Difference between revisions of "Analysis of programs"
(Importing text file) |
Ulf Rehmann (talk | contribs) m (tex done) |
||
| Line 1: | Line 1: | ||
| + | {{TEX|done}} | ||
| + | |||
''program analysis'' | ''program analysis'' | ||
| Line 4: | Line 6: | ||
==Flow-based approaches to program analysis.== | ==Flow-based approaches to program analysis.== | ||
| − | These have mainly been developed for imperative, functional and object-oriented programs. For a given [[Program|program]] | + | These have mainly been developed for imperative, functional and object-oriented programs. For a given [[Program|program]] $ p $ |
| + | the task is to find a flow function $ F \in { \mathop{\rm Inf}\nolimits} ^ { { \mathop{\rm Pts}\nolimits}} $ | ||
| + | that maps the program points in $ p $ | ||
| + | to approximate descriptions of the data that may reach those points. This may be formalized by a relation $ \vDash p:F $ | ||
| + | defined by a number of clauses depending on the syntax of the program $ p $. | ||
| + | As a very simple example, consider the program $ p = p _{1} ;p _{2} $ | ||
| + | that takes an input, executes $ p _{1} $ | ||
| + | on it, then executes $ p _{2} $ | ||
| + | on the result obtained from $ p _{1} $, | ||
| + | and finally produces the result from $ p _{2} $ | ||
| + | as the overall result. The defining clause for this program may be written:<table border="0" cellpadding="0" cellspacing="0" style="background-color:black;"> <tr><td> <table border="0" cellspacing="1" cellpadding="4" style="background-color:black;"> <tbody> <tr> <td colname="1" style="background-color:white;" colspan="1"> $ \vDash ( p _{1} ;p _{2} ) : F $ | ||
| + | </td> <td colname="2" style="background-color:white;" colspan="1">if and only if</td> </tr> <tr> <td colname="1" style="background-color:white;" colspan="1"></td> <td colname="2" style="background-color:white;" colspan="1"> $ \vDash p _{1} : F \ \land $ | ||
| + | </td> </tr> <tr> <td colname="1" style="background-color:white;" colspan="1"></td> <td colname="2" style="background-color:white;" colspan="1"> $ \vDash p _{2} : F \ \land $ | ||
| + | </td> </tr> <tr> <td colname="1" style="background-color:white;" colspan="1"></td> <td colname="2" style="background-color:white;" colspan="1"> $ F ( { \mathop{\rm end}\nolimits} ( p _{1} ) ) \subseteq F ( { \mathop{\rm begin}\nolimits} ( p _{2} ) ) $ | ||
| + | </td> </tr> </tbody> </table> | ||
</td></tr> </table> | </td></tr> </table> | ||
| − | In the presence of recursive programs, the predicate cannot be defined by structural induction on | + | In the presence of recursive programs, the predicate cannot be defined by structural induction on $ p $ |
| + | and instead one appeals to co-induction; this merely amounts to taking the greatest fixed point of a function mapping sets of pairs $ ( p,F ) $ | ||
| + | into sets of pairs $ ( p,F ) $ | ||
| + | as described by the right-hand sides of the clauses. | ||
| − | It is essential that the analysis information is semantically correct. Given a semantics | + | It is essential that the analysis information is semantically correct. Given a semantics $ v _{1} \rightarrow _{p} v _{2} $ |
| + | for describing when the program $ p $ | ||
| + | maps the input $ v _{1} $ | ||
| + | to the output $ v _{2} $, | ||
| + | this amounts in its simplest form to establishing a subject reduction result: | ||
| − | + | $$ | |
| + | \vDash p: F \land v _{1} \in F ( { \mathop{\rm begin}\nolimits} ( p ) ) \land v _{1} \rightarrow _{p} v _{2} $$ | ||
| − | + | $$ | |
| + | \Downarrow | ||
| + | $$ | ||
| − | + | $$ | |
| + | v _{2} \in F ( { \mathop{\rm end}\nolimits} ( p ) ) | ||
| + | $$ | ||
| − | Finally, realization of the analysis amounts to finding the minimal | + | Finally, realization of the analysis amounts to finding the minimal $ F $( |
| + | with respect to the pointwise partial order on $ { \mathop{\rm Inf}\nolimits} ^ { { \mathop{\rm Pts}\nolimits}} $) | ||
| + | for which $ \vDash p : F $; | ||
| + | this is related to the lattice-theoretic notion of $ \{ F : {\vDash p : F} \} $ | ||
| + | being a Moore family. Often, this is done by obtaining a more implementation-oriented specification $ \vdash p : C $ | ||
| + | for generating a set of constraints $ C $, | ||
| + | deriving a function $ {\widehat{C} } $ | ||
| + | mapping flow functions to flow functions, and ensuring that $ {\widehat{C} } ( F ) = F $ | ||
| + | if and only if $ \vDash p : F $. | ||
==Inference-based approaches to program analysis.== | ==Inference-based approaches to program analysis.== | ||
| − | These have mainly been developed for functional, imperative, and concurrent programs. For a given [[Program|program]] | + | These have mainly been developed for functional, imperative, and concurrent programs. For a given [[Program|program]] $ p $, |
| + | the task is to find an "annotated type" $ q _{1} { \stackrel \sigma \rightarrow } q _{2} $ | ||
| + | describing the overall effect of executing $ p $: | ||
| + | if $ q _{1} $ | ||
| + | describes the input data, then $ q _{2} $ | ||
| + | describes the output data, and properties of the dynamic executions (e.g., whether or not errors can occur) are described by $ \sigma $. | ||
| + | This may be formalized by a relation $ \vdash p: ( q _{1} { \stackrel \sigma \rightarrow } q _{2} ) $ | ||
| + | defined by a number of inference rules (cf. [[Permissible law (inference)|Permissible law (inference)]]); some of these are defined compositionally in the structure of the program as in: | ||
| − | + | $$ | |
| + | { | ||
| + | \frac{ {\vdash p _{1} : ( q _{0} { \stackrel{ {\sigma _ 1}} \rightarrow } q _{1} )} \quad {\vdash p _{2} : ( q _{1} { \stackrel{ {\sigma _ 2}} \rightarrow } q _{2} )}}{ {\vdash ( p _{1} ; p _{2} ) : q _{0} { \stackrel{ {\sigma _{1} \uplus \sigma _ 2}} \rightarrow } q _ 2}} | ||
| + | } | ||
| + | $$ | ||
| − | Here, | + | Here, $ \sigma _{1} \uplus \sigma _{2} $ |
| + | combines the effects $ \sigma _{1} $ | ||
| + | and $ \sigma _{2} $ | ||
| + | into an overall effect; in the simplest cases, $ \sigma _{1} \uplus \sigma _{2} $ | ||
| + | simply equals $ \sigma _{1} \cup \sigma _{2} $, | ||
| + | but in more complex cases the causal structure (i.e. which effect comes first) must be retained. Successful analysis of recursive programs demands that invariants be guessed in order to obtain a finite inference tree. (This form of program analysis is closely related to program verification: see [[Theoretical programming|Theoretical programming]], the section on "The logical theory of programs" .) | ||
| − | Semantic correctness necessitates relations | + | Semantic correctness necessitates relations $ \vDash v:q $ |
| + | between values and properties, e.g. $ ( q = \textrm{ integer } ) \Rightarrow ( v \in \{ \dots , - 1, 0,1, \dots \} ) $, | ||
| + | and $ \vDash d \sim \sigma $ | ||
| + | between the effects of the dynamic semantics $ ( v _{1} {\rightarrow ^ d} _{p} v _{2} ) $ | ||
| + | and the analysis, e.g. $ d = \sigma $. | ||
| + | The correctness statement then amounts to a subject reduction result: | ||
| − | + | $$ | |
| + | ( \vDash v _{1} : q _{1} ) \land ( v _{1} {\rightarrow ^ d} _{p} v _{2} ) \land \vdash p : ( q _{1} { \stackrel \sigma \rightarrow } q _{2} ) | ||
| + | $$ | ||
| − | + | $$ | |
| + | \Downarrow | ||
| + | $$ | ||
| − | + | $$ | |
| + | ( \vDash v _{2} : q _{2} ) \land ( \vDash d \sim \sigma ) | ||
| + | $$ | ||
| − | Implementation of the analysis amounts to defining an [[Algorithm|algorithm]] | + | Implementation of the analysis amounts to defining an [[Algorithm|algorithm]] $ {\mathcal Q} [\![p]\!] = q $ |
| + | that is syntactically sound, i.e. $ \vdash p : q $, | ||
| + | and syntactically complete, i.e. $ \vdash p : ( q _{1} { \stackrel \sigma \rightarrow } q _{2} ) $ | ||
| + | implies that $ q _{1} { \stackrel \sigma \rightarrow } q _{2} $ | ||
| + | is an "instance" of $ q $; | ||
| + | the precise definition of "instance" depends on the nature of the properties and may have some complexity to it. Often, the algorithm works using constraints somewhat similar to those used in the flow-based approach. | ||
==Semantics-based approaches to program analysis.== | ==Semantics-based approaches to program analysis.== | ||
| − | These attempt to define the analysis in much the same way that the semantics itself is defined. These developments have mainly been based on denotational semantics (where | + | These attempt to define the analysis in much the same way that the semantics itself is defined. These developments have mainly been based on denotational semantics (where $ v _{1} \rightarrow _{p} v _{2} $ |
| + | is written $ {\mathcal S} [\![p]\!] ( v _{1} ) = v _{2} $) | ||
| + | for imperative and functional programs, although work has started on similar developments based on (so-called small-step) structural operational semantics and (so-called big-step) natural semantics (cf. also [[Theoretical programming|Theoretical programming]]). The denotational approach may be formulated as an analysis function $ {\mathcal A} [\![p]\!] ( l _{1} ) = l _{2} $, | ||
| + | where $ l _{1} $ | ||
| + | is a mathematical entity describing the input to $ p $ | ||
| + | and $ l _{2} $ | ||
| + | is a mathematical entity describing the output from $ p $. | ||
| + | The denotational approach calls for $ {\mathcal A} [\![p]\!] $ | ||
| + | to be defined compositionally in terms of the syntactic constituents of the program $ p $; | ||
| + | an example of this is the functional composition | ||
| − | + | $$ | |
| + | {\mathcal A} [\![ {p _{1} ; p _ 2} ]\!] = {\mathcal A} | ||
| + | [\![ {p _ 2} ]\!] \circ {\mathcal A} [\![ {p _ 1} ]\!] , | ||
| + | $$ | ||
| − | i.e., | + | i.e., $ {\mathcal A} [\![ {p _{1} ; p _ 2} ]\!] ( l ) = {\mathcal A} [\![ {p _ 2} ]\!] ( {\mathcal A} [\![ {p _ 1} ]\!] ( l ) ) $. |
| + | In case of recursive programs, a least fixed point is taken of a suitable functional. | ||
| − | To express the correctness of the analysis one needs to define correctness relations | + | To express the correctness of the analysis one needs to define correctness relations $ v R _{t} l $ |
| + | on the data, e.g. $ v \in l $, | ||
| + | and $ f R _{ {t _{1} \rightarrow t _ 2}} h $ | ||
| + | on the computations, e.g. $ \forall v, l : ( v R _{ {t _ 1}} l ) \Rightarrow ( f ( v ) R _{ {t _ 2}} h ( l ) ) $; | ||
| + | the latter definition is usually called a logical relation. Semantic soundness then amounts to establishing | ||
| − | + | $$ | |
| + | {\mathcal S} [\![ p]\!] R _{ {t _{1} \rightarrow t _ 2}} {\mathcal A} [\![ p]\!] | ||
| + | $$ | ||
| − | for all programs | + | for all programs $ p $ |
| + | of type $ t _{1} \rightarrow t _{2} $. | ||
| + | Efficient implementation of the analyses often demands that they be presented in a form less dependent on the program syntax, e.g. using graphs or constraints, and then the solution procedure must be shown sound and complete. | ||
==Abstract interpretation.== | ==Abstract interpretation.== | ||
| − | This is a general framework for obtaining cheaper and more approximative solutions to program analysis problems. In its most general form it attempts to be independent of the semantic base, but usually it is formulated in either a structural operational or a denotational setting. Given the semantics | + | This is a general framework for obtaining cheaper and more approximative solutions to program analysis problems. In its most general form it attempts to be independent of the semantic base, but usually it is formulated in either a structural operational or a denotational setting. Given the semantics $ v _{1} \rightarrow _{p} v _{2} $ |
| + | of a program $ p $, | ||
| + | the first step is often to define the uncomputable collecting semantics $ s _{1} \Rightarrow _{p} s _{2} $. | ||
| + | The intention is that | ||
| − | + | $$ | |
| + | s _{1} \Rightarrow _{p} s _{2} $$ | ||
| − | + | $$ | |
| + | \Updownarrow | ||
| + | $$ | ||
| − | + | $$ | |
| + | s _{2} = \left \{ {v _ 2} : {v _{1} \rightarrow _{p} v _{2} \land v _{1} \in s _ 1} \right \} | ||
| + | $$ | ||
and this may be regarded as a soundness as well as a completeness statement. | and this may be regarded as a soundness as well as a completeness statement. | ||
| − | To obtain a more approximate and eventually computable analysis, the most commonly used approach is to replace the sets of values | + | To obtain a more approximate and eventually computable analysis, the most commonly used approach is to replace the sets of values $ s \in S $ |
| + | by some more approximate properties $ l \in L $. | ||
| + | Both $ S $ | ||
| + | and $ L $ | ||
| + | are partially ordered in such a way that one generally wants the least correct element and where the greatest element is uninformative. (By the lattice duality principle, one could instead have desired the greatest correct element, and part of the literature on data flow analysis uses this vocabulary.) The relation between $ S $ | ||
| + | and $ L $ | ||
| + | is often formalized by a pair $ ( \alpha, \gamma ) $ | ||
| + | of functions: | ||
| − | + | $$ | |
| + | S \mathop{\rightleftarrows} ^ \alpha _ \gamma L, | ||
| + | $$ | ||
| − | where | + | where $ \gamma : L \rightarrow S $ |
| + | is the concretization function giving the "meaning" of properties in $ L $, | ||
| + | and $ \alpha : S \rightarrow L $ | ||
| + | is the abstraction function. It is customary to demand that $ S $ | ||
| + | and $ L $ | ||
| + | are complete lattices (cf. [[Complete lattice|Complete lattice]]). Furthermore, it is customary to demand that $ ( \alpha, \gamma ) $ | ||
| + | is a Galois connection, i.e. $ \alpha $ | ||
| + | and $ \gamma $ | ||
| + | are monotone and $ \gamma \circ \alpha $ | ||
| + | is extensive $ ( \forall s: \gamma ( \alpha ( s ) ) \supset s ) $ | ||
| + | and $ \alpha \circ \gamma $ | ||
| + | is reductive $ ( \forall l: \alpha ( \gamma ( l ) ) \subset l ) $, | ||
| + | or, equivalently, that $ ( \alpha, \gamma ) $ | ||
| + | is an adjunction, i.e. $ \forall s, l: \alpha ( s ) \subset l \iff s \subset \gamma ( l ) $. | ||
| + | This ensures that a set of values $ s $ | ||
| + | always has a best description $ l $; | ||
| + | in fact, $ l = \alpha ( s ) $. | ||
| − | Abstract interpretation then amounts to define an analysis | + | Abstract interpretation then amounts to define an analysis $ l _{1} \Rightarrow _ p^ \prime l _{2} $ |
| + | on the properties of $ L $ | ||
| + | such that the following correctness statement holds: | ||
| − | + | $$ | |
| + | l _{1} \Rightarrow _ p^ \prime l _{2} $$ | ||
| − | + | $$ | |
| + | \Downarrow | ||
| + | $$ | ||
| − | + | $$ | |
| + | \exists s : \gamma ( l _{1} ) \Rightarrow _{p} s \land s \subseteq \gamma ( l _{2} ) | ||
| + | $$ | ||
This may be illustrated by the diagram | This may be illustrated by the diagram | ||
| Line 83: | Line 212: | ||
It expresses that a certain diagram semi-commutes. | It expresses that a certain diagram semi-commutes. | ||
| − | Example analyses that can be obtained in this way include intervals as approximations of sets of integers, polygons in the plane as approximations of sets of pairs of numbers, representations | + | Example analyses that can be obtained in this way include intervals as approximations of sets of integers, polygons in the plane as approximations of sets of pairs of numbers, representations $ ( k _{1} , k _{2} ) $ |
| + | of arithmetical congruences as approximations of periodic sets $ \{ {k _{1} + n \cdot k _ 2} : {n \in \{ \dots , - 1, 0, 1, \dots \}} \} $ | ||
| + | as well as combinations of these. | ||
==Fixed-point approximation.== | ==Fixed-point approximation.== | ||
| − | This is essential for program analysis because most of the approaches can be reformulated as finding the least fixed point (cf. also [[Fixed point|Fixed point]]) | + | This is essential for program analysis because most of the approaches can be reformulated as finding the least fixed point (cf. also [[Fixed point|Fixed point]]) $ { \mathop{\rm lfp}\nolimits} ( f ) $ |
| + | of a monotone function $ f : L \rightarrow L $ | ||
| + | on a [[Complete lattice|complete lattice]] $ L = ( L, \subset ) $ | ||
| + | of properties; often, each element $ l \in L $ | ||
| + | describes a set of values. There are two characterizations of the least fixed point that are of relevance here. Tarski's theorem ensures that | ||
| − | + | $$ | |
| + | { \mathop{\rm lfp}\nolimits} ( f ) = \bigcap { \mathop{\rm Red}\nolimits} ( f ) , | ||
| + | $$ | ||
| − | + | $$ | |
| + | { \mathop{\rm Red}\nolimits} ( f ) = \left \{ {l \in L} : {f ( l ) \subset l} \right \} , | ||
| + | $$ | ||
| − | satisfies | + | satisfies $ f ( { \mathop{\rm lfp}\nolimits} ( f ) ) = { \mathop{\rm lfp}\nolimits} ( f ) $ |
| + | and hence $ { \mathop{\rm lfp}\nolimits} ( f ) \in { \mathop{\rm Red}\nolimits} ( f ) $ | ||
| + | is the least fixed point of $ f $. | ||
| + | [[Transfinite induction|Transfinite induction]] allows one to define | ||
| − | + | $$ | |
| + | f ^ {[ \kappa + 1 ]} = f ( f ^ {[ \kappa ]} ) \ \textrm{ for } \ \kappa+1 \ \textrm{ a successor ordinal } , | ||
| + | $$ | ||
| − | + | $$ | |
| + | f ^ {[ \kappa ]} = \bigcup _{ {\kappa^ \prime } < \kappa} f ^ {[ \kappa^ \prime ]} \ \textrm{ for } \ \kappa \ \textrm{ a limit ordinal } , | ||
| + | $$ | ||
and then the least fixed point is given by | and then the least fixed point is given by | ||
| − | + | $$ | |
| + | { \mathop{\rm lfp}\nolimits} ( f ) = f ^ {[ \lambda ]} | ||
| + | $$ | ||
| − | for some cardinal number | + | for some cardinal number $ \lambda $; |
| + | it suffices to let $ \lambda $ | ||
| + | be the cardinality of $ 2^{L} $. | ||
| + | In simple cases, $ L $ | ||
| + | has finite height (all strictly increasing sequences are finite) and then $ \lambda $ | ||
| + | may be taken to be a natural number $ n _{0} $; | ||
| + | this then suggests a computable procedure for calculating $ { \mathop{\rm lfp}\nolimits} ( f ) $: | ||
| + | simply do the finite number of calculations $ f ^ {[ 0 ]} \dots f ^ {[ n _{0} ]} = f ^ {n _ 0} ( f ^ {[ 0 ]} ) = { \mathop{\rm lfp}\nolimits} ( f ) $. | ||
| − | In general, | + | In general, $ \lambda $ |
| + | cannot simply be taken to be a natural number and then one has to be content with a computable procedure for finding some $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) \in L $ | ||
| + | such that $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) \supset { \mathop{\rm lfp}\nolimits} ( f ) $; | ||
| + | for pragmatic reasons $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) $ | ||
| + | should be "as close to" $ { \mathop{\rm lfp}\nolimits} ( f ) $ | ||
| + | as possible. An upper bound operator $ \nabla : {L \times L} \rightarrow L $ | ||
| + | is a not necessarily monotone function such that $ l _{1} \nabla l _{2} \supset l _{1} \bigcup l _{2} $ | ||
| + | for all $ l _{1} , l _{2} \in L $. | ||
| + | Given a not necessarily increasing sequence $ ( l _{n} ) _{n} $, | ||
| + | one can then define | ||
| − | + | $$ | |
| + | l _ 0^ \nabla = l _{0} , | ||
| + | $$ | ||
| − | + | $$ | |
| + | l _{ {n + 1}^ \nabla } = l _ n^ \nabla \nabla l _{ {n + 1}} , | ||
| + | $$ | ||
| − | for all natural numbers | + | for all natural numbers $ n $. |
| + | It is easy to show that $ ( l _ n^ \nabla ) _{n} $ | ||
| + | is in fact an increasing sequence. A widening operator $ \nabla : {L \times L} \rightarrow L $ | ||
| + | is an upper bound operator such that $ ( l _ n^ \nabla ) _{n} $ | ||
| + | eventually stabilizes (i.e. $ \exists n _{0} \forall n \geq n _{0} :l _ n^ \nabla = l _{ {n _ 0}^ \nabla } $) | ||
| + | for all increasing sequences $ ( l _{n} ) _{n} $. | ||
| + | (A trivial and uninteresting example of a widening operator is given by $ l _{1} \nabla l _{2} = \bigcup L $.) | ||
| + | One can now define | ||
| − | + | $$ | |
| + | f _ \nabla ^ {\left \langle 0 \right \rangle} = \bigcap L \ \textrm{ (the least element of } \ L \textrm{ ) } , | ||
| + | $$ | ||
| − | + | $$ | |
| + | f _ \nabla ^ {\left \langle {n + 1} \right \rangle} = \left \{ | ||
| + | { {f _ \nabla ^ {\left \langle n \right \rangle} \ \ \textrm{ if } \ f ( f _ \nabla ^ {\left \langle n \right \rangle} ) \subset f _ \nabla ^ {\left \langle n \right \rangle} ,} \atop {f _ \nabla ^ {\left \langle n \right \rangle}\nabla f ( f _ \nabla ^ {\left \langle n \right \rangle} ) \ \ \textrm{ otherwise } ,}} \right . | ||
| + | $$ | ||
| − | for all natural numbers | + | for all natural numbers $ n $. |
| + | One can show that $ ( f _ \nabla ^ {\langle n \rangle} ) _{n} $ | ||
| + | eventually stabilizes and that $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) = \bigcup _{n} f _ \nabla ^ {\langle n \rangle} $ | ||
| + | equals $ f _ \nabla ^ {\langle {n _ 0} \rangle} $ | ||
| + | for some $ n _{0} $ | ||
| + | and that $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) \in { \mathop{\rm Red}\nolimits} ( f ) $. | ||
| + | Hence, $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) \supset { \mathop{\rm lfp}\nolimits} ( f ) $ | ||
| + | and, furthermore, there is a computable procedure for calculating $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) $: | ||
| + | simply do the finite number of calculations $ f _ \nabla ^ {\langle 0 \rangle} \dots f _ \nabla ^ {\langle {n _ 0} \rangle} = { \mathop{\rm fix}\nolimits} _ \nabla ( f ) $. | ||
| + | Examples of "good" widening operators can be found in the literature. | ||
====References==== | ====References==== | ||
<table><TR><TD valign="top">[a1]</TD> <TD valign="top"> P. Cousot, "Semantic foundations of program analysis" S.S. Muchnick (ed.) N.D. Jones (ed.) , ''Program Flow Analysis: Theory and Applications'' , Prentice-Hall (1981) pp. 303–342</TD></TR><TR><TD valign="top">[a2]</TD> <TD valign="top"> S. Jagannathan, S. Weeks, "A unified treatment of flow analysis in higher-order languages" , ''Proc. POPL '95'' , ACM Press (1995) pp. 393–407</TD></TR><TR><TD valign="top">[a3]</TD> <TD valign="top"> N.D. Jones, F. Nielson, "Abstract interpretation: a semantics-based tool for program analysis" S. Abramsky (ed.) D.M. Gabbay (ed.) T.S.E. Maibaum (ed.) , ''Handbook of Logic in Computer Science'' , '''4''' , Oxford Univ. Press (1995) pp. 527–636</TD></TR><TR><TD valign="top">[a4]</TD> <TD valign="top"> J.P. Talpin, P. Jouvelot, "The type and effect discipline" , ''Information and Computation'' , '''111''' (1994)</TD></TR></table> | <table><TR><TD valign="top">[a1]</TD> <TD valign="top"> P. Cousot, "Semantic foundations of program analysis" S.S. Muchnick (ed.) N.D. Jones (ed.) , ''Program Flow Analysis: Theory and Applications'' , Prentice-Hall (1981) pp. 303–342</TD></TR><TR><TD valign="top">[a2]</TD> <TD valign="top"> S. Jagannathan, S. Weeks, "A unified treatment of flow analysis in higher-order languages" , ''Proc. POPL '95'' , ACM Press (1995) pp. 393–407</TD></TR><TR><TD valign="top">[a3]</TD> <TD valign="top"> N.D. Jones, F. Nielson, "Abstract interpretation: a semantics-based tool for program analysis" S. Abramsky (ed.) D.M. Gabbay (ed.) T.S.E. Maibaum (ed.) , ''Handbook of Logic in Computer Science'' , '''4''' , Oxford Univ. Press (1995) pp. 527–636</TD></TR><TR><TD valign="top">[a4]</TD> <TD valign="top"> J.P. Talpin, P. Jouvelot, "The type and effect discipline" , ''Information and Computation'' , '''111''' (1994)</TD></TR></table> | ||
Revision as of 18:23, 5 February 2020
program analysis
Program analysis offers static (i.e. compile-time) techniques for predicting safe and computable approximations to the set of values or behaviours arising dynamically (i.e. at run-time) when executing a program upon a computer. A main application is to allow compilers to generate more efficient code by avoiding to generate code to handle errors that can be shown not to arise, and to generate more specialized and faster code by taking advantage of the availability of data in registers and caches. Among the newer applications is the validation of software (possibly developed by subcontractors) to reduce the likelihood of malicious behaviour. To illustrate the breadth of the approaches, five types of analyses will be discussed: i) flow-based analysis; ii) inference-based analysis; iii) semantics-based analysis; iv) abstract interpretation; and v) fixed-point approximation techniques. These approaches borrow mathematical techniques from lattice theory and logical systems.
Flow-based approaches to program analysis.
These have mainly been developed for imperative, functional and object-oriented programs. For a given program $ p $ the task is to find a flow function $ F \in { \mathop{\rm Inf}\nolimits} ^ { { \mathop{\rm Pts}\nolimits}} $ that maps the program points in $ p $ to approximate descriptions of the data that may reach those points. This may be formalized by a relation $ \vDash p:F $ defined by a number of clauses depending on the syntax of the program $ p $. As a very simple example, consider the program $ p = p _{1} ;p _{2} $ that takes an input, executes $ p _{1} $ on it, then executes $ p _{2} $ on the result obtained from $ p _{1} $, and finally produces the result from $ p _{2} $
as the overall result. The defining clause for this program may be written:
<tbody> </tbody>
|
In the presence of recursive programs, the predicate cannot be defined by structural induction on $ p $ and instead one appeals to co-induction; this merely amounts to taking the greatest fixed point of a function mapping sets of pairs $ ( p,F ) $ into sets of pairs $ ( p,F ) $ as described by the right-hand sides of the clauses.
It is essential that the analysis information is semantically correct. Given a semantics $ v _{1} \rightarrow _{p} v _{2} $ for describing when the program $ p $ maps the input $ v _{1} $ to the output $ v _{2} $, this amounts in its simplest form to establishing a subject reduction result:
$$ \vDash p: F \land v _{1} \in F ( { \mathop{\rm begin}\nolimits} ( p ) ) \land v _{1} \rightarrow _{p} v _{2} $$
$$ \Downarrow $$
$$ v _{2} \in F ( { \mathop{\rm end}\nolimits} ( p ) ) $$
Finally, realization of the analysis amounts to finding the minimal $ F $( with respect to the pointwise partial order on $ { \mathop{\rm Inf}\nolimits} ^ { { \mathop{\rm Pts}\nolimits}} $) for which $ \vDash p : F $; this is related to the lattice-theoretic notion of $ \{ F : {\vDash p : F} \} $ being a Moore family. Often, this is done by obtaining a more implementation-oriented specification $ \vdash p : C $ for generating a set of constraints $ C $, deriving a function $ {\widehat{C} } $ mapping flow functions to flow functions, and ensuring that $ {\widehat{C} } ( F ) = F $ if and only if $ \vDash p : F $.
Inference-based approaches to program analysis.
These have mainly been developed for functional, imperative, and concurrent programs. For a given program $ p $, the task is to find an "annotated type" $ q _{1} { \stackrel \sigma \rightarrow } q _{2} $ describing the overall effect of executing $ p $: if $ q _{1} $ describes the input data, then $ q _{2} $ describes the output data, and properties of the dynamic executions (e.g., whether or not errors can occur) are described by $ \sigma $. This may be formalized by a relation $ \vdash p: ( q _{1} { \stackrel \sigma \rightarrow } q _{2} ) $ defined by a number of inference rules (cf. Permissible law (inference)); some of these are defined compositionally in the structure of the program as in:
$$ { \frac{ {\vdash p _{1} : ( q _{0} { \stackrel{ {\sigma _ 1}} \rightarrow } q _{1} )} \quad {\vdash p _{2} : ( q _{1} { \stackrel{ {\sigma _ 2}} \rightarrow } q _{2} )}}{ {\vdash ( p _{1} ; p _{2} ) : q _{0} { \stackrel{ {\sigma _{1} \uplus \sigma _ 2}} \rightarrow } q _ 2}} } $$
Here, $ \sigma _{1} \uplus \sigma _{2} $ combines the effects $ \sigma _{1} $ and $ \sigma _{2} $ into an overall effect; in the simplest cases, $ \sigma _{1} \uplus \sigma _{2} $ simply equals $ \sigma _{1} \cup \sigma _{2} $, but in more complex cases the causal structure (i.e. which effect comes first) must be retained. Successful analysis of recursive programs demands that invariants be guessed in order to obtain a finite inference tree. (This form of program analysis is closely related to program verification: see Theoretical programming, the section on "The logical theory of programs" .)
Semantic correctness necessitates relations $ \vDash v:q $ between values and properties, e.g. $ ( q = \textrm{ integer } ) \Rightarrow ( v \in \{ \dots , - 1, 0,1, \dots \} ) $, and $ \vDash d \sim \sigma $ between the effects of the dynamic semantics $ ( v _{1} {\rightarrow ^ d} _{p} v _{2} ) $ and the analysis, e.g. $ d = \sigma $. The correctness statement then amounts to a subject reduction result:
$$ ( \vDash v _{1} : q _{1} ) \land ( v _{1} {\rightarrow ^ d} _{p} v _{2} ) \land \vdash p : ( q _{1} { \stackrel \sigma \rightarrow } q _{2} ) $$
$$ \Downarrow $$
$$ ( \vDash v _{2} : q _{2} ) \land ( \vDash d \sim \sigma ) $$
Implementation of the analysis amounts to defining an algorithm $ {\mathcal Q} [\![p]\!] = q $ that is syntactically sound, i.e. $ \vdash p : q $, and syntactically complete, i.e. $ \vdash p : ( q _{1} { \stackrel \sigma \rightarrow } q _{2} ) $ implies that $ q _{1} { \stackrel \sigma \rightarrow } q _{2} $ is an "instance" of $ q $; the precise definition of "instance" depends on the nature of the properties and may have some complexity to it. Often, the algorithm works using constraints somewhat similar to those used in the flow-based approach.
Semantics-based approaches to program analysis.
These attempt to define the analysis in much the same way that the semantics itself is defined. These developments have mainly been based on denotational semantics (where $ v _{1} \rightarrow _{p} v _{2} $ is written $ {\mathcal S} [\![p]\!] ( v _{1} ) = v _{2} $) for imperative and functional programs, although work has started on similar developments based on (so-called small-step) structural operational semantics and (so-called big-step) natural semantics (cf. also Theoretical programming). The denotational approach may be formulated as an analysis function $ {\mathcal A} [\![p]\!] ( l _{1} ) = l _{2} $, where $ l _{1} $ is a mathematical entity describing the input to $ p $ and $ l _{2} $ is a mathematical entity describing the output from $ p $. The denotational approach calls for $ {\mathcal A} [\![p]\!] $ to be defined compositionally in terms of the syntactic constituents of the program $ p $; an example of this is the functional composition
$$ {\mathcal A} [\![ {p _{1} ; p _ 2} ]\!] = {\mathcal A} [\![ {p _ 2} ]\!] \circ {\mathcal A} [\![ {p _ 1} ]\!] , $$
i.e., $ {\mathcal A} [\![ {p _{1} ; p _ 2} ]\!] ( l ) = {\mathcal A} [\![ {p _ 2} ]\!] ( {\mathcal A} [\![ {p _ 1} ]\!] ( l ) ) $. In case of recursive programs, a least fixed point is taken of a suitable functional.
To express the correctness of the analysis one needs to define correctness relations $ v R _{t} l $ on the data, e.g. $ v \in l $, and $ f R _{ {t _{1} \rightarrow t _ 2}} h $ on the computations, e.g. $ \forall v, l : ( v R _{ {t _ 1}} l ) \Rightarrow ( f ( v ) R _{ {t _ 2}} h ( l ) ) $; the latter definition is usually called a logical relation. Semantic soundness then amounts to establishing
$$ {\mathcal S} [\![ p]\!] R _{ {t _{1} \rightarrow t _ 2}} {\mathcal A} [\![ p]\!] $$
for all programs $ p $ of type $ t _{1} \rightarrow t _{2} $. Efficient implementation of the analyses often demands that they be presented in a form less dependent on the program syntax, e.g. using graphs or constraints, and then the solution procedure must be shown sound and complete.
Abstract interpretation.
This is a general framework for obtaining cheaper and more approximative solutions to program analysis problems. In its most general form it attempts to be independent of the semantic base, but usually it is formulated in either a structural operational or a denotational setting. Given the semantics $ v _{1} \rightarrow _{p} v _{2} $ of a program $ p $, the first step is often to define the uncomputable collecting semantics $ s _{1} \Rightarrow _{p} s _{2} $. The intention is that
$$ s _{1} \Rightarrow _{p} s _{2} $$
$$ \Updownarrow $$
$$ s _{2} = \left \{ {v _ 2} : {v _{1} \rightarrow _{p} v _{2} \land v _{1} \in s _ 1} \right \} $$
and this may be regarded as a soundness as well as a completeness statement.
To obtain a more approximate and eventually computable analysis, the most commonly used approach is to replace the sets of values $ s \in S $ by some more approximate properties $ l \in L $. Both $ S $ and $ L $ are partially ordered in such a way that one generally wants the least correct element and where the greatest element is uninformative. (By the lattice duality principle, one could instead have desired the greatest correct element, and part of the literature on data flow analysis uses this vocabulary.) The relation between $ S $ and $ L $ is often formalized by a pair $ ( \alpha, \gamma ) $ of functions:
$$ S \mathop{\rightleftarrows} ^ \alpha _ \gamma L, $$
where $ \gamma : L \rightarrow S $ is the concretization function giving the "meaning" of properties in $ L $, and $ \alpha : S \rightarrow L $ is the abstraction function. It is customary to demand that $ S $ and $ L $ are complete lattices (cf. Complete lattice). Furthermore, it is customary to demand that $ ( \alpha, \gamma ) $ is a Galois connection, i.e. $ \alpha $ and $ \gamma $ are monotone and $ \gamma \circ \alpha $ is extensive $ ( \forall s: \gamma ( \alpha ( s ) ) \supset s ) $ and $ \alpha \circ \gamma $ is reductive $ ( \forall l: \alpha ( \gamma ( l ) ) \subset l ) $, or, equivalently, that $ ( \alpha, \gamma ) $ is an adjunction, i.e. $ \forall s, l: \alpha ( s ) \subset l \iff s \subset \gamma ( l ) $. This ensures that a set of values $ s $ always has a best description $ l $; in fact, $ l = \alpha ( s ) $.
Abstract interpretation then amounts to define an analysis $ l _{1} \Rightarrow _ p^ \prime l _{2} $ on the properties of $ L $ such that the following correctness statement holds:
$$ l _{1} \Rightarrow _ p^ \prime l _{2} $$
$$ \Downarrow $$
$$ \exists s : \gamma ( l _{1} ) \Rightarrow _{p} s \land s \subseteq \gamma ( l _{2} ) $$
This may be illustrated by the diagram
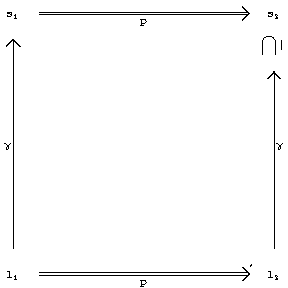
Figure: a110580a
It expresses that a certain diagram semi-commutes.
Example analyses that can be obtained in this way include intervals as approximations of sets of integers, polygons in the plane as approximations of sets of pairs of numbers, representations $ ( k _{1} , k _{2} ) $ of arithmetical congruences as approximations of periodic sets $ \{ {k _{1} + n \cdot k _ 2} : {n \in \{ \dots , - 1, 0, 1, \dots \}} \} $ as well as combinations of these.
Fixed-point approximation.
This is essential for program analysis because most of the approaches can be reformulated as finding the least fixed point (cf. also Fixed point) $ { \mathop{\rm lfp}\nolimits} ( f ) $ of a monotone function $ f : L \rightarrow L $ on a complete lattice $ L = ( L, \subset ) $ of properties; often, each element $ l \in L $ describes a set of values. There are two characterizations of the least fixed point that are of relevance here. Tarski's theorem ensures that
$$ { \mathop{\rm lfp}\nolimits} ( f ) = \bigcap { \mathop{\rm Red}\nolimits} ( f ) , $$
$$ { \mathop{\rm Red}\nolimits} ( f ) = \left \{ {l \in L} : {f ( l ) \subset l} \right \} , $$
satisfies $ f ( { \mathop{\rm lfp}\nolimits} ( f ) ) = { \mathop{\rm lfp}\nolimits} ( f ) $ and hence $ { \mathop{\rm lfp}\nolimits} ( f ) \in { \mathop{\rm Red}\nolimits} ( f ) $ is the least fixed point of $ f $. Transfinite induction allows one to define
$$ f ^ {[ \kappa + 1 ]} = f ( f ^ {[ \kappa ]} ) \ \textrm{ for } \ \kappa+1 \ \textrm{ a successor ordinal } , $$
$$ f ^ {[ \kappa ]} = \bigcup _{ {\kappa^ \prime } < \kappa} f ^ {[ \kappa^ \prime ]} \ \textrm{ for } \ \kappa \ \textrm{ a limit ordinal } , $$
and then the least fixed point is given by
$$ { \mathop{\rm lfp}\nolimits} ( f ) = f ^ {[ \lambda ]} $$
for some cardinal number $ \lambda $; it suffices to let $ \lambda $ be the cardinality of $ 2^{L} $. In simple cases, $ L $ has finite height (all strictly increasing sequences are finite) and then $ \lambda $ may be taken to be a natural number $ n _{0} $; this then suggests a computable procedure for calculating $ { \mathop{\rm lfp}\nolimits} ( f ) $: simply do the finite number of calculations $ f ^ {[ 0 ]} \dots f ^ {[ n _{0} ]} = f ^ {n _ 0} ( f ^ {[ 0 ]} ) = { \mathop{\rm lfp}\nolimits} ( f ) $.
In general, $ \lambda $ cannot simply be taken to be a natural number and then one has to be content with a computable procedure for finding some $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) \in L $ such that $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) \supset { \mathop{\rm lfp}\nolimits} ( f ) $; for pragmatic reasons $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) $ should be "as close to" $ { \mathop{\rm lfp}\nolimits} ( f ) $ as possible. An upper bound operator $ \nabla : {L \times L} \rightarrow L $ is a not necessarily monotone function such that $ l _{1} \nabla l _{2} \supset l _{1} \bigcup l _{2} $ for all $ l _{1} , l _{2} \in L $. Given a not necessarily increasing sequence $ ( l _{n} ) _{n} $, one can then define
$$ l _ 0^ \nabla = l _{0} , $$
$$ l _{ {n + 1}^ \nabla } = l _ n^ \nabla \nabla l _{ {n + 1}} , $$
for all natural numbers $ n $. It is easy to show that $ ( l _ n^ \nabla ) _{n} $ is in fact an increasing sequence. A widening operator $ \nabla : {L \times L} \rightarrow L $ is an upper bound operator such that $ ( l _ n^ \nabla ) _{n} $ eventually stabilizes (i.e. $ \exists n _{0} \forall n \geq n _{0} :l _ n^ \nabla = l _{ {n _ 0}^ \nabla } $) for all increasing sequences $ ( l _{n} ) _{n} $. (A trivial and uninteresting example of a widening operator is given by $ l _{1} \nabla l _{2} = \bigcup L $.) One can now define
$$ f _ \nabla ^ {\left \langle 0 \right \rangle} = \bigcap L \ \textrm{ (the least element of } \ L \textrm{ ) } , $$
$$ f _ \nabla ^ {\left \langle {n + 1} \right \rangle} = \left \{ { {f _ \nabla ^ {\left \langle n \right \rangle} \ \ \textrm{ if } \ f ( f _ \nabla ^ {\left \langle n \right \rangle} ) \subset f _ \nabla ^ {\left \langle n \right \rangle} ,} \atop {f _ \nabla ^ {\left \langle n \right \rangle}\nabla f ( f _ \nabla ^ {\left \langle n \right \rangle} ) \ \ \textrm{ otherwise } ,}} \right . $$
for all natural numbers $ n $. One can show that $ ( f _ \nabla ^ {\langle n \rangle} ) _{n} $ eventually stabilizes and that $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) = \bigcup _{n} f _ \nabla ^ {\langle n \rangle} $ equals $ f _ \nabla ^ {\langle {n _ 0} \rangle} $ for some $ n _{0} $ and that $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) \in { \mathop{\rm Red}\nolimits} ( f ) $. Hence, $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) \supset { \mathop{\rm lfp}\nolimits} ( f ) $ and, furthermore, there is a computable procedure for calculating $ { \mathop{\rm fix}\nolimits} _ \nabla ( f ) $: simply do the finite number of calculations $ f _ \nabla ^ {\langle 0 \rangle} \dots f _ \nabla ^ {\langle {n _ 0} \rangle} = { \mathop{\rm fix}\nolimits} _ \nabla ( f ) $. Examples of "good" widening operators can be found in the literature.
References
| [a1] | P. Cousot, "Semantic foundations of program analysis" S.S. Muchnick (ed.) N.D. Jones (ed.) , Program Flow Analysis: Theory and Applications , Prentice-Hall (1981) pp. 303–342 |
| [a2] | S. Jagannathan, S. Weeks, "A unified treatment of flow analysis in higher-order languages" , Proc. POPL '95 , ACM Press (1995) pp. 393–407 |
| [a3] | N.D. Jones, F. Nielson, "Abstract interpretation: a semantics-based tool for program analysis" S. Abramsky (ed.) D.M. Gabbay (ed.) T.S.E. Maibaum (ed.) , Handbook of Logic in Computer Science , 4 , Oxford Univ. Press (1995) pp. 527–636 |
| [a4] | J.P. Talpin, P. Jouvelot, "The type and effect discipline" , Information and Computation , 111 (1994) |
Analysis of programs. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Analysis_of_programs&oldid=44381