Mathematical theory of computation
The last twenty years have witnessed most vigorous growth in areas of mathematical study connected with computers and computer science. The enormous development of computers and the resulting profound changes in scientific methodology have opened new horizons for the science of mathematics at a speed without parallel during the long history of mathematics.
The following two observations should be kept in mind. First, various developments in mathematics have directly initiated the "beginning" of computers and computer science. Secondly, advances in computer science have induced very vigorous developments in certain branches of mathematics. More specifically, the second of these observations refers to the growing importance of discrete mathematics — and only the very beginning of the influence of discrete mathematics is witnessed now (1990).
Because of reasons outlined above, mathematics plays a central role in the foundations of computer science. A number of significant research areas can be listed in this connection. It is interesting to note that these areas also reflect the historical development of computer science.
1) The classical computability theory initiated by the work of K. Gödel, A. Tarski, A. Church, E. Post, A. Turing, and S.C. Kleene occupies a central position. This area is rooted in mathematical logic (cf. Computable function).
2) In classical formal language and automata theory, the central notions are those of an automaton, a grammar (cf., e.g., Grammar, generative), and a language (cf., e.g., Alphabet). Apart from developments in area 1), the work of N. Chomsky on the foundations of natural languages, as well as the work of Post concerning rewriting systems, should be mentioned here. It is, however, fascinating to observe that the modern theory of formal languages and rewriting systems was initiated by the work of the Norwegian mathematician A. Thue at the beginning of the 20th century! (Cf. Formal languages and automata;  -systems.)
-systems.)
3) An area initiated in the 1960s is complexity theory. In it the performance of an algorithm is investigated. The central notions are those of a tractable and an intractable problem. This area is gaining in importance because of several reasons, one of them being the advances in area 4). (Cf. Complexity theory; Algorithm, computational complexity of an.)
4) Quite recent developments concerning the security of computer systems have increased the importance of cryptography to a great extent. Moreover, the idea of public-key cryptography is of specific theoretical interest and has drastically changed the ideas concerning what is doable in communication systems. (Cf. Cryptography.)
Areas 1) through 4) constitute the core of the mathematical theory of computation. Many other important areas dealing with the mathematical foundations of computer science (e.g., semantics and the theory of correctness of programming languages, the theory of data structures, and the theory of data bases) have been developed.
All the areas listed above comprise a fascinating part of contemporary mathematics that is very dynamic in character, full of challenging problems requiring most interesting and ingenious mathematical techniques.
The basic question in the theory of computing can be formulated in any of the following ways: What is computable? For which problem can one construct effective mechanical procedures that solve every instance of the problem? Which problems possess algorithms for their solution?
Fundamental developments in mathematical logic during the 1930-s showed the existence of unsolvable problems: No algorithm can possibly exist for the solution of the problem. Thus, the existence of such an algorithm is a logical impossibility — its non-existence has nothing to do with ignorance. This state of affairs led to the present formulation of the basic question in the theory of computing. Previously, people always tried to construct an algorithm for every precisely formulated problem until (if ever) the correct algorithm was found. The basic question is of definite practical significance: One should not try to construct algorithms for an unsolvable problem. (There are some notorious examples of such attempts in the past.)
A model of computation is necessary for establishing unsolvability. If one wants to show that no algorithm for a specific problem exists, one must have a precise definition of an algorithm. The situation is different in establishing solvability: it suffices to exhibit some particular procedure that is effective in the intuitive sense. (The terms "algorithm" and "effective procedure" are used synonymously.)
One is now confronted with the necessity of formalizing a notion of a model of computation that is general enough to cover all conceivable computers, as well as the intuitive notion of an algorithm. Some initial observations are in order.
Assume that the algorithms that need formalization compute functions mapping the set of non-negative integers into the same set. Although this is not important at this point, one could observe that this assumption is no essential restriction of generality. This is due to the fact that other input and output formats can be encoded into non-negative integers.
After having somehow defined a general model of computation, denoted by  , one observes that each specific instance of the model possesses a finitary description; that is, it can be described in terms of a formula or finitely many words. By enumerating these descriptions, one obtains an enumeration
, one observes that each specific instance of the model possesses a finitary description; that is, it can be described in terms of a formula or finitely many words. By enumerating these descriptions, one obtains an enumeration  of all specific instances of the general model of computation. In this enumeration, each
of all specific instances of the general model of computation. In this enumeration, each  represents some particular algorithm for computing a function from non-negative integers into non-negative integers. Denote by
represents some particular algorithm for computing a function from non-negative integers into non-negative integers. Denote by  the value of the function computed by
the value of the function computed by  for the argument value
for the argument value  .
.
Define a function  by
by
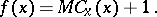 | (a1) |
Clearly, the following is an algorithm (in the intuitive sense) to compute the function  . Given an input
. Given an input  , start the algorithm
, start the algorithm 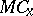 with the input
with the input  and add one to the output.
and add one to the output.
However, is there any specific algorithm among the formalized 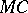 -models that would compute the function
-models that would compute the function 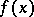 ? The answer is no, and the argument is an indirect one. Assume that
? The answer is no, and the argument is an indirect one. Assume that  would give rise to such an algorithm, where
would give rise to such an algorithm, where 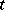 is some natural number. Hence, for all
is some natural number. Hence, for all  ,
,
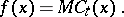 | (a2) |
A contradiction now arises by substituting the value 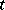 for the variable
for the variable  in both (a1) and (a2).
in both (a1) and (a2).
This contradiction, referred to as the dilemma of diagonalization, shows that independently of the model of computation — indeed, no  -model was specified — there will be algorithms not formalized by the model.
-model was specified — there will be algorithms not formalized by the model.
There is a simple and natural way to avoid the dilemma of diagonalization. So far the  -algorithms are assumed to be defined everywhere: For all inputs
-algorithms are assumed to be defined everywhere: For all inputs 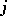 , the algorithm
, the algorithm  produces an output. This assumption is unreasonable from many points of view, one of which is computer programming; one cannot be sure that every program produces an output for every input. Therefore, one should allow also the possibility that some of the
produces an output. This assumption is unreasonable from many points of view, one of which is computer programming; one cannot be sure that every program produces an output for every input. Therefore, one should allow also the possibility that some of the  -algorithms enter an infinite loop for some inputs
-algorithms enter an infinite loop for some inputs  and, consequently, do not produce any output for such
and, consequently, do not produce any output for such  . Moreover, the set of such values
. Moreover, the set of such values  is not known a priori.
is not known a priori.
Thus, some algorithms in the list
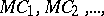 | (a3) |
produce an output only for some of the possible inputs; that is, the corresponding functions are not defined for all non-negative integers. The dilemma of diagonalization does not arise after the inclusion of such partial functions among the functions computed by the algorithms of (a3). Indeed, the argument presented above does not lead to a contradiction because  is not necessarily defined.
is not necessarily defined.
The general model of computation, now referred to as a Turing machine, was introduced quite a long time before the advent of electronic computers. Turing machines constitute by far the most widely-used general model of computation. Other general models are Markov algorithms (cf. Normal algorithm), Post systems (cf. Post canonical system), grammars, and  -systems. Each of these models leads to a list such as (a3), where partial functions are also included. All models are also equivalent in the sense that they define the same set of solvable problems or computable functions.
-systems. Each of these models leads to a list such as (a3), where partial functions are also included. All models are also equivalent in the sense that they define the same set of solvable problems or computable functions.
Only the general question of characterizing the class of solvable problems has been considered here. This question was referred to as basic in the theory of computing. It led to a discussion of general models of computation.
More specific questions in the theory of computing deal with the complexity of solvable problems. Is a problem  more difficult than
more difficult than  in the sense that every algorithm for
in the sense that every algorithm for 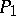 is more complex (for instance, in terms of time or memory space needed) than a reasonable algorithm for
is more complex (for instance, in terms of time or memory space needed) than a reasonable algorithm for  ? What is a reasonable classification of problems in terms of complexity? Which problems are so complex that they can be classified as intractable in the sense that all conceivable computers require an unmanageable amount of time for solving the problem?
? What is a reasonable classification of problems in terms of complexity? Which problems are so complex that they can be classified as intractable in the sense that all conceivable computers require an unmanageable amount of time for solving the problem?
Undoubtedly, such questions are of crucial importance from the point of view of practical computing. A problem is not yet settled if it is known to be solvable or computable and remains intractable at the same time. As a typical example, many recent results in cryptography are based on the assumption that the factorization of the product of two large primes is impossible in practice. More specifically, if one knows a large number  consisting of, for example, 200 digits and if one also knows that
consisting of, for example, 200 digits and if one also knows that  is the product of two large primes, it is still practically impossible, in general, to find the two primes. This assumption is reasonable because the problem described is intractable, at least in view of the factoring algorithms know at present. Of course, from a merely theoretical point of view where complexity is not considered, such a factoring algorithm can be trivially constructed.
is the product of two large primes, it is still practically impossible, in general, to find the two primes. This assumption is reasonable because the problem described is intractable, at least in view of the factoring algorithms know at present. Of course, from a merely theoretical point of view where complexity is not considered, such a factoring algorithm can be trivially constructed.
Such specific questions lead to more specific models of computing. The latter are obtained either by imposing certain restrictions on Turing machines or else by some direct construction. Of particular importance is the finite automaton (cf. also Automaton, finite). It is a model of a strictly finitary computing device: The automaton is not capable of increasing any of its resources during the computation.
It is clear that no model of computation is suitable for all situations; modifications and even entirely new models are needed to match new developments. Theoretical computer science by now has a history long enough to justify a discussion about good and bad models. The theory is mature enough to produce a great variety of different models of computation and prove some interesting properties concerning them. Good models should be general enough so that they are not too closely linked with any particular situation or problem in computing — they should be able to lead the way. On the other hand, they should not be too abstract. Restrictions on a good model should converge, step by step, to some area of real practical significance. Typical examples are certain restrictions of abstract grammars especially suitable for considerations concerning parsing. The resulting aspects of parsing are essential in compiler construction.
To summarize: A good model represents a well-balanced abstraction of a real practical situation — not too far from and not too close to the real thing.
Formal languages constitute a descriptive tool for models of computation, both in regard to input-output format and the mode of operation. Formal language theory is by its very essence an interdisciplinary area of science; the need for a formal grammatical description arises in various scientific disciplines, ranging from linguistics to biology.
References
| [a1] | A. Salomaa, "Formal languages" , Acad. Press (1973) |
| [a2] | G. Rozenberg, A. Salomaa, "The mathematical theory of  systems" , Acad. Press (1980) systems" , Acad. Press (1980) |
| [a3] | W. Kuich, A. Salomaa, "Semirings, automata, languages" , Springer (1986) |
| [a4] | A. Salomaa, "Computation and automata" , Cambridge Univ. Press (1985) |
Mathematical theory of computation. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Mathematical_theory_of_computation&oldid=15661