Difference between revisions of "Anderson-Darling statistic"
Ulf Rehmann (talk | contribs) m (moved Anderson–Darling statistic to Anderson-Darling statistic: ascii title) |
Ulf Rehmann (talk | contribs) m (tex encoded by computer) |
||
| Line 1: | Line 1: | ||
| − | + | <!-- | |
| + | a1106001.png | ||
| + | $#A+1 = 21 n = 1 | ||
| + | $#C+1 = 21 : ~/encyclopedia/old_files/data/A110/A.1100600 Anderson\ANDDarling statistic | ||
| + | Automatically converted into TeX, above some diagnostics. | ||
| + | Please remove this comment and the {{TEX|auto}} line below, | ||
| + | if TeX found to be correct. | ||
| + | --> | ||
| − | + | {{TEX|auto}} | |
| + | {{TEX|done}} | ||
| − | + | In the goodness-of-fit problem (cf. [[Goodness-of-fit test|Goodness-of-fit test]]) one wants to test whether the distribution function of a [[Random variable|random variable]] $ X $ | |
| + | belongs to a given set of distribution functions. In the simplest case this set consists of one completely specified (continuous) distribution function $ F _ {0} $, | ||
| + | say. A well-known class of test statistics for this testing problem is the class of EDF statistics, thus called since they measure the discrepancy between the empirical distribution function and $ F _ {0} $. | ||
| + | The empirical distribution function $ F _ {n} $ | ||
| + | is a non-parametric [[Statistical estimator|statistical estimator]] of the true distribution function based on a sample $ X _ {1} \dots X _ {n} $. | ||
| + | The weighted Cramér–von Mises statistics form a subclass of the EDF statistics. They are defined by | ||
| + | |||
| + | $$ | ||
| + | \int\limits {\{ F _ {n} ( x ) - F _ {0} ( x ) \} ^ {2} w ( F _ {0} ( x ) ) } {d F _ {0} ( x ) } , | ||
| + | $$ | ||
| + | |||
| + | where $ w $ | ||
| + | is a non-negative weight function. The weight function is often used to put extra weight in the tails of the distribution, since $ F _ {n} ( x ) - F _ {0} ( x ) $ | ||
| + | is close to zero at the tails and some form of relative error is more attractive. | ||
A particular member of this subclass is the Anderson–Darling statistic, see [[#References|[a1]]], [[#References|[a2]]], obtained by taking | A particular member of this subclass is the Anderson–Darling statistic, see [[#References|[a1]]], [[#References|[a2]]], obtained by taking | ||
| − | + | $$ | |
| + | w ( x ) = [ F _ {0} ( x ) \{ 1 - F _ {0} ( x ) \} ] ^ {- 1 } . | ||
| + | $$ | ||
To calculate the Anderson–Darling statistic one may use the following formula: | To calculate the Anderson–Darling statistic one may use the following formula: | ||
| − | + | $$ | |
| + | - n - n ^ {- 1 } \sum _ { i } \{ ( 2i - 1 ) { \mathop{\rm ln} } z _ {i} + ( 2n + 1 - 2i ) { \mathop{\rm ln} } ( 1 - z _ {i} ) \} , | ||
| + | $$ | ||
| − | with | + | with $ z _ {i} = F _ {0} ( X _ {( i ) } ) $ |
| + | and $ X _ {( 1 ) } < \dots < X _ {( n ) } $ | ||
| + | the ordered sample. | ||
| − | It turns out, cf. [[#References|[a7]]] and references therein, that the Anderson–Darling test is locally asymptotically optimal in the sense of Bahadur under logistic alternatives (cf. [[Bahadur efficiency|Bahadur efficiency]]). Moreover, under normal alternatives its local Bahadur efficiency is | + | It turns out, cf. [[#References|[a7]]] and references therein, that the Anderson–Darling test is locally asymptotically optimal in the sense of Bahadur under logistic alternatives (cf. [[Bahadur efficiency|Bahadur efficiency]]). Moreover, under normal alternatives its local Bahadur efficiency is $ 0.96 $, |
| + | and hence the test is close to optimal. | ||
| − | In practice, it is of more interest to test whether the distribution function of | + | In practice, it is of more interest to test whether the distribution function of $ X $ |
| + | belongs to a class of distribution functions $ \{ F ( x, \theta ) \} $ | ||
| + | indexed by a nuisance parameter $ \theta $, | ||
| + | as, for instance, the class of normal, exponential, or logistic distributions. The Anderson–Darling statistic is now obtained by replacing $ F _ {0} ( X _ {( i ) } ) $ | ||
| + | by $ F ( X _ {( i ) } , {\widehat \theta } ) $ | ||
| + | in calculating $ z _ {i} $, | ||
| + | where $ {\widehat \theta } $ | ||
| + | is an estimator of $ \theta $. | ||
| + | Often, the maximum-likelihood estimator (cf. also [[Maximum-likelihood method|Maximum-likelihood method]]) is used, but see [[#References|[a5]]] for a discussion on the use of other estimators. | ||
Simulation results, cf. [[#References|[a3]]], [[#References|[a4]]], [[#References|[a5]]], [[#References|[a6]]] and references therein, show that the Anderson–Darling test performs well for testing normality (cf. [[Normal distribution|Normal distribution]]), and is a reasonable test for testing exponentiality and in many other testing problems. | Simulation results, cf. [[#References|[a3]]], [[#References|[a4]]], [[#References|[a5]]], [[#References|[a6]]] and references therein, show that the Anderson–Darling test performs well for testing normality (cf. [[Normal distribution|Normal distribution]]), and is a reasonable test for testing exponentiality and in many other testing problems. | ||
Revision as of 18:47, 5 April 2020
In the goodness-of-fit problem (cf. Goodness-of-fit test) one wants to test whether the distribution function of a random variable $ X $
belongs to a given set of distribution functions. In the simplest case this set consists of one completely specified (continuous) distribution function $ F _ {0} $,
say. A well-known class of test statistics for this testing problem is the class of EDF statistics, thus called since they measure the discrepancy between the empirical distribution function and $ F _ {0} $.
The empirical distribution function $ F _ {n} $
is a non-parametric statistical estimator of the true distribution function based on a sample $ X _ {1} \dots X _ {n} $.
The weighted Cramér–von Mises statistics form a subclass of the EDF statistics. They are defined by
$$ \int\limits {\{ F _ {n} ( x ) - F _ {0} ( x ) \} ^ {2} w ( F _ {0} ( x ) ) } {d F _ {0} ( x ) } , $$
where $ w $ is a non-negative weight function. The weight function is often used to put extra weight in the tails of the distribution, since $ F _ {n} ( x ) - F _ {0} ( x ) $ is close to zero at the tails and some form of relative error is more attractive.
A particular member of this subclass is the Anderson–Darling statistic, see [a1], [a2], obtained by taking
$$ w ( x ) = [ F _ {0} ( x ) \{ 1 - F _ {0} ( x ) \} ] ^ {- 1 } . $$
To calculate the Anderson–Darling statistic one may use the following formula:
$$ - n - n ^ {- 1 } \sum _ { i } \{ ( 2i - 1 ) { \mathop{\rm ln} } z _ {i} + ( 2n + 1 - 2i ) { \mathop{\rm ln} } ( 1 - z _ {i} ) \} , $$
with $ z _ {i} = F _ {0} ( X _ {( i ) } ) $ and $ X _ {( 1 ) } < \dots < X _ {( n ) } $ the ordered sample.
It turns out, cf. [a7] and references therein, that the Anderson–Darling test is locally asymptotically optimal in the sense of Bahadur under logistic alternatives (cf. Bahadur efficiency). Moreover, under normal alternatives its local Bahadur efficiency is $ 0.96 $, and hence the test is close to optimal.
In practice, it is of more interest to test whether the distribution function of $ X $ belongs to a class of distribution functions $ \{ F ( x, \theta ) \} $ indexed by a nuisance parameter $ \theta $, as, for instance, the class of normal, exponential, or logistic distributions. The Anderson–Darling statistic is now obtained by replacing $ F _ {0} ( X _ {( i ) } ) $ by $ F ( X _ {( i ) } , {\widehat \theta } ) $ in calculating $ z _ {i} $, where $ {\widehat \theta } $ is an estimator of $ \theta $. Often, the maximum-likelihood estimator (cf. also Maximum-likelihood method) is used, but see [a5] for a discussion on the use of other estimators.
Simulation results, cf. [a3], [a4], [a5], [a6] and references therein, show that the Anderson–Darling test performs well for testing normality (cf. Normal distribution), and is a reasonable test for testing exponentiality and in many other testing problems.
References
| [a1] | T.W. Anderson, D.A. Darling, "Asymptotic theory of certain "goodness-of-fit" criteria based on stochastic processes" Ann. Math. Stat. , 23 (1952) pp. 193–212 |
| [a2] | T.W. Anderson, D.A. Darling, "A test of goodness-of-fit" J. Amer. Statist. Assoc. , 49 (1954) pp. 765–769 |
| [a3] | L. Baringhaus, R. Danschke, N. Henze, "Recent and classical tests for normality: a comparative study" Comm. Statist. Simulation Comput. , 18 (1989) pp. 363–379 |
| [a4] | L. Baringhaus, N. Henze, "An adaptive omnibus test for exponentiality" Comm. Statist. Th. Methods , 21 (1992) pp. 969–978 |
| [a5] | F.C. Drost, W.C.M. Kallenberg, J. Oosterhoff, "The power of EDF tests to fit under non-robust estimation of nuisance parameters" Statistics and Decision , 8 (1990) pp. 167–182 |
| [a6] | F.F. Gan, K.J. Koehler, "Goodness-of-fit tests based on 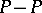 probability plots" Technometrics , 32 (1990) pp. 289–303 probability plots" Technometrics , 32 (1990) pp. 289–303 |
| [a7] | Ya.Yu. Nikitin, "Asymptotic efficiency of nonparametric tests" , Cambridge Univ. Press (1995) |
Anderson-Darling statistic. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Anderson-Darling_statistic&oldid=22021