Complexity theory
The classification of mathematical problems into decidable and undecidable ones is a most fundamental one. It is also of definite practical significance in discouraging attempts to design too-general systems, such as systems for deciding the equivalence of programs or the halting of a program.
However, this classification is too coarse in many respects. A finer classification of decidable problems in terms of their complexity is discussed below. Two problems might both be decidable and yet one might be enormously more difficult to compute, which in practice might make this problem resemble an undecidable one. For example, if instances of reasonable size of one problem take only a few seconds to compute, whereas instances of comparable size of the other problem take millions of years (even if best computers are available), it is clear that the latter problem should be considered intractable compared with the former one. Hence, having established the decidability of a particular problem, one should definitely study its complexity — that is, how difficult it is to settle specific instances of the problem. Complexity considerations are of crucial importance, for instance, in cryptography. If one is not able to decrypt a message within a certain time limit, one might as well forget the whole thing because, as time passes by, the situation might change entirely. Related material is discussed also in the article Algorithm, computational complexity of an.
Thus, typical questions in the theory of computational complexity would be: Is the algorithm  better than the algorithm
better than the algorithm  (for the same problem) in the sense that it uses fewer resources, such as time or memory space? Does the problem
(for the same problem) in the sense that it uses fewer resources, such as time or memory space? Does the problem  have a best algorithm? Is the problem
have a best algorithm? Is the problem  more difficult than the problem
more difficult than the problem  in the sense that every algorithm for solving
in the sense that every algorithm for solving  is more complex than some fixed reasonable algorithm for solving
is more complex than some fixed reasonable algorithm for solving  ?
?
Natural complexity measures are obtained by considering Turing machines (cf. Turing machine): How many steps (in terms of the length of the input) does a computation require? This is a natural formalization of the notion of time resource. Similarly, the number of squares visited during a computation constitutes a natural space measure. (Cf. Formal languages and automata and Computable function.)
Such machine-oriented complexity considerations will be considered in the second half of this article. The discussion will be restricted to the basic Turing-machine model. Variations such as machines with many tapes and many heads or random-access machines are important in more detailed and specific complexity considerations. However, from the point of view of the most fundamental issues, the particular Turing-machine model chosen is irrelevant.
In the first half of this article, axiomatic complexity theory is being studied. No specific complexity measure, such as time or memory space, will be defined. Instead, "abstract resource" used by an algorithm will be the term employed. The axioms applied are very natural. They also look very weak in the sense that they do not say much. However, quite a remarkable theory based on the axioms can be established. The theory was initial in [a1].
The third major aspect of complexity theory is not discussed at all: low-level complexity, or the complexity of some specific but practically important algorithms and problems. One is referred to [a5]–[a7] for this topic, as well as for more detailed information of the broad and highly developed area of complexity theory in general.
Consider an enumeration
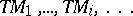 | (a1) |
of all Turing machines. Enumeration (a1) determines an enumeration
 | (a2) |
of all partial recursive functions of one variable (cf. Partial recursive function). An enumeration
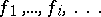 | (a3) |
of all partial recursive functions of one variable is termed acceptable if and only if it is possible to go effectively from (a2) to (a3), and vice versa. In other words, given an index for a function in (a2), one can find an index for the same function in (a3), and vice versa.
A complexity measure is a pair 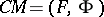 , where
, where  is an acceptable enumeration (a3) of partial recursive functions and
is an acceptable enumeration (a3) of partial recursive functions and 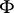 is an infinite sequence
is an infinite sequence
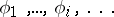 | (a4) |
of partial recursive functions such that the Blum axioms B1 and B2 are satisfied.
B1. For each 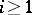 , the domains of
, the domains of 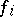 and
and 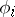 coincide.
coincide.
B2. The function 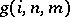 defined by
defined by
 |
is recursive.
The function  is referred to as the complexity function, or cost function, of
is referred to as the complexity function, or cost function, of 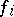 .
.
For instance, if one chooses  to be the number of steps in the computation of a Turing machine for
to be the number of steps in the computation of a Turing machine for 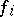 for the input
for the input  , one clearly obtains a complexity measure. Similarly, a complexity measure results if one lets
, one clearly obtains a complexity measure. Similarly, a complexity measure results if one lets 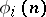 be the number of squares visited during the computation of the same Turing machine for the input
be the number of squares visited during the computation of the same Turing machine for the input  , provided such a variant of Turing machines is considered where no machines loops using only a finite amount of tape.
, provided such a variant of Turing machines is considered where no machines loops using only a finite amount of tape.
On the other hand, the choice 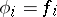 does not yield a complexity measure: Axiom B2 is not satisfied. The choice
does not yield a complexity measure: Axiom B2 is not satisfied. The choice 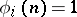 for all
for all 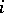 and
and  does not yield a complexity measure because axiom B1 is not satisfied. These examples also show that the two axioms are independent.
does not yield a complexity measure because axiom B1 is not satisfied. These examples also show that the two axioms are independent.
Clearly, every partial recursive function  occurs infinitely many times in the sequence (a3). If
occurs infinitely many times in the sequence (a3). If  , then the cost function
, then the cost function  is associated to an algorithm (for instance, a Turing machine) for computing
is associated to an algorithm (for instance, a Turing machine) for computing 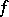 , rather than to the function
, rather than to the function  itself. If
itself. If  as well, then the cost function
as well, then the cost function 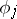 might have essentially smaller values than
might have essentially smaller values than  , showing that the algorithm corresponding to
, showing that the algorithm corresponding to  is essentially better. When and how is such a speedup possible? This question of speedup is one of the most interesting ones in complexity theory.
is essentially better. When and how is such a speedup possible? This question of speedup is one of the most interesting ones in complexity theory.
No matter what complexity measure and amount of speedup one considers, there are recursive functions 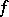 such that an arbitrary algorithm for
such that an arbitrary algorithm for 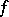 can be sped up by that amount. Suppose
can be sped up by that amount. Suppose  and consider the algorithm determined by
and consider the algorithm determined by 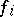 (for instance, the Turing machine
(for instance, the Turing machine  ) to be a particularly efficient one. This means that one regards the amount of resource defined by
) to be a particularly efficient one. This means that one regards the amount of resource defined by 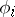 to be particularly small, in view of the complexity of the function
to be particularly small, in view of the complexity of the function  . Suppose, further, that
. Suppose, further, that  is a very rapidly increasing function, for instance,
is a very rapidly increasing function, for instance,
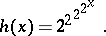 |
Then there is another algorithm for 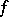 using so much less resource as
using so much less resource as  indicates. In other words, one has also
indicates. In other words, one has also  and
and
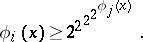 |
However, this does not necessarily hold for all  , but only almost-everywhere. Of course, the same procedure can be repeated for
, but only almost-everywhere. Of course, the same procedure can be repeated for 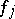 . This gives rise to another speedup, but now
. This gives rise to another speedup, but now 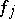 is the algorithm using "much" resource. The speedup can be repeated again for the resulting function, etc. ad infinitum.
is the algorithm using "much" resource. The speedup can be repeated again for the resulting function, etc. ad infinitum.
Thus, the speedup theorem implies that some functions  have no best algorithms: For every person's favourite algorithm
have no best algorithms: For every person's favourite algorithm 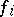 , a speedup is possible. However, this is only true for some functions
, a speedup is possible. However, this is only true for some functions  that might be considered "unnatural" .
that might be considered "unnatural" .
Now machine-oriented complexity theory is considered. Consider a Turing machine 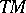 that halts with all inputs
that halts with all inputs 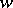 . The time-complexity function associated with
. The time-complexity function associated with  is defined by
is defined by
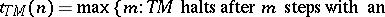 |
 |
Thus 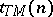 maps the set of non-negative integers into itself. One says that
maps the set of non-negative integers into itself. One says that 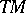 is polynomial bounded if and only if there is a polynomial
is polynomial bounded if and only if there is a polynomial 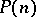 such that
such that  holds for all
holds for all  . Denote by
. Denote by 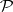 the family of languages acceptable by polynomially-bounded Turing machines. (So far only deterministic Turing machines have been considered — non-deterministic ones are introduced later.)
the family of languages acceptable by polynomially-bounded Turing machines. (So far only deterministic Turing machines have been considered — non-deterministic ones are introduced later.)
Although  is defined as a family of languages, it can be visualized as the collection of problems for which there exists an algorithm operating in polynomial time. One can always identify a decision problem with the membership problem for the language of "positive instances" .
is defined as a family of languages, it can be visualized as the collection of problems for which there exists an algorithm operating in polynomial time. One can always identify a decision problem with the membership problem for the language of "positive instances" .
The family 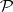 is very natural from a mathematical point of view. This is seen from the fact that it is highly invariant with respect to the underlying model of computation. For instance, Turing machines
is very natural from a mathematical point of view. This is seen from the fact that it is highly invariant with respect to the underlying model of computation. For instance, Turing machines  with several tapes are faster than ordinary Turing machines — that is, their time-complexity function assumes smaller values. However, if the time-complexity function of such a
with several tapes are faster than ordinary Turing machines — that is, their time-complexity function assumes smaller values. However, if the time-complexity function of such a 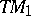 is bounded from above by a polynomial
is bounded from above by a polynomial  , one can (effectively) construct an ordinary Turing machine
, one can (effectively) construct an ordinary Turing machine  with a polynomial bound
with a polynomial bound 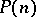 accepting the same language as
accepting the same language as  . (In general,
. (In general, 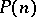 assumes greater values than
assumes greater values than 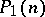 but is still a polynomial.) Similarly, every language that is polynomially bounded with respect to any reasonable model of computation belongs to the family
but is still a polynomial.) Similarly, every language that is polynomially bounded with respect to any reasonable model of computation belongs to the family  , as defined above with respect to the ordinary Turing machine.
, as defined above with respect to the ordinary Turing machine.
The family  is also of crucial importance because languages outside
is also of crucial importance because languages outside 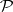 can be visualized as impossible to compute. In fact, one says that a recursive language is intractable if it does not belong to
can be visualized as impossible to compute. In fact, one says that a recursive language is intractable if it does not belong to  .
.
Clearly, languages outside  are intractable from the practical point of view. The same can be said about such languages in
are intractable from the practical point of view. The same can be said about such languages in 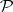 for which the polynomial bound is a huge one. However, it would not be natural to draw the borderline between tractability and intractability somewhere inside
for which the polynomial bound is a huge one. However, it would not be natural to draw the borderline between tractability and intractability somewhere inside  . Such a definition would also be time-varying: Drastic developments in computers could change it. On the other hand, the family
. Such a definition would also be time-varying: Drastic developments in computers could change it. On the other hand, the family 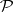 provides a very natural characterization of tractability.
provides a very natural characterization of tractability.
Now non-deterministic Turing machines are considered: When scanning a specific symbol in a specific state, the machine may have several possibilities for its behaviour. Otherwise, a non-deterministic machine is defined as a deterministic one. A word 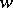 is accepted if and only if it gives rise to an accepting computation, independently of the fact that it might also give rise to computations leading to failure. Thus, in connection with non-deterministic machines in general, all roads to failure are disregarded if there is one possible road to success.
is accepted if and only if it gives rise to an accepting computation, independently of the fact that it might also give rise to computations leading to failure. Thus, in connection with non-deterministic machines in general, all roads to failure are disregarded if there is one possible road to success.
The time required by a non-deterministic Turing machine 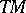 to accept a word
to accept a word  is defined to be the number of steps in the shortest computation of
is defined to be the number of steps in the shortest computation of  accepting
accepting  . The time-complexity function of
. The time-complexity function of 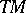 is now defined by
is now defined by
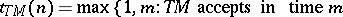 |
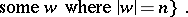 |
Thus, only accepting computations enter the definition of 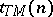 . If no words of length
. If no words of length  are accepted,
are accepted,  .
.
Further formal details of the definition of a non-deterministic Turing machine are omitted.
Having defined the time-complexity function, the notion of a polynomially-bounded non-deterministic Turing machine is defined exactly as before. Denote by 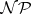 the family of languages acceptable by non-deterministic polynomially-bounded Turing machines.
the family of languages acceptable by non-deterministic polynomially-bounded Turing machines.
Problems in  are tractable, whereas problems in
are tractable, whereas problems in 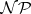 have the property that it is tractable to check whether or not a good guess for the solution of the problem is correct. A non-deterministic Turing machine may be visualized as a device that checks whether or not a guess is correct: It makes a guess (or several guesses) at some stage during its computation, and the final outcome is acceptance only in case the guess was (or the guesses were) correct. Thus, a time bound for a non-deterministic Turing machine is, in fact, a time bound for checking whether or not a guess for the solution is correct.
have the property that it is tractable to check whether or not a good guess for the solution of the problem is correct. A non-deterministic Turing machine may be visualized as a device that checks whether or not a guess is correct: It makes a guess (or several guesses) at some stage during its computation, and the final outcome is acceptance only in case the guess was (or the guesses were) correct. Thus, a time bound for a non-deterministic Turing machine is, in fact, a time bound for checking whether or not a guess for the solution is correct.
Clearly, 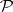 is contained in
is contained in  . However, it is not known whether or not the containment is proper. The problem of whether or not
. However, it is not known whether or not the containment is proper. The problem of whether or not 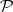 equals
equals  (
(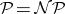 ?) can justly be called the most celebrated open problem in the theory of computation. The significance of this question is due to the fact that many practically important problems are known to be in
?) can justly be called the most celebrated open problem in the theory of computation. The significance of this question is due to the fact that many practically important problems are known to be in 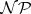 , whereas it is not known whether or not they are in
, whereas it is not known whether or not they are in 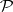 . In fact, all known deterministic algorithms for these problems are exponential as far as time is concerned. Thus, a proof of
. In fact, all known deterministic algorithms for these problems are exponential as far as time is concerned. Thus, a proof of 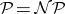 would make all of these problems tractable.
would make all of these problems tractable.
Non-deterministic Turing machines and guessing are not, as such, intended to be modeling computation. Non-determinism is merely an auxiliary notion and, as will be seen, a very useful one. Indeed, if one wants to settle the question of whether or not  , the following definitions and results show that it suffices to consider one particular language (might be a favourite one!) and determine whether or not it is in
, the following definitions and results show that it suffices to consider one particular language (might be a favourite one!) and determine whether or not it is in 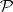 . There is a great variety of such so-called
. There is a great variety of such so-called  -complete languages (see below), resulting from practically all areas of mathematics.
-complete languages (see below), resulting from practically all areas of mathematics.
A language 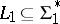 is polynomially reducible to a language
is polynomially reducible to a language 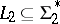 — in symbols
— in symbols 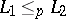 — if and only if there is a deterministic polynomially-bounded Turing machine
— if and only if there is a deterministic polynomially-bounded Turing machine 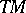 translating words
translating words 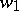 over
over  into words
into words 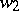 over
over  in such a way that
in such a way that  being in
being in 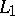 is equivalent to its image
is equivalent to its image 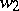 being in
being in 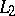 .
.
Observe that the Turing machine  introduced in the previous definition must halt with all inputs — this is a consequence of
introduced in the previous definition must halt with all inputs — this is a consequence of 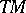 being deterministic and polynomially bounded.
being deterministic and polynomially bounded.
Clearly, whenever 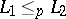 and
and 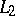 is in
is in 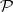 , then
, then 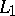 is also in
is also in 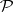 .
.
A language 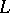 is called
is called 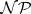 -hard if
-hard if  holds for every language
holds for every language 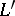 in
in 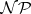 .
.  is termed
is termed 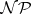 -complete if it is
-complete if it is 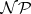 -hard and, in addition, belongs to
-hard and, in addition, belongs to 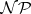 .
.
 -complete languages can be visualized to represent the hardest problems in
-complete languages can be visualized to represent the hardest problems in 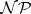 . Moreover, to settle the question of whether or not
. Moreover, to settle the question of whether or not  , it suffices to decide whether or not an arbitrary
, it suffices to decide whether or not an arbitrary  -complete language
-complete language 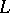 is in
is in 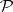 . Indeed, consider such a language
. Indeed, consider such a language 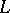 . If
. If 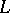 is not in
is not in 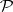 , then clearly
, then clearly  . If
. If 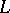 is in
is in 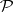 , then the definition of
, then the definition of  -completeness shows that every language in
-completeness shows that every language in 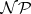 is also in
is also in  . But this means that
. But this means that  .
.
The study of 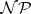 -completeness was initiated in [a2] and [a4], whereas [a3] is a pioneering paper on complexity theory as a whole. One is referred to [a6] for a basic list of
-completeness was initiated in [a2] and [a4], whereas [a3] is a pioneering paper on complexity theory as a whole. One is referred to [a6] for a basic list of 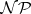 -complete problems. Typical ones are: the traveling sales-person problem, the satisfialility problem for propositional calculus, the Hamiltonian circuit problem for graphs, the knapsack problem, the scheduling problem, and the membership problem for TOL languages (cf.
-complete problems. Typical ones are: the traveling sales-person problem, the satisfialility problem for propositional calculus, the Hamiltonian circuit problem for graphs, the knapsack problem, the scheduling problem, and the membership problem for TOL languages (cf.  -systems).
-systems).
Although a problem is decidable, it might still be intractable in the sense that any algorithm for solving it must use unmanageable amounts of computational resources. Intractability is defined formally by the condition of being outside 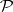 .
.
It has also been observed that, for very many important problems, all algorithms presently known operate in exponential time, whereas it has not been shown that these problems actually are intractable. All  -complete problems belong to this class. Indeed, establishing lower bounds is, in general, a difficult task in complexity theory. The complexity of a particular algorithm can usually be estimated, but it is harder to say something general about all algorithms for a particular problem — for instance, to give a lower bound for their complexity. Results such as the speedup theorem show that this might even be impossible in some cases. According to the theory of abstract complexity measures, one cannot expect to prove that any specific problem is intrinsically difficult in all measures. However, there are also a number of problems known to be intractable.
-complete problems belong to this class. Indeed, establishing lower bounds is, in general, a difficult task in complexity theory. The complexity of a particular algorithm can usually be estimated, but it is harder to say something general about all algorithms for a particular problem — for instance, to give a lower bound for their complexity. Results such as the speedup theorem show that this might even be impossible in some cases. According to the theory of abstract complexity measures, one cannot expect to prove that any specific problem is intrinsically difficult in all measures. However, there are also a number of problems known to be intractable.
Space bounds are defined for Turing machines analogously as time bounds. The denotations  -SPACE and
-SPACE and 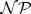 -SPACE stand for languages acceptable by deterministic and non-deterministic Turing machines in polynomial space, respectively. The following relations hold:
-SPACE stand for languages acceptable by deterministic and non-deterministic Turing machines in polynomial space, respectively. The following relations hold:
 |
It is a celebrated open problem whether or not the inclusions are strict.
References
| [a1] | M. Blum, "A machine-independent theory of the complexity of recursive functions" J. ACM , 14 (1967) pp. 322–336 |
| [a2] | S.A. Cook, "The complexity of theorem-proving procedures" , Proc. 3-rd Annual ACM Symp. Theory of Computing , ACM (1971) pp. 151–158 |
| [a3] | J. Hartmanis, R.E. Stearns, "On the computational complexity of algorithms" Trans. Amer. Math. Soc. , 117 (1965) pp. 285–306 |
| [a4] | R.M. Karp, "Reducibility among combinatorial problems" R.E. Miller (ed.) J.W. Tatcher (ed.) , Complexity of Computer Computations. Proc. Symp. IBM , Plenum (85–103) |
| [a5] | A.V. Aho, J.E. Hopcroft, J.D. Ullman, "The design and analysis of computer algorithms" , Addison-Wesley (1974) |
| [a6] | M.R. Garey, D.S. Johnson, "Computers and intractability: a guide to the theory of NP-completeness" , Freeman (1979) |
| [a7] | M. Machtey, P. Young, "An introduction to the general theroy of algorithms" , North-Holland (1978) |
| [a8] | A. Salomaa, "Computation and automata" , Cambridge Univ. Press (1986) |
Complexity theory. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Complexity_theory&oldid=14425