Formal languages and automata
Both natural and programming languages can be viewed as sets of sentences, that is, finite strings of elements from some basic vocabulary. The notion of a language introduced below is very general. It certainly includes both natural and programming languages and also all kinds of nonsense languages one might think of. Traditionally, formal language theory is concerned with the syntactic specification of a language rather than with any semantic issues. A syntactic specification of a language with finitely many sentences can be given, at least in principle, by listing the sentences. This is not possible for languages with infinitely many sentences. The main task of formal language theory is the study of finitary specifications of infinite languages.
The basic theory of computation, as well as of its various branches, such cryptography, is inseparably connected with language theory. The input and output sets of a computational device can be viewed as languages, and — more profoundly — models of computation can be identified with classes of language specifications, in a sense to be made more precise. Thus, for instance, Turing machines can be identified with phrase-structure grammars and finite automata with regular grammars (cf. also Turing machine; Automaton, finite; Grammar, formal).
Formal language theory is — together with automata theory, (cf. Automata, theory of) which is really inseparable from language theory — the oldest branch of theoretical computer science. In some sense, the role of language and automata theory in computer science is analogous to that of philosophy in general science: it constitutes the stem from which the individual branches of knowledge emerge.
An alphabet is a finite non-empty set. The elements of an alphabet 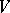 are called letters. A word over an alphabet
are called letters. A word over an alphabet 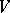 is a finite string of letters (cf. also Word). The word consisting of zero letters is called the empty word, written
is a finite string of letters (cf. also Word). The word consisting of zero letters is called the empty word, written 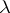 . The set of all words (respectively, all non-empty words) over an alphabet
. The set of all words (respectively, all non-empty words) over an alphabet 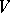 is denoted by
is denoted by 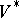 (respectively,
(respectively, 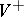 ). (Thus, algebraically
). (Thus, algebraically 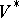 and
and 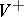 are the free monoid and free semi-group generated by the finite set
are the free monoid and free semi-group generated by the finite set 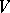 .) For words
.) For words 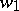 and
and 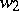 , the juxtaposition
, the juxtaposition 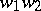 is called the catenation of
is called the catenation of 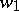 and
and 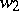 . The empty word
. The empty word 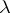 is an identity with respect to catenation. Catenation being associative, the notation
is an identity with respect to catenation. Catenation being associative, the notation 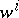 , where
, where 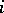 is a non-negative integer, is used in the customary sense, and
is a non-negative integer, is used in the customary sense, and 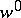 denotes the empty word. The length of a word
denotes the empty word. The length of a word 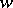 , in symbols
, in symbols 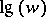 , also sometimes
, also sometimes  , means the number of letters in
, means the number of letters in 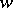 when each letter is counted as many times as it occurs. A word
when each letter is counted as many times as it occurs. A word 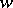 is a subword of a word
is a subword of a word  if and only if there are words
if and only if there are words 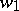 and
and 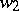 such that
such that 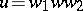 (cf. also Imbedded word). Subsets of
(cf. also Imbedded word). Subsets of 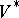 are referred to as (formal) languages over the alphabet
are referred to as (formal) languages over the alphabet 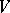 .
.
Various unary and binary operations defined for languages will be considered in the sequel. Regarding languages as sets, one may immediately define the Boolean operations of union, intersection, complementation (the complementation of a language 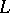 is denoted by
is denoted by 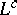 ), difference, and symmetric difference in the usual manner. The catenation (or product) of two languages
), difference, and symmetric difference in the usual manner. The catenation (or product) of two languages 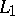 and
and 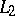 , in symbols
, in symbols 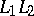 , is defined by
, is defined by
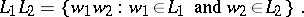 |
The notation 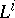 is extended to the catenation of languages. By definition
is extended to the catenation of languages. By definition 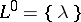 . The catenation closure or Kleene star (respectively,
. The catenation closure or Kleene star (respectively, 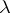 -free catenation closure) of a language
-free catenation closure) of a language 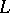 , in symbols
, in symbols 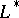 (respectively,
(respectively, 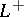 ), is defined to be the union of all non-negative powers of
), is defined to be the union of all non-negative powers of 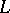 (respectively, the union of all positive powers of
(respectively, the union of all positive powers of 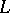 ).
).
The operation of substitution. For each letter  of an alphabet
of an alphabet 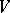 , let
, let 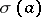 denote a language (possibly over a different alphabet). Define, furthermore,
denote a language (possibly over a different alphabet). Define, furthermore,
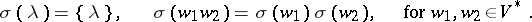 |
For a language 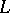 over
over 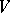 , one defines
, one defines
 |
Such a mapping 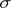 is called a substitution. A substitution
is called a substitution. A substitution 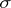 such that each
such that each 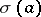 consists of a single word is called a homomorphism. (Algebraically, a homomorphism of languages is a homomorphism of monoids linearly extended to subsets of monoids.) In connection with homomorphisms (and also often elsewhere) one identifies a word
consists of a single word is called a homomorphism. (Algebraically, a homomorphism of languages is a homomorphism of monoids linearly extended to subsets of monoids.) In connection with homomorphisms (and also often elsewhere) one identifies a word 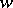 with the singleton set
with the singleton set 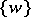 , writing
, writing 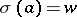 rather than
rather than 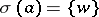 .
.
The main objects of study in formal language theory are finitary specifications of infinite languages. Most of such specifications are obtained as special cases from the notion of a rewriting system. By definition, a rewriting system is an ordered pair 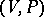 , where
, where 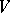 is an alphabet and
is an alphabet and 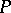 a finite set of ordered pairs of words over
a finite set of ordered pairs of words over 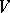 . The elements
. The elements 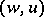 of
of 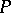 are referred to as rewriting rules or productions, and are denoted by
are referred to as rewriting rules or productions, and are denoted by  . Given a rewriting system, the yield relation
. Given a rewriting system, the yield relation 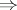 in the set
in the set 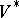 is defined as follows. For any two words
is defined as follows. For any two words 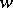 and
and  ,
, 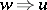 holds if and only if there are words
holds if and only if there are words 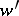 ,
, 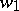 ,
,  ,
, 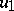 such that
such that 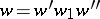 ,
, 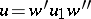 and
and 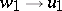 is a production in the system. The reflexive transitive closure (respectively, transitive closure) of the relation
is a production in the system. The reflexive transitive closure (respectively, transitive closure) of the relation 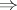 is denoted by
is denoted by 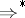 (respectively
(respectively 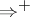 ).
).
A phrase-structure grammar, shortly a grammar, is an ordered quadruple 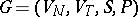 , where
, where 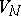 and
and 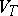 are disjoint alphabets (the alphabets of non-terminals and terminals),
are disjoint alphabets (the alphabets of non-terminals and terminals), 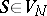 (the initial letter) and
(the initial letter) and 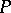 is a finite set of ordered pairs
is a finite set of ordered pairs 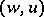 such that
such that  is a word over the alphabet
is a word over the alphabet 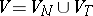 and
and 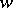 is a word over
is a word over 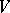 containing at least one letter of
containing at least one letter of 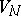 . Again, the elements of
. Again, the elements of 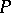 are referred to as rewriting rules or productions, and are written as
are referred to as rewriting rules or productions, and are written as  . A phrase-structure grammar
. A phrase-structure grammar 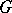 as above defines a rewriting system
as above defines a rewriting system 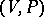 . Let
. Let 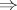 and
and 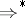 be the relations determined by this rewriting system. Then the language
be the relations determined by this rewriting system. Then the language 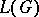 generated by
generated by 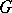 is defined by
is defined by
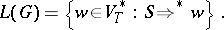 |
Two grammars 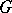 and
and 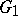 are termed equivalent if and only if
are termed equivalent if and only if 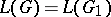 . For
. For 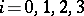 , a grammar
, a grammar 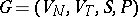 is of the type
is of the type 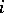 if and only if the restrictions
if and only if the restrictions 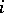 ) on
) on 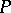 , as given below, are satisfied:
, as given below, are satisfied:
0) No restrictions.
1) Each production in 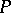 is of the form
is of the form 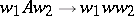 , where
, where 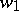 and
and 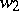 are arbitrary words,
are arbitrary words, 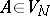 and
and 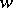 is a non-empty word (with the possible exception of the production
is a non-empty word (with the possible exception of the production 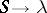 whose occurrence in
whose occurrence in 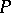 implies, however, that
implies, however, that 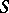 does not occur on the right-hand side of any production).
does not occur on the right-hand side of any production).
2) Each production in 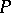 is of the form
is of the form 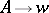 , where
, where 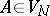 .
.
3) Each production is of one of the two forms 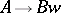 or
or 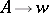 , where
, where 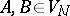 and
and  .
.
A language is of type  if and only if it is generated by a grammar of type
if and only if it is generated by a grammar of type 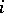 . Type-0 languages are also called recursively enumerable. Type-1 grammars and languages are also called context-sensitive. Type-2 grammars and languages are also called context-free. Type-3 grammars and languages are also referred to as finite-state or regular. (See also Grammar, context-sensitive; Grammar, context-free.)
. Type-0 languages are also called recursively enumerable. Type-1 grammars and languages are also called context-sensitive. Type-2 grammars and languages are also called context-free. Type-3 grammars and languages are also referred to as finite-state or regular. (See also Grammar, context-sensitive; Grammar, context-free.)
Type-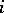 ,
, 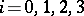 , languages form a strict hierarchy: the family of type-
, languages form a strict hierarchy: the family of type-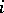 languages is strictly included in the family of type-
languages is strictly included in the family of type-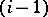 languages, for
languages, for 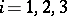 .
.
A specific context-free language over an alphabet with 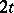 letters,
letters, 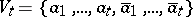 ,
, 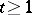 , is the Dyck language generated by the grammar
, is the Dyck language generated by the grammar
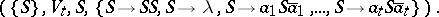 |
The Dyck language consists of all words over 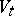 that can be reduced to
that can be reduced to 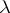 using the relations
using the relations 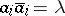 ,
, 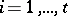 . If the pairs
. If the pairs 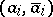 ,
, 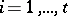 , are viewed as parentheses of different types, then the Dyck language consists of all sequences of correctly nested parentheses.
, are viewed as parentheses of different types, then the Dyck language consists of all sequences of correctly nested parentheses.
The family of regular languages over an alphabet 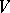 equals the family of languages obtained from "atomic languages"
equals the family of languages obtained from "atomic languages" 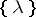 and
and 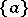 , where
, where 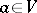 , by a finite number of applications of "regular operations" : union, catenation and catenation closure. The formula expressing how a specific regular language is obtained from atomic languages by regular operations is termed a regular expression.
, by a finite number of applications of "regular operations" : union, catenation and catenation closure. The formula expressing how a specific regular language is obtained from atomic languages by regular operations is termed a regular expression.
Every context-free language which is 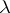 -free (i.e., does not contain the empty word) is generated by a grammar in Chomsky normal form, as well as by a grammar in Greibach normal form. In the former, all productions are of the types
-free (i.e., does not contain the empty word) is generated by a grammar in Chomsky normal form, as well as by a grammar in Greibach normal form. In the former, all productions are of the types 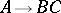 ,
, 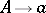 , and in the latter — of the types
, and in the latter — of the types 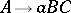 ,
, 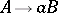 ,
, 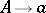 , where capital letters denote non-terminals and
, where capital letters denote non-terminals and  is a terminal letter. According to the theorem of Chomsky–Schützenberger, every context-free language
is a terminal letter. According to the theorem of Chomsky–Schützenberger, every context-free language 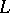 can be expressed as
can be expressed as
 |
for some regular language 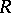 , Dyck language
, Dyck language 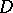 and homomorphism
and homomorphism 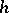 . According to the Lemma of Bar-Hillel (also called the pumping lemma), every sufficiently long word
. According to the Lemma of Bar-Hillel (also called the pumping lemma), every sufficiently long word 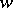 in a context-free language
in a context-free language 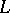 can be written in the form
can be written in the form
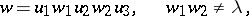 |
where for every  the word
the word 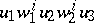 belongs to
belongs to 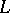 . For regular languages, the corresponding result reads as follows: Every sufficiently long word
. For regular languages, the corresponding result reads as follows: Every sufficiently long word 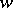 in a regular language
in a regular language 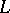 can be written in the form
can be written in the form 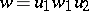 ,
, 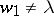 , where for every
, where for every 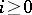 the word
the word 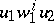 belongs to
belongs to 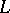 .
.
Derivations according to a context-free grammar (i.e., finite sequences of words where every two consecutive words are in the relation 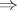 ) can in a natural way be visualized as labelled trees, the so-called derivation trees (cf. also Derivation tree). A context-free grammar
) can in a natural way be visualized as labelled trees, the so-called derivation trees (cf. also Derivation tree). A context-free grammar 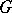 is termed ambiguous if and only if some word in
is termed ambiguous if and only if some word in  has two derivation trees. Otherwise,
has two derivation trees. Otherwise, 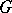 is termed unambiguous. A context-free language
is termed unambiguous. A context-free language 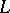 is unambiguous if and only if
is unambiguous if and only if 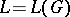 for some unambiguous grammar
for some unambiguous grammar 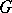 . Otherwise,
. Otherwise, 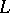 is termed (inherently) ambiguous. One also speaks of degrees of ambiguity. A context-free grammar
is termed (inherently) ambiguous. One also speaks of degrees of ambiguity. A context-free grammar 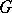 is ambiguous of degree
is ambiguous of degree 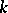 (a natural number or
(a natural number or 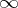 ) if and only if every word in
) if and only if every word in 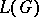 possesses at most
possesses at most 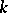 derivation trees and some word in
derivation trees and some word in 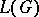 possesses exactly
possesses exactly 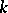 derivation trees. A language
derivation trees. A language  is ambiguous of degree
is ambiguous of degree 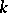 if and only if
if and only if 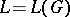 for some
for some 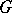 ambiguous of degree
ambiguous of degree 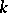 , and there is no
, and there is no 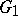 ambiguous of degree less than
ambiguous of degree less than 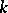 such that
such that 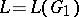 .
.
The families of type-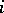 languages,
languages, 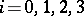 , defined above using generative devices, can be obtained also by recognition devices. A recognition device defining a language
, defined above using generative devices, can be obtained also by recognition devices. A recognition device defining a language 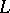 receives arbitrary words as inputs and "accepts" exactly the words belonging to
receives arbitrary words as inputs and "accepts" exactly the words belonging to 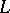 . The recognition devices finite and pushdown automata, corresponding to type-3 and type-2 languages, will be defined below. The definitions of the recognition devices linear bounded automata and Turing machines, corresponding to type-1 and type-0 languages, are analogous. (Cf. Computable function; Complexity theory.)
. The recognition devices finite and pushdown automata, corresponding to type-3 and type-2 languages, will be defined below. The definitions of the recognition devices linear bounded automata and Turing machines, corresponding to type-1 and type-0 languages, are analogous. (Cf. Computable function; Complexity theory.)
A rewriting system 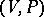 is called a finite deterministic automaton if and only if: a)
is called a finite deterministic automaton if and only if: a) 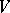 is divided into two disjoint alphabets
is divided into two disjoint alphabets 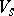 and
and 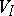 (the state and the input alphabet); b) an element
(the state and the input alphabet); b) an element 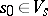 and a subset
and a subset  are specified (initial state and final state set); and c) the productions in
are specified (initial state and final state set); and c) the productions in 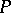 are of the form
are of the form
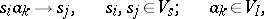 |
and for each pair 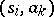 there is exactly one such production in
there is exactly one such production in 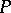 .
.
A finite deterministic automaton over an input alphabet 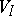 is usually defined by specifying an ordered quadruple
is usually defined by specifying an ordered quadruple 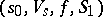 , where
, where  is a mapping of
is a mapping of 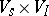 into
into 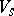 , the other items being as above. (Clearly, the values of
, the other items being as above. (Clearly, the values of 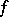 are obtained from the right-hand sides of the productions listed above.)
are obtained from the right-hand sides of the productions listed above.)
The language accepted or recognized by a finite deterministic automaton 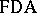 is defined by
is defined by
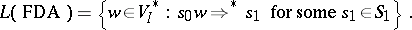 |
A finite non-deterministic automaton 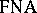 is defined as a finite deterministic automaton with the following two exceptions. In b)
is defined as a finite deterministic automaton with the following two exceptions. In b) 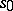 is replaced by a subset
is replaced by a subset 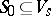 . In c) the second half of the sentence (beginning with "and" ) is omitted. The language accepted by an
. In c) the second half of the sentence (beginning with "and" ) is omitted. The language accepted by an 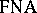 is defined by
is defined by
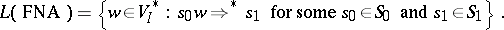 |
A language is of type 3 if and only if it is accepted by some finite deterministic automaton and if and only if it is accepted by some finite non-deterministic automaton.
A rewriting system  is called a pushdown automaton if and only if each of the following conditions 1)–3) is satisfied.
is called a pushdown automaton if and only if each of the following conditions 1)–3) is satisfied.
1) 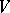 is divided into two disjoint alphabets
is divided into two disjoint alphabets 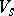 and
and 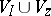 . The sets
. The sets 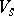 ,
,  and
and 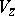 are called the state, input and pushdown alphabet, respectively. The sets
are called the state, input and pushdown alphabet, respectively. The sets 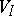 and
and 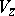 are non-empty but not necessarily disjoint.
are non-empty but not necessarily disjoint.
2) Elements 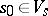 ,
, 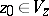 and a subset
and a subset 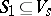 are specified, namely, the so-called initial state, start letter and final state set.
are specified, namely, the so-called initial state, start letter and final state set.
3) The productions in 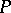 are of the two forms
are of the two forms
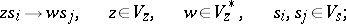 | (a1) |
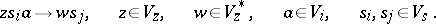 | (a2) |
The language accepted by a pushdown automaton 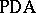 is defined by
is defined by
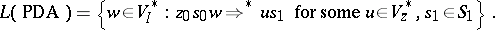 |
A pushdown automaton is deterministic if and only if, for every pair 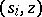 ,
, 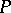 contains either exactly one production (a1) and no productions (a2), or no productions (a1) and exactly one production (a2) for every
contains either exactly one production (a1) and no productions (a2), or no productions (a1) and exactly one production (a2) for every 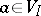 .
.
The family of context-free languages equals the family of languages accepted by pushdown automata. Languages accepted by deterministic pushdown automata are referred to as deterministic (context-free) languages. The role of determinism is different in connection with pushdown and finite automata: the family of deterministic languages is a proper subfamily of the family of context-free languages.
The automata considered above have no other output facilities than being or not being in a final state, i.e., they are only capable of accepting or rejecting inputs. Occasionally devices (transducers) capable of having words as outputs, i.e., capable of translating words into words, are considered. A formal definition is given below only for the transducer corresponding to a finite automaton. A pushdown transducer is defined analogously.
A rewriting system 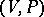 is called a sequential transducer if and only if each of the following conditions 1)–3) is satisfied.
is called a sequential transducer if and only if each of the following conditions 1)–3) is satisfied.
1) 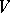 is divided into two disjoint alphabets
is divided into two disjoint alphabets 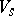 and
and 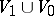 . The sets
. The sets 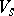 ,
, 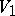 ,
, 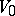 are called the state, input and output alphabet, respectively. (The two latter alphabets are non-empty but not necessarily disjoint.)
are called the state, input and output alphabet, respectively. (The two latter alphabets are non-empty but not necessarily disjoint.)
2) An element 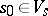 and a subset
and a subset 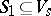 are specified (initial state and final state set).
are specified (initial state and final state set).
3) The productions in 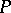 are of the form
are of the form
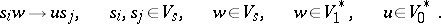 |
If, in addition, 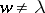 in all productions, then the rewriting system is called a generalized sequential machine (gsm).
in all productions, then the rewriting system is called a generalized sequential machine (gsm).
For a sequential transducer  , words
, words 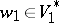 and
and 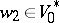 , and languages
, and languages 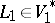 and
and  , one defines
, one defines
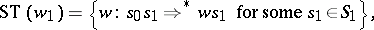 |
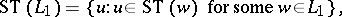 |
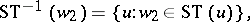 |
 |
Mappings of languages thus defined are referred to as (rational) transductions and inverse (rational) transductions. If  is also a gsm, one speaks of gsm mappings and inverse gsm mappings.
is also a gsm, one speaks of gsm mappings and inverse gsm mappings.
Homomorphisms, inverse homomorphisms and the mappings 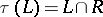 , where
, where 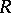 is a fixed regular language, are all rational transductions, the first and the last being also gsm mappings. The composite of two rational transductions (respectively, gsm mappings) is again a rational transduction (respectively, a gsm mapping). Every rational transduction
is a fixed regular language, are all rational transductions, the first and the last being also gsm mappings. The composite of two rational transductions (respectively, gsm mappings) is again a rational transduction (respectively, a gsm mapping). Every rational transduction  can be expressed in the form
can be expressed in the form
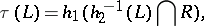 |
where 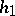 and
and 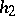 are homomorphisms and
are homomorphisms and 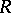 is a regular language. These results show that a language family is closed under rational transductions if and only if it is closed under homomorphisms, inverse homomorphisms and intersections with regular languages.
is a regular language. These results show that a language family is closed under rational transductions if and only if it is closed under homomorphisms, inverse homomorphisms and intersections with regular languages.
A finite probabilistic automaton (or stochastic automaton, cf. Automaton, probabilistic) is an ordered quintuple
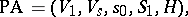 |
where 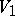 and
and 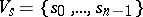 are disjoint alphabets (inputs and states),
are disjoint alphabets (inputs and states), 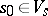 and
and 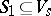 (initial state and final state set), and
(initial state and final state set), and 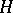 is a mapping of
is a mapping of 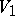 into the set of
into the set of  -dimensional stochastic matrices. (A stochastic matrix is a square matrix with non-negative real entries and with row sums equal to 1.) The mapping
-dimensional stochastic matrices. (A stochastic matrix is a square matrix with non-negative real entries and with row sums equal to 1.) The mapping 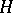 is extended to a homomorphism of
is extended to a homomorphism of 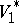 into the monoid of
into the monoid of  -dimensional stochastic matrices. Consider
-dimensional stochastic matrices. Consider 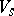 to be an ordered set as indicated, let
to be an ordered set as indicated, let 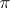 be the
be the  -dimensional stochastic row vector whose first component equals 1, and let
-dimensional stochastic row vector whose first component equals 1, and let 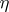 be the
be the  -dimensional column vector consisting of 0's and 1's such that the
-dimensional column vector consisting of 0's and 1's such that the 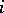 -th component of
-th component of 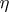 equals 1 if and only if the
equals 1 if and only if the 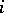 -th element of
-th element of 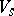 belongs to
belongs to 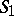 . The language accepted by a
. The language accepted by a 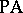 with cut-point
with cut-point 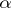 , where
, where 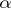 is a real number satisfying
is a real number satisfying 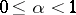 , is defined by
, is defined by
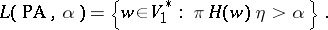 |
Languages obtained in this fashion are referred to as stochastic languages.
Decision problems (cf. Decision problem) play an important role in language theory. The usual method of proving that a problem is undecidable is to reduce it to some problem whose undecidability is known. The most useful tool for problems in language theory is in this respect the Post correspondence problem. By definition, a Post correspondence problem is an ordered quadruple 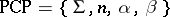 , where
, where 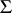 is an alphabet,
is an alphabet, 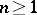 , and
, and 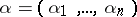 ,
, 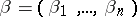 are ordered
are ordered  -tuples of elements of
-tuples of elements of 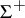 . A solution to the
. A solution to the 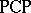 is a non-empty finite sequence of indices
is a non-empty finite sequence of indices 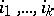 such that
such that
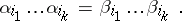 |
It is undecidable whether an arbitrary given 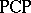 (or an arbitrary given
(or an arbitrary given 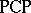 over the alphabet
over the alphabet 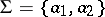 ) has a solution.
) has a solution.
Also Hilbert's tenth problem is undecidable: Given a polynomial 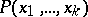 with integer coefficients, one has to decide whether or not there are non-negative integers
with integer coefficients, one has to decide whether or not there are non-negative integers 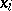 ,
, 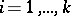 , satisfying the equation
, satisfying the equation
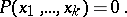 |
The membership problem is decidable for context-sensitive languages but undecidable for type-0 languages. (More specifically, given a context-sensitive grammar 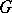 and a word
and a word 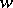 , it is decidable whether or not
, it is decidable whether or not  .) It is decidable whether two given regular languages are equal and also whether one of them is contained in the other. Both of these problems (the equivalence problem and the inclusion problem) are undecidable for context-free languages. It is also undecidable whether a given regular and a given context-free language is empty or infinite, whereas both of these problems are undecidable for context-sensitive languages. It is undecidable whether the intersection of two context-free languages is empty. The intersection of a context-free and a regular language is always context-free; and, hence, its emptiness is decidable. It is undecidable whether a given context-free language is regular.
.) It is decidable whether two given regular languages are equal and also whether one of them is contained in the other. Both of these problems (the equivalence problem and the inclusion problem) are undecidable for context-free languages. It is also undecidable whether a given regular and a given context-free language is empty or infinite, whereas both of these problems are undecidable for context-sensitive languages. It is undecidable whether the intersection of two context-free languages is empty. The intersection of a context-free and a regular language is always context-free; and, hence, its emptiness is decidable. It is undecidable whether a given context-free language is regular.
The following example is due to M. Soittola. Consider the grammar 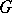 determined by the productions
determined by the productions
 |
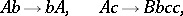 |
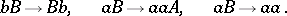 |
Then
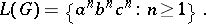 |
In fact, any derivation according to 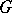 begins with an application of the first or second production, the first production directly yielding the terminal word
begins with an application of the first or second production, the first production directly yielding the terminal word 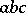 . Consider any derivation
. Consider any derivation  from a word
from a word 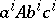 , where
, where 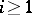 , leading to a word over the terminal alphabet.
, leading to a word over the terminal alphabet. 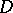 must begin with
must begin with  applications of the third production (
applications of the third production (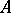 travels to the right) and then continue with an application of the fourth production (one further occurrence of
travels to the right) and then continue with an application of the fourth production (one further occurrence of 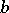 and
and  is deposited). Now the word
is deposited). Now the word 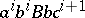 has been derived. For this the only possibility is to apply the fifth production
has been derived. For this the only possibility is to apply the fifth production 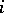 times (
times (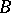 travels to the left), after which one obtains the word
travels to the left), after which one obtains the word 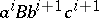 . This word directly yields one of the two words
. This word directly yields one of the two words
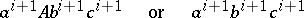 |
by the last two productions (one further  is deposited, and either a new cycle is entered or the derivation is terminated). This argument shows that
is deposited, and either a new cycle is entered or the derivation is terminated). This argument shows that 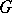 generates all words belonging to the language and nothing else; every step in a derivation is uniquely determined, the only exception being that there is a choice between termination and entrance into a new cycle.
generates all words belonging to the language and nothing else; every step in a derivation is uniquely determined, the only exception being that there is a choice between termination and entrance into a new cycle.
References
| [a1] | N. Chomsky, "Three models for the description of language" IRE Trans. Information Theory , IT-2 (1956) pp. 113–124 |
| [a2] | N. Chomsky, "Syntactic structures" , Mouton (1957) |
| [a3] | M. Davis, "Computability and unsolvability" , McGraw-Hill (1958) |
| [a4] | S. Eilenberg, "Automata, languages and machines" , A , Acad. Press (1974) |
| [a5] | D. Hilbert, "Mathematische Probleme. Vortrag, gehalten auf dem internationalen Mathematiker-Kongress zu Paris, 1900" , Gesammelte Abhandlungen , III , Springer (1935) |
| [a6] | S.C. Kleene, "Representation of events in nerve nets and finite automata" , Automata studies , 34 , Princeton Univ. Press (1956) pp. 3–42 |
| [a7] | A. Paz, "Introduction to probabilistic automata" , Acad. Press (1971) |
| [a8] | E.L. Post, "A variant of a recursively unsolvable problem" Bull. Amer. Math. Soc. , 52 (1946) pp. 264–268 |
| [a9] | H. Rogers jr., "Theory of recursive functions and effective computability" , McGraw-Hill (1967) pp. 164–165 |
| [a10] | G. Rozenberg, "Selective substitution grammars" Elektronische Informationsverarbeitung und Kybernetik (EIK) , 13 (1977) pp. 455–463 |
| [a11] | A. Salomaa, "Theory of automata" , Pergamon (1969) |
| [a12] | A. Salomaa, "Formal languages" , Acad. Press (1973) |
| [a13] | A. Salomaa, "Jewels of formal language theory" , Computer Science Press (1981) |
| [a14] | A. Salomaa, M. Soittola, "Automata-theoretic aspects of formal power series" , Springer (1978) |
| [a15] | A. Thue, "Ueber unendliche Zeichenreihen" Skrifter utgit av Videnskapsselskapet i Kristiania , I (1906) pp. 1–22 |
| [a16] | A. Thue, "Probleme über Veränderungen von Zeichenreihen nach gegebenen Regeln" Skrifter utgit av Videnskapsselskapet i Kristiania , I.10 (1914) |
| [a17] | A.M. Turing, "On computable numbers, with an application to the Entscheidungsproblem" Proc. London Math. Soc. , 42 (1936) pp. 230–265 |
Formal languages and automata. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Formal_languages_and_automata&oldid=44374