Difference between revisions of "Conjugate gradients, method of"
(Importing text file) |
Ulf Rehmann (talk | contribs) m (tex encoded by computer) |
||
| Line 1: | Line 1: | ||
| + | <!-- | ||
| + | c0250301.png | ||
| + | $#A+1 = 45 n = 1 | ||
| + | $#C+1 = 45 : ~/encyclopedia/old_files/data/C025/C.0205030 Conjugate gradients, method of, | ||
| + | Automatically converted into TeX, above some diagnostics. | ||
| + | Please remove this comment and the {{TEX|auto}} line below, | ||
| + | if TeX found to be correct. | ||
| + | --> | ||
| + | |||
| + | {{TEX|auto}} | ||
| + | {{TEX|done}} | ||
| + | |||
''conjugate-gradient method'' | ''conjugate-gradient method'' | ||
| − | A method of solving a system of linear algebraic equations | + | A method of solving a system of linear algebraic equations $ Ax = b $ |
| + | where $ A $ | ||
| + | is a positive-definite (symmetric) matrix. This is at the same time a direct and an iterative method: for any initial approximation, it converges after a finite number of iterations to give the exact solution. In this method the matrix of the system does not change in the process of calculation and at every iteration it is only used to multiply a vector. Therefore, the order of systems that can be solved on computers is high, being determined by the amount of numerical information needed to specify the matrix. | ||
| − | As a direct method, its structure is based on the process of sequential | + | As a direct method, its structure is based on the process of sequential $ A $- |
| + | orthogonalization of a set of vectors, and is an ordinary orthogonalization process (see [[Orthogonalization method|Orthogonalization method]]) with respect to the scalar product $ ( x, y) = x ^ {T} A y $. | ||
| + | If $ \{ s _ {i} \dots s _ {n} \} $ | ||
| + | is an $ A $- | ||
| + | orthogonal basis of the space, then for any initial approximation $ x _ {0} $, | ||
| + | the exact solution $ x ^ {*} $ | ||
| + | of the system can be obtained from the decomposition | ||
| − | + | $$ | |
| + | x ^ {*} - x _ {0} = \ | ||
| + | \sum _ {j = 1 } ^ { n } | ||
| + | \alpha _ {j} s _ {j} ,\ \ | ||
| + | \alpha _ {j} = \ | ||
| − | + | \frac{( r _ {0} , s _ {j} ) }{( s _ {j} , As _ {j} ) } | |
| + | , | ||
| + | $$ | ||
| − | + | where $ r _ {0} = b - Ax _ {0} $ | |
| + | is the discrepancy of $ x _ {0} $. | ||
| + | In the conjugate-gradient method, the $ A $- | ||
| + | orthogonal vectors $ s _ {1} \dots s _ {n} $ | ||
| + | are constructed by $ A $- | ||
| + | orthogonalizing the discrepancies $ r _ {0} \dots r _ {n - 1 } $ | ||
| + | of the sequence of approximations $ x _ {0} \dots x _ {n - 1 } $, | ||
| + | given by the formulas | ||
| − | + | $$ | |
| + | x _ {k} = x _ {0} + | ||
| + | \sum _ {j = 1 } ^ { k } | ||
| + | \alpha _ {j} s _ {j} ,\ \ | ||
| + | \alpha _ {j} = \ | ||
| − | + | \frac{( r _ {0} , s _ {j} ) }{( s _ {j} , As _ {j} ) } | |
| + | . | ||
| + | $$ | ||
| + | |||
| + | The vectors $ r _ {0} \dots r _ {n - 1 } $ | ||
| + | and $ s _ {1} \dots s _ {n} $ | ||
| + | constructed in this way have the following properties: | ||
| + | |||
| + | $$ \tag{1 } | ||
| + | ( r _ {i} , r _ {j} ) = 0,\ | ||
| + | i \neq j; \ \ | ||
| + | ( r _ {i} , s _ {j} ) = 0,\ \ | ||
| + | j = 1 \dots i. | ||
| + | $$ | ||
The conjugate-gradient method is now defined by the following recurrence relations (see [[#References|[1]]]): | The conjugate-gradient method is now defined by the following recurrence relations (see [[#References|[1]]]): | ||
| − | + | $$ \tag{2 } | |
| + | \left . | ||
| − | + | \begin{array}{c} | |
| + | s _ {1} = r _ {0} ; \ \ | ||
| + | x _ {i} = x _ {i - 1 } + \alpha _ {i} s _ {i} ,\ \ | ||
| + | \alpha _ {i} = - | ||
| − | + | \frac{( s _ {i} , r _ {i - 1 } ) }{( s _ {i} , As _ {i} ) } | |
| + | , \\ | ||
| + | r _ {i} = r _ {i - 1 } + \alpha _ {i} As _ {i} ,\ \ | ||
| + | s _ {i + 1 } = r _ {i} + \beta _ {i} s _ {i} , \\ | ||
| + | \beta _ {i} = - | ||
| − | This method and its analogues have many different names, such as the Lanczos method, the Hestenes method, the Stiefel method, etc. Of all the methods for minimizing a functional, the conjugate-gradient method is best in strategic layout: it gives the maximal minimization after | + | \frac{( r _ {i} , As _ {i} ) }{( s _ {i} , As _ {i} ) } |
| + | . \\ | ||
| + | \end{array} | ||
| + | \ | ||
| + | \right \} | ||
| + | $$ | ||
| + | |||
| + | The process ends at some $ k \leq n $ | ||
| + | for which $ r _ {k} = 0 $. | ||
| + | Then $ x ^ {*} = x _ {k} $. | ||
| + | The cut-off point is determined by the initial approximation $ x _ {0} $. | ||
| + | It follows from the recurrence relations (2) that the vectors $ r _ {0} \dots r _ {i} $ | ||
| + | are linear combinations of the vectors $ r _ {0} $, | ||
| + | $ Ar _ {0} \dots A ^ {i} r _ {0} $. | ||
| + | Since the vectors $ r _ {0} \dots r _ {i} $ | ||
| + | are orthogonal, $ r _ {i} $ | ||
| + | can only vanish when the vectors $ r _ {0} $, | ||
| + | $ Ar _ {0} \dots A ^ {i} r _ {0} $ | ||
| + | are linearly dependent, as occurs for example when there are only $ i $ | ||
| + | non-zero components in the decomposition of $ r _ {0} $ | ||
| + | with respect to a basis of eigen vectors of $ A $. | ||
| + | This consideration can influence the choice of initial approximation. | ||
| + | |||
| + | The conjugate-gradient method is related to a class of methods in which for a solution a vector that minimizes some functional is taken. To calculate this vector an iterated sequence is constructed that converges to the minimum point. The sequence $ x _ {0} \dots x _ {n} $ | ||
| + | in (2) realizes a minimization of the functional $ f ( x) = ( Ax, x) - 2 ( b, x) $. | ||
| + | At the $ i $- | ||
| + | th step of the process (2) the vector $ s _ {i} $ | ||
| + | coincides with the direction of steepest descent (in gradient) of the surface $ f ( x) = c $ | ||
| + | on the $ ( n - i) $- | ||
| + | dimensional ellipsoid formed by intersecting the surface with the plane conjugate to the directions $ s _ {1} \dots s _ {i - 1 } $. | ||
| + | |||
| + | This method and its analogues have many different names, such as the Lanczos method, the Hestenes method, the Stiefel method, etc. Of all the methods for minimizing a functional, the conjugate-gradient method is best in strategic layout: it gives the maximal minimization after $ n $ | ||
| + | steps. However, the calculations (2) under real conditions of machine arithmetic are sensitive to rounding-off errors, and the conditions (1) may be violated. This prevents termination of the process after $ n $ | ||
| + | steps. Therefore the method is continued beyond $ n $ | ||
| + | iterations, and it can be regarded as an infinite iterative process for minimizing a functional. Modifications of the calculating scheme (2) that are more resistant to rounding-off errors are known (see [[#References|[3]]], [[#References|[4]]]). | ||
====References==== | ====References==== | ||
<table><TR><TD valign="top">[1]</TD> <TD valign="top"> D.K. Faddeev, V.N. Faddeeva, "Computational methods of linear algebra" , Freeman (1963) (Translated from Russian)</TD></TR><TR><TD valign="top">[2]</TD> <TD valign="top"> I.S. Berezin, N.P. Zhidkov, "Computing methods" , Pergamon (1973) (Translated from Russian)</TD></TR><TR><TD valign="top">[3]</TD> <TD valign="top"> V.V. Voevodin, "Numerical methods of algebra" , Moscow (1966) (In Russian)</TD></TR><TR><TD valign="top">[4]</TD> <TD valign="top"> N.S. Bakhvalov, "Numerical methods: analysis, algebra, ordinary differential equations" , MIR (1977) (Translated from Russian)</TD></TR></table> | <table><TR><TD valign="top">[1]</TD> <TD valign="top"> D.K. Faddeev, V.N. Faddeeva, "Computational methods of linear algebra" , Freeman (1963) (Translated from Russian)</TD></TR><TR><TD valign="top">[2]</TD> <TD valign="top"> I.S. Berezin, N.P. Zhidkov, "Computing methods" , Pergamon (1973) (Translated from Russian)</TD></TR><TR><TD valign="top">[3]</TD> <TD valign="top"> V.V. Voevodin, "Numerical methods of algebra" , Moscow (1966) (In Russian)</TD></TR><TR><TD valign="top">[4]</TD> <TD valign="top"> N.S. Bakhvalov, "Numerical methods: analysis, algebra, ordinary differential equations" , MIR (1977) (Translated from Russian)</TD></TR></table> | ||
| − | |||
| − | |||
====Comments==== | ====Comments==== | ||
Latest revision as of 17:46, 4 June 2020
conjugate-gradient method
A method of solving a system of linear algebraic equations $ Ax = b $ where $ A $ is a positive-definite (symmetric) matrix. This is at the same time a direct and an iterative method: for any initial approximation, it converges after a finite number of iterations to give the exact solution. In this method the matrix of the system does not change in the process of calculation and at every iteration it is only used to multiply a vector. Therefore, the order of systems that can be solved on computers is high, being determined by the amount of numerical information needed to specify the matrix.
As a direct method, its structure is based on the process of sequential $ A $- orthogonalization of a set of vectors, and is an ordinary orthogonalization process (see Orthogonalization method) with respect to the scalar product $ ( x, y) = x ^ {T} A y $. If $ \{ s _ {i} \dots s _ {n} \} $ is an $ A $- orthogonal basis of the space, then for any initial approximation $ x _ {0} $, the exact solution $ x ^ {*} $ of the system can be obtained from the decomposition
$$ x ^ {*} - x _ {0} = \ \sum _ {j = 1 } ^ { n } \alpha _ {j} s _ {j} ,\ \ \alpha _ {j} = \ \frac{( r _ {0} , s _ {j} ) }{( s _ {j} , As _ {j} ) } , $$
where $ r _ {0} = b - Ax _ {0} $ is the discrepancy of $ x _ {0} $. In the conjugate-gradient method, the $ A $- orthogonal vectors $ s _ {1} \dots s _ {n} $ are constructed by $ A $- orthogonalizing the discrepancies $ r _ {0} \dots r _ {n - 1 } $ of the sequence of approximations $ x _ {0} \dots x _ {n - 1 } $, given by the formulas
$$ x _ {k} = x _ {0} + \sum _ {j = 1 } ^ { k } \alpha _ {j} s _ {j} ,\ \ \alpha _ {j} = \ \frac{( r _ {0} , s _ {j} ) }{( s _ {j} , As _ {j} ) } . $$
The vectors $ r _ {0} \dots r _ {n - 1 } $ and $ s _ {1} \dots s _ {n} $ constructed in this way have the following properties:
$$ \tag{1 } ( r _ {i} , r _ {j} ) = 0,\ i \neq j; \ \ ( r _ {i} , s _ {j} ) = 0,\ \ j = 1 \dots i. $$
The conjugate-gradient method is now defined by the following recurrence relations (see [1]):
$$ \tag{2 } \left . \begin{array}{c} s _ {1} = r _ {0} ; \ \ x _ {i} = x _ {i - 1 } + \alpha _ {i} s _ {i} ,\ \ \alpha _ {i} = - \frac{( s _ {i} , r _ {i - 1 } ) }{( s _ {i} , As _ {i} ) } , \\ r _ {i} = r _ {i - 1 } + \alpha _ {i} As _ {i} ,\ \ s _ {i + 1 } = r _ {i} + \beta _ {i} s _ {i} , \\ \beta _ {i} = - \frac{( r _ {i} , As _ {i} ) }{( s _ {i} , As _ {i} ) } . \\ \end{array} \ \right \} $$
The process ends at some $ k \leq n $ for which $ r _ {k} = 0 $. Then $ x ^ {*} = x _ {k} $. The cut-off point is determined by the initial approximation $ x _ {0} $. It follows from the recurrence relations (2) that the vectors $ r _ {0} \dots r _ {i} $ are linear combinations of the vectors $ r _ {0} $, $ Ar _ {0} \dots A ^ {i} r _ {0} $. Since the vectors $ r _ {0} \dots r _ {i} $ are orthogonal, $ r _ {i} $ can only vanish when the vectors $ r _ {0} $, $ Ar _ {0} \dots A ^ {i} r _ {0} $ are linearly dependent, as occurs for example when there are only $ i $ non-zero components in the decomposition of $ r _ {0} $ with respect to a basis of eigen vectors of $ A $. This consideration can influence the choice of initial approximation.
The conjugate-gradient method is related to a class of methods in which for a solution a vector that minimizes some functional is taken. To calculate this vector an iterated sequence is constructed that converges to the minimum point. The sequence $ x _ {0} \dots x _ {n} $ in (2) realizes a minimization of the functional $ f ( x) = ( Ax, x) - 2 ( b, x) $. At the $ i $- th step of the process (2) the vector $ s _ {i} $ coincides with the direction of steepest descent (in gradient) of the surface $ f ( x) = c $ on the $ ( n - i) $- dimensional ellipsoid formed by intersecting the surface with the plane conjugate to the directions $ s _ {1} \dots s _ {i - 1 } $.
This method and its analogues have many different names, such as the Lanczos method, the Hestenes method, the Stiefel method, etc. Of all the methods for minimizing a functional, the conjugate-gradient method is best in strategic layout: it gives the maximal minimization after $ n $ steps. However, the calculations (2) under real conditions of machine arithmetic are sensitive to rounding-off errors, and the conditions (1) may be violated. This prevents termination of the process after $ n $ steps. Therefore the method is continued beyond $ n $ iterations, and it can be regarded as an infinite iterative process for minimizing a functional. Modifications of the calculating scheme (2) that are more resistant to rounding-off errors are known (see [3], [4]).
References
| [1] | D.K. Faddeev, V.N. Faddeeva, "Computational methods of linear algebra" , Freeman (1963) (Translated from Russian) |
| [2] | I.S. Berezin, N.P. Zhidkov, "Computing methods" , Pergamon (1973) (Translated from Russian) |
| [3] | V.V. Voevodin, "Numerical methods of algebra" , Moscow (1966) (In Russian) |
| [4] | N.S. Bakhvalov, "Numerical methods: analysis, algebra, ordinary differential equations" , MIR (1977) (Translated from Russian) |
Comments
The Stiefel method is related to the Zukhovitskii method for the minimax solution of a linear system, cf. [a1].
Modifications of the method of steepest descent can be found in [a1], [a12].
The classic reference for the conjugate-gradient method is [a4]. An up-to-date discussion with additional references is [a3]. Its relation with matrix factorization is discussed in [a9].
It appears that J.K. Reid was the first to use this method as an iterative method (cf. [a8]).
Several modifications have been proposed. E.g. the pre-conditioned conjugate-gradient method (cf. [a2]), and conjugate-gradient methods using incomplete Cholesky factorization (so-called ICCG methods, cf. [a7] and [a6]).
Extensions to non-symmetric conjugate-gradient methods are discussed in [a1] and [a10].
References
| [a1] | O. Axelsson, "Conjugate gradient type methods for unsymmetric and inconsistent systems of linear equations" Lin. Alg. and its Appl. , 34 (1980) pp. 1–66 |
| [a2] | P. Concus, G.H. Golub, D.P. O'Leary, "A generalized conjugate gradient method for the numerical solution of elliptic partial differential equations" J.R. Bunch (ed.) D.J. Rose (ed.) , Sparse matrix computations , Acad. Press (1976) |
| [a3] | G.H. Golub, C.F. van Loan, "Matrix computations" , North Oxford Acad. (1983) |
| [a4] | M.R. Hestenes, "Conjugate directions methods in optimization" , Springer (1980) |
| [a5] | M.R. Hestenes, E. Stiefel, "Methods of conjugate gradients for solving linear systems" J. Res. Nat. Bur. Stand. , 49 (1952) pp. 409–436 |
| [a6] | T.A. Manteuffel, "Shifted incomplete Cholesky factorization" I.S. Duff (ed.) G.W. Stewart (ed.) , Sparse matrix proceedings , SIAM Publ. (1979) |
| [a7] | J.A. Meijerink, H.A. van der Vorst, "An iterative solution method for linear systems of which the coefficient matrix is a symmetric 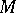 -matrix" Math. Comp. , 31 (1977) pp. 148–162 -matrix" Math. Comp. , 31 (1977) pp. 148–162 |
| [a8] | J.K. Reid, "On the method of conjugate gradients for the solution of large systems of linear equations" J.K. Reid (ed.) , Large sparse sets of linear equations , Acad. Press (1971) |
| [a9] | G.W. Stewart, "Conjugate gradients methods for solving systems of linear equations" Numerical Math. , 21 (1973) pp. 284–297 |
| [a10] | D.M. Young, K.C. Jea, "Generalized conjugate gradient acceleration of non-symmetrizable iterative methods" Lin. Alg. and its Appl. , 34 (1980) pp. 159–194 |
| [a11] | S.I. [S.I. Zukhovitskii] Zukhovitsky, L.I. Avdeeva, "Linear and convex programming" , Saunders (1966) |
| [a12] | G. Zoutendijk, "Methods of feasible directions" , Elsevier (1960) |
Conjugate gradients, method of. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Conjugate_gradients,_method_of&oldid=15751