[a2]</td> <td valign="top"> O. Taussky, "Bounds for the characteristic roots of matrices" ''Duke Math. J.'' , '''15''' (1948) pp. 1043–1044</td></tr><tr><td valign="top">[a3]</td> <td valign="top"> A. Brauer, "Limits for the characteristic roots of a matrix" ''Duke Math. J.'' , '''13''' (1946) pp. 387–395</td></tr><tr><td valign="top">[a4]</td> <td valign="top"> R.S. Varga, A. Krautstengl, "On Geršgorin-type problems and ovals of Cassini" ''Electron. Trans. Numer. Anal.'' , '''8''' (1999) pp. 15–20</td></tr><tr><td valign="top">[a5]</td> <td valign="top"> R.S. Varga, "Matrix iterative analysis" , Springer (2000) (Edition: Second)</td></tr><tr><td valign="top">[a6]</td> <td valign="top"> R.A. Horn, C.R. Johnson, "Matrix analysis" , Cambridge Univ. Press (1985)</td></tr><tr><td valign="top">[a7]</td> <td valign="top"> R.S. Varga, "Geršgorin and his circles" , Springer (to appear)</td></tr></table> |
Gerschgorin theorem, Geršgorin theorem
Given a complex $( n \times n )$-matrix, $A = [ a_{i, j} ]$, with $n \geq 2$, then finding the eigenvalues of $A$ is equivalent to finding the $n$ zeros of its associated characteristic polynomial
\begin{equation*} p _ { n } ( z ) : = \operatorname { det } \{ z I - A \}, \end{equation*}
where $I$ is the identity $( n \times n )$-matrix (cf. also Matrix; Eigen value). But for $n$ large, finding these zeros can be a daunting problem. Is there an "easy" procedure which estimates these eigenvalues, without having to explicitly form the characteristic polynomial $p _ { n } ( z )$ above and then to find its zeros? This was first considered in 1931 by the Russian mathematician S. Gershgorin, who established the following result [a1]. If $\Delta _ { \delta } ( \alpha ) : = \{ z \in \mathbf{C} : | z - \alpha | \leq \delta \}$ denotes the closed complex disc having centre $\alpha$ and radius $\delta$, then Gershgorin showed that for each eigenvalue $\lambda$ of the given complex $( n \times n )$-matrix $A = [ a_{i, j} ]$ there is a positive integer $i$, with $1 \leq i \leq n$, such that $\lambda \in G _ { i } ( A )$, where
\begin{equation} \tag{a1} G _ { i } ( A ) : = \Delta _ { r _ { i } ( A )} ( a _ { i , i } ) \end{equation}
with
\begin{equation*} r _ { i } ( A ) : = \sum _ { j = 1 \atop j \neq i } ^ { n } | a _ { i , j } |. \end{equation*}
($G _ { r_ i } ( A )$ is called the $i$th Gershgorin disc for $A$.) As this is true for each eigenvalue $\lambda$ of $A$, it is evident that if $\sigma ( A )$ denotes the set of all eigenvalues of $A$, then
\begin{equation} \tag{a2} \sigma ( A ) \subseteq \cup _ { i = 1 } ^ { n } G _ { i } ( A ). \end{equation}
Indeed, let $\lambda$ be any eigenvalue of $A = [ a_{i, j} ]$, so that there is a complex vector $\mathbf x = [ x _ { 1 } \ldots x _ { n } ] ^ { T }$, with $ \mathbf{x} \neq \mathbf{O}$, such that $A \mathbf{x} = \lambda \mathbf{x}$. As $ \mathbf{x} \neq \mathbf{O}$, then $\operatorname { max } _ { 1 \leq j \leq n } | x _ { j } | > 0$, and there is an $i$, with $1 \leq i \leq n$, such that $| x _ { i } | = \operatorname { max } _ { 1 \leq j \leq n } | x _ { j } |$. Taking the $i$th component of $A \mathbf{x} = \lambda \mathbf{x}$ gives $\sum _ { j = 1 } ^ { n } a _ { i ,\, j }\, x _ { j } = \lambda x _ { i }$, or equivalently
\begin{equation*} ( \lambda - a _ { i , i} ) x _ { i } = \sum _ { j = 1 \atop j \neq i } ^ { n } a _ { i ,\, j } x _ { j }. \end{equation*}
On taking absolute values in the above expression and using the triangle inequality, this gives
\begin{equation} \tag{a3} | \lambda - a _ { i , i} | . | x _ { i } | \leq \sum _ { \substack{j = 1 \\ j \neq i }} ^ { n } | a _ { i , j} | . | x _ { j } | \leq r _ { i } ( A ) . | x _ { i } |, \end{equation}
the last inequality following from the definition of $r _ { i } ( A )$ in (a1) and the fact that $| x _ { j } | \leq | x _ { i }|$ for all $1 \leq j \leq n$. Dividing through by $| x _ { i } | > 0$ in (a3) gives that $\lambda \in G _ { i } ( A )$.
In the same paper, Gershgorin also established the following interesting result: If the $n$ discs $G _ { i } ( A )$ of (a2) consist of two non-empty disjoint sets $S$ and $T$, where $S$ consists of the union of, say, $k$ discs and $T$ consists of the union of the remaining $n - k$ discs, then $S$ contains exactly $k$ eigenvalues (counting multiplicities) of $A$, while $T$ contains exactly $n - k$ eigenvalues of $T$. (The proof of this depends on the fact that the zeros of the characteristic polynomial $p _ { n } ( z )$ vary continuously with the entries $a_{i,\,j}$ of $A$.)
One of the most beautiful results in this area, having to do with the sharpness of the inclusion of (a2), is a result of O. Taussky [a2], which depends on the following use of directed graphs (cf. also Graph, oriented). Given a complex $( n \times n )$-matrix $A = [ a_{i, j} ]$, with $n \geq 2$, let $\{ P _ { i } \} _ { i = 1 } ^ { n }$ be $n$ distinct points, called vertices, in the plane. Then, for each $a _ { i , j } \neq 0$, let $\overset{\rightharpoonup} { P _ { i } P _ { j } }$ denote an arc from vertex $i$ to vertex $j$. The collection of all these arcs defines the directed graph of $A$. Then the matrix $A = [ a_{i, j} ]$, with $n \geq 2$, is said to be irreducible if, given any distinct vertices $i$ and $j$, there is a sequence of abutting arcs from $i$ to $j$, i.e.,
\begin{equation*} \overrightarrow{ P _ { i } P _ { \text{l}_1 } } , \overrightarrow{ P _ { \text{l}_1 } P _ { \text{l}_2 } } , \dots , \overrightarrow{ P _ { \text{l}_m } P _ { \text{l}_{m+1} } }, \end{equation*}
where $\text{l} _ { m + 1 } = j $.
Taussky's theorem is this. Let $A = [ a_{i, j} ]$ be any irreducible complex $( n \times n )$-matrix, with $n \geq 2$. If $\lambda$ is an eigenvalue of $A$ which lies on the boundary of the union of the Gershgorin discs of (a2), then $\lambda$ lies on the boundary of each Gershgorin circle, i.e., from (a1) it follows that
\begin{equation*} | \lambda - a _ { i , i} | = r _ { i } ( A ) \text { for each } 1 \leq i \leq n. \end{equation*}
Next, there is related work of A. Brauer [a3] on estimating the eigenvalues of a complex $( n \times n )$-matrix ($n \geq 2$), which uses Cassini ovals instead of discs. For any integers $i$ and $j$ ($1 \leq i , j \leq n$) with $i \neq j$, the $( i , j )$th Cassini oval is defined by (cf. also Cassini oval)
\begin{equation} \tag{a4} K _ {i ,\, j } ( A ) : = \end{equation}
Then Brauer's theorem is that, for any eigenvalue $\lambda$ of $A$, there exist $i$ and $j$, with $i \neq j$, such that $\lambda \in K _ { i ,\, j } ( A )$, and this now gives the associated eigenvalue inclusion
\begin{equation} \tag{a5} \sigma ( A ) \subseteq \cup _ { i , j = 1 \atop i \neq j } ^ { n } K _ { i , j } ( A ). \end{equation}
Note that there are now $n ( n - 1 ) / 2$ such Cassini ovals in (a5), as opposed to the $n$ Gershgorin discs in (a2). But it is equally important to note that the eigenvalue inclusions of (a2) and (a5) use the exact same data from the matrix $A = [ a_{i, j} ]$, i.e., $\{ a_{i , i} \} _ { i = 1 } ^ { n }$ and $\{ r _ { i } ( A ) \} _ { i = 1 } ^ { n }$. So, which of the eigenvalue inclusions of (a2) and (a5) is smaller and hence better? It turns out that
\begin{equation} \tag{a6} \bigcup _ { i , j = 1 \atop i \neq j } ^ { n } K _ { i ,\, j} ( A ) \subseteq \bigcup _ { i = 1 } ^ { n } G _ { i } ( A ), \end{equation}
for any complex $( n \times n )$-matrix $A$, so that the Cassini ovals are always at least as good as the Gershgorin discs. (The result (a6) was known to Brauer, but was somehow neglected in the literature.)
Finally, as both eigenvalue inclusions (a2) and (a5) depend only on the row sums $r _ { i } ( A )$, it is evident that these inclusions apply not to just the single matrix $A$, but to a whole class of $( n \times n )$-matrices, namely,
\begin{equation*} \Omega ( A ) : = \end{equation*}
\begin{equation*} : = \{ B = [ b _ { i , j } ] : b _ { i , i } = a _ { i , i } , \text { and } r _ { i } ( B ) = r _ { i } ( A ) , 1 \leq i \leq n \}. \end{equation*}
Thus,
\begin{equation*} \sigma ( B ) \subseteq \cup _ { i , j = 1 \atop i \neq j } ^ { n } K _ { i ,\, j } ( A ) \subseteq \cup _ { i = 1 } ^ { n } G _ { i } ( A ) \end{equation*}
for each $B$ in $\Omega ( A )$. Then, if $\sigma ( \Omega ( A ) )$ denotes the set of all eigenvalues of all $B$ in $\Omega ( A )$, it follows that
\begin{equation} \tag{a7} \sigma ( \Omega ( A ) ) \subseteq \cup _ { i , j = 1 \atop j \neq j } ^ { n } K _ { i,\, j } ( A ) \subseteq \cup _ { i = 1 } ^ { n } G _ { i } ( A ). \end{equation}
How sharp is the first inclusion of (a7)? It was shown in 1999 by R.S. Varga and A. Krautstengl [a4] that
\begin{equation} \tag{a8} \sigma ( \Omega ( A ) ) = \left\{ \begin{array} { c c } { \text { boundary of } K _ { 1,2 } ( A ) } & { n = 2; } \\ { \cup _ { i ,\, j = 1 , i \neq j } ^ { n } K _ { i ,\, j } ( A ) } & { n \geq 3. } \end{array} \right. \end{equation}
Thus, for $n \geq 3$, it can be said that the Cassini ovals give "perfect" results.
Gershgorin's discs and Brauer's Cassini ovals are mentioned in [a5], [a6]. A more detailed treatment of these topics can be found in [a7].
References
| [a1] | S. Gerschgorin, "Ueber die Abgrenzung der Eigenwerte einer Matrix" Izv. Akad. Nauk. SSSR Ser. Mat. , 1 (1931) pp. 749–754 |
| [a2] | O. Taussky, "Bounds for the characteristic roots of matrices" Duke Math. J. , 15 (1948) pp. 1043–1044 |
| [a3] | A. Brauer, "Limits for the characteristic roots of a matrix" Duke Math. J. , 13 (1946) pp. 387–395 |
| [a4] | R.S. Varga, A. Krautstengl, "On Geršgorin-type problems and ovals of Cassini" Electron. Trans. Numer. Anal. , 8 (1999) pp. 15–20 |
| [a5] | R.S. Varga, "Matrix iterative analysis" , Springer (2000) (Edition: Second) |
| [a6] | R.A. Horn, C.R. Johnson, "Matrix analysis" , Cambridge Univ. Press (1985) |
| [a7] | R.S. Varga, "Geršgorin and his circles" , Springer (to appear) |