Statistical estimator
A function of random variables that can be used in estimating unknown parameters of a theoretical probability distribution. Methods of the theory of statistical estimation form the basis of the modern theory of errors; physical constants to be measured are commonly used as the unknown parameters, while the results of direct measurements subject to random errors are taken as the random variables. For example, if 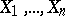 are independent, identically normally distributed random variables (the results of equally accurate measurements subject to independent normally distributed random errors), then for the unknown mean value
are independent, identically normally distributed random variables (the results of equally accurate measurements subject to independent normally distributed random errors), then for the unknown mean value  (the value of an approximately measurable physical constant) the arithmetical mean
(the value of an approximately measurable physical constant) the arithmetical mean
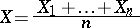 | (1) |
is taken as the statistical estimator.
A statistical estimator as a function of random variables is most frequently given by formulas, the choice of which is prescribed by practical requirements. A distinction must be made here between point and interval estimators.
Point estimators.
A point estimator is a statistical estimator whose value can be represented geometrically in the form of a point in the same space as the values of the unknown parameters (the dimension of the space is equal to the number of parameters to be estimated). In fact, point estimators are also used as approximate values for unknown physical variables. For the sake of simplicity, it is further supposed that one natural parameter is subject to estimation; in this case, a point estimator is a function of the results of observations, and takes numerical values.
A point estimator is said to be unbiased if its mathematical expectation coincides with the parameter being estimated, i.e. if the statistical estimation is free of systematic errors. The arithmetical mean (1) is an unbiased statistical estimator for the mathematical expectation of identically-distributed random variables 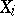 (not necessarily normal). At the same time, the sample variance
(not necessarily normal). At the same time, the sample variance
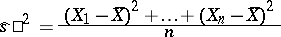 | (2) |
is a biased statistical estimator for the variance 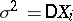 , since
, since 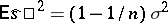 ; the function
; the function
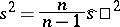 |
is usually taken as the unbiased statistical estimator for 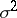 .
.
See also Unbiased estimator.
As a measure of the accuracy of the unbiased statistical estimator 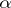 for a parameter
for a parameter  one most often uses the variance
one most often uses the variance 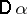 .
.
The statistical estimator with smallest variance is called the best. In the example quoted, the arithmetical mean (1) is the best statistical estimator. However, if the probability distribution of the random variables 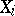 is different from normal, then (1) need not be the best statistical estimator. For example, if the results of the observations of
is different from normal, then (1) need not be the best statistical estimator. For example, if the results of the observations of 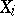 are uniformly distributed in an interval
are uniformly distributed in an interval 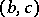 , then the best statistical estimator for the mathematical expectation
, then the best statistical estimator for the mathematical expectation 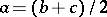 will be half the sum of the boundary values:
will be half the sum of the boundary values:
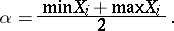 | (3) |
The criterion for the comparison of the accuracy of different statistical estimators ordinarily used is the relative efficiency — the ratio of the variances of the best estimator and the given unbiased estimator. For example, if the results of the observations of 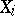 are uniformly distributed, then the variances of the estimators (1) and (3) are expressed by the formulas
are uniformly distributed, then the variances of the estimators (1) and (3) are expressed by the formulas
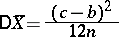 |
and
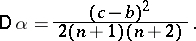 | (4) |
Since (3) is the best estimator, the relative efficiency of the estimator (1) in the given case is
 |
For a large number of observations  , it is usually required that the chosen statistical estimator tends in probability to the true value of the parameter
, it is usually required that the chosen statistical estimator tends in probability to the true value of the parameter  , i.e. that for every
, i.e. that for every 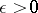 ,
,
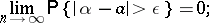 |
such statistical estimators are called consistent (for example, any unbiased estimator with variance tending to zero, when 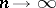 , is consistent; see also Consistent estimator). Insofar as the order of tendency to the limit is of significance, the asymptotically best estimators are the asymptotically efficient statistical estimators, i.e. those for which
, is consistent; see also Consistent estimator). Insofar as the order of tendency to the limit is of significance, the asymptotically best estimators are the asymptotically efficient statistical estimators, i.e. those for which
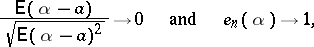 |
when 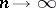 . For example, if
. For example, if 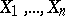 are identically normally distributed, then (2) is an asymptotically efficient estimator for the unknown parameter
are identically normally distributed, then (2) is an asymptotically efficient estimator for the unknown parameter 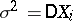 , since, when
, since, when 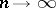 , the variance of
, the variance of 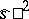 and that of the best estimator
and that of the best estimator 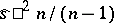 are asymptotically equivalent:
are asymptotically equivalent:
 |
and, moreover,
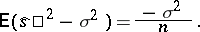 |
Of prime importance in the theory of statistical estimation and its applications is the fact that the quadratic deviation of a statistical estimator for a parameter  is bounded from below by a certain quantity (R. Fisher proposed that this quantity be characterized by the amount of information regarding the unknown parameter
is bounded from below by a certain quantity (R. Fisher proposed that this quantity be characterized by the amount of information regarding the unknown parameter  contained in the results of the observations). For example, if
contained in the results of the observations). For example, if 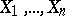 are independent and identically distributed, with probability density
are independent and identically distributed, with probability density 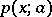 , and if
, and if 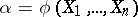 is a statistical estimator for a certain function
is a statistical estimator for a certain function 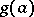 of the parameter
of the parameter  , then in a broad class of cases
, then in a broad class of cases
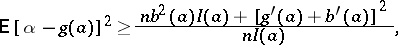 | (5) |
where
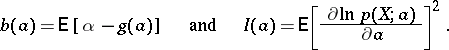 |
The function 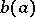 is called the bias, while the quantity inverse to the right-hand side of inequality (5) is called the Fisher information, with respect to the function
is called the bias, while the quantity inverse to the right-hand side of inequality (5) is called the Fisher information, with respect to the function 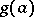 , contained in the results of the observations. In particular, if
, contained in the results of the observations. In particular, if 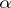 is an unbiased statistical estimator of the parameter
is an unbiased statistical estimator of the parameter  , then
, then
 |
and
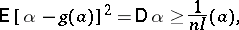 | (6) |
whereby the information 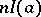 in this instance is proportional to the number of observations (the function
in this instance is proportional to the number of observations (the function 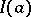 is called the information contained in one observation).
is called the information contained in one observation).
The basic conditions under which the inequalities (5) and (6) hold are smoothness of the estimator 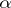 as a function of
as a function of  , and the independence of the parameter
, and the independence of the parameter  of the set of those points
of the set of those points  where
where 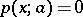 . The latter condition is not fulfilled, for example, in the case of a uniform distribution, and the variance of the estimator (3) does therefore not satisfy inequality (6) (according to (4), this variance is a quantity of order
. The latter condition is not fulfilled, for example, in the case of a uniform distribution, and the variance of the estimator (3) does therefore not satisfy inequality (6) (according to (4), this variance is a quantity of order 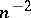 , while, according to inequality (6), it cannot have an order of smallness higher than
, while, according to inequality (6), it cannot have an order of smallness higher than  ).
).
The inequalities (5) and (6) also hold for discretely distributed random variables 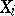 : In defining the information
: In defining the information 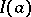 , the density
, the density  must be replaced by the probability of the event
must be replaced by the probability of the event 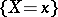 .
.
If the variance of an unbiased statistical estimator 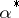 for the parameter
for the parameter  coincides with the right-hand side of inequality (6), then
coincides with the right-hand side of inequality (6), then  is the best estimator. The converse assertion, generally speaking, is not true: The variance of the best statistical estimator can exceed
is the best estimator. The converse assertion, generally speaking, is not true: The variance of the best statistical estimator can exceed 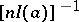 . However, as
. However, as 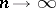 , the variance of the best estimator,
, the variance of the best estimator, 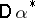 , is asymptotically equivalent to the right-hand side of (6), i.e.
, is asymptotically equivalent to the right-hand side of (6), i.e. 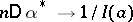 . In this way, using the Fisher information, it is possible to define the asymptotic efficiency of an unbiased statistical estimator
. In this way, using the Fisher information, it is possible to define the asymptotic efficiency of an unbiased statistical estimator 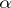 , by proposing
, by proposing
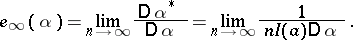 | (7) |
One information approach to the theory of statistical estimators which proves to be particularly fruitful is that where the density (in the discrete instance, the probability) of the joint distribution of the random variables 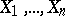 can be represented in the form of the product of two functions
can be represented in the form of the product of two functions 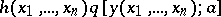 , the first of which does not depend on
, the first of which does not depend on  while the second is the density of the distribution of a certain random variable
while the second is the density of the distribution of a certain random variable 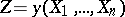 , called a sufficient statistic.
, called a sufficient statistic.
One of the most frequently used methods of finding point estimators is the method of moments (cf. Moments, method of (in probability theory)). According to this method, a theoretical distribution dependent on unknown parameters corresponds to a discrete sample distribution, which is defined by the results of observations of 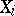 and which is the probability distribution of a theoretical random variable which takes the values
and which is the probability distribution of a theoretical random variable which takes the values  with identical probabilities equal to
with identical probabilities equal to 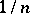 (the sample distribution can be seen as a point estimator for the theoretical distribution). The statistical estimator for the moments of a theoretical distribution is taken to be that of the corresponding moments of the sample distribution; for example, for the mathematical expectation
(the sample distribution can be seen as a point estimator for the theoretical distribution). The statistical estimator for the moments of a theoretical distribution is taken to be that of the corresponding moments of the sample distribution; for example, for the mathematical expectation  and variance
and variance 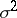 , the method of moments provides the following statistical estimators: the sample mean (1) and the sample variance (2). The unknown parameters are usually expressed (exactly or approximately) in the form of functions of several moments of the theoretical distribution. By replacing theoretical moments in these functions by sample moments, the required statistical estimators are obtained. This method, which in practice often reduces to comparatively simple calculations, generally gives a statistical estimator of low asymptotic efficiency (see the above example of the estimator of the mathematical expectation of a uniform distribution).
, the method of moments provides the following statistical estimators: the sample mean (1) and the sample variance (2). The unknown parameters are usually expressed (exactly or approximately) in the form of functions of several moments of the theoretical distribution. By replacing theoretical moments in these functions by sample moments, the required statistical estimators are obtained. This method, which in practice often reduces to comparatively simple calculations, generally gives a statistical estimator of low asymptotic efficiency (see the above example of the estimator of the mathematical expectation of a uniform distribution).
Another method for finding statistical estimators, which is more complete from the theoretical point of view, is the maximum-likelihood method. According to this method, the likelihood function 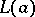 is considered, which is a function of the unknown parameter
is considered, which is a function of the unknown parameter  , and which is obtained as a result of substituting the random variables
, and which is obtained as a result of substituting the random variables 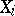 in the density
in the density 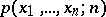 of the joint distribution for the arguments; if the
of the joint distribution for the arguments; if the 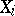 are independent and identically distributed with probability density
are independent and identically distributed with probability density 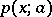 , then
, then
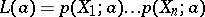 |
(if the 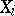 are discretely distributed, then in defining the likelihood function
are discretely distributed, then in defining the likelihood function 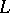 the density should be replaced by the probability of the events
the density should be replaced by the probability of the events  ). The variable
). The variable 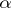 for which
for which  has its largest value is used as the maximum-likelihood estimator for the unknown parameter
has its largest value is used as the maximum-likelihood estimator for the unknown parameter  (instead of
(instead of 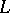 , the so-called logarithmic likelihood function is often considered:
, the so-called logarithmic likelihood function is often considered: 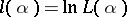 ; owing to the monotone nature of the logarithm, the maximum points of
; owing to the monotone nature of the logarithm, the maximum points of 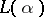 and
and 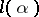 coincide).
coincide).
The basic merit of maximum-likelihood estimators lies in the fact that, given certain general conditions, they are consistent, asymptotically efficient and approximately normally distributed. These properties mean that if 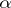 is a maximum-likelihood estimator, then, when
is a maximum-likelihood estimator, then, when 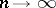 ,
,
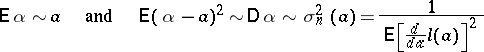 |
(if the 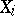 are independent, then
are independent, then 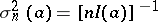 ). Thus, for the distribution function of a normalized statistical estimator
). Thus, for the distribution function of a normalized statistical estimator  , the limit relation
, the limit relation
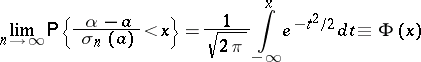 | (8) |
holds.
The advantages of the maximum-likelihood estimator justify the amount of calculation involved in seeking the maximum of the function  (or
(or 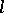 ). In certain cases, the amount of calculation is greatly reduced as a result of the following properties: firstly, if
). In certain cases, the amount of calculation is greatly reduced as a result of the following properties: firstly, if 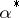 is a statistical estimator for which inequality (6) becomes an equality, then the maximum-likelihood estimator is unique and coincides with
is a statistical estimator for which inequality (6) becomes an equality, then the maximum-likelihood estimator is unique and coincides with 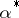 ; secondly, if a sufficient statistic
; secondly, if a sufficient statistic 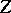 exists, then the maximum-likelihood estimator is a function of
exists, then the maximum-likelihood estimator is a function of 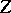 .
.
For example, let 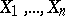 be independent and normally distributed, and such that
be independent and normally distributed, and such that
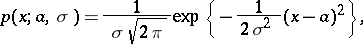 |
then
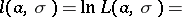 |
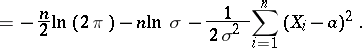 |
The coordinates 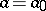 and
and 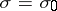 of the maximum point of the function
of the maximum point of the function 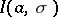 satisfy the system of equations
satisfy the system of equations
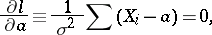 |
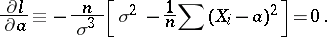 |
Thus, 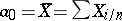 ,
, 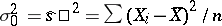 , and in the given case (1) and (2) are maximum-likelihood estimators, whereby
, and in the given case (1) and (2) are maximum-likelihood estimators, whereby 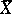 is the best statistical estimator of the parameter
is the best statistical estimator of the parameter  , normally distributed (
, normally distributed (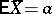 ,
, 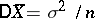 ), while
), while 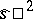 is an asymptotically efficient statistical estimator of the parameter
is an asymptotically efficient statistical estimator of the parameter 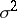 , distributed approximately normally for large
, distributed approximately normally for large  (
(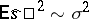 ,
, 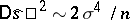 ). Both estimators are independent sufficient statistics.
). Both estimators are independent sufficient statistics.
As a further example, suppose that
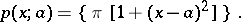 |
This density gives a satisfactory description of the distribution of one of the coordinates of the particles reaching a plane screen and emanating from a point outside the screen ( is the coordinate of the projection of the source onto the screen, and is presumed to be unknown). The mathematical expectation of this distribution does not exist, since the corresponding integral is divergent. For this reason it is not possible to find a statistical estimator of
is the coordinate of the projection of the source onto the screen, and is presumed to be unknown). The mathematical expectation of this distribution does not exist, since the corresponding integral is divergent. For this reason it is not possible to find a statistical estimator of  by means of the method of moments. The formal use of the arithmetical mean (1) as a statistical estimator is meaningless, since
by means of the method of moments. The formal use of the arithmetical mean (1) as a statistical estimator is meaningless, since  is distributed in the given instance with the same density
is distributed in the given instance with the same density 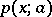 as every single result of the observations. For estimation of
as every single result of the observations. For estimation of  it is possible to make use of the property that the distribution in question is symmetric relative to the point
it is possible to make use of the property that the distribution in question is symmetric relative to the point  , where
, where  is the median of the theoretical distribution. By slightly modifying the method of moments, the sample median
is the median of the theoretical distribution. By slightly modifying the method of moments, the sample median 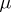 can be used as a statistical estimator. When
can be used as a statistical estimator. When 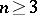 , it is unbiased for
, it is unbiased for  and if
and if  is large,
is large,  is distributed approximately normally with variance
is distributed approximately normally with variance
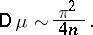 |
At the same time,
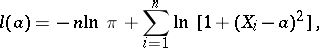 |
thus 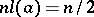 and, according to (7), the asymptotic efficiency
and, according to (7), the asymptotic efficiency 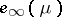 is equal to
is equal to 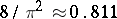 . Thus, in order that the sample median
. Thus, in order that the sample median 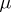 is as accurate a statistical estimator for
is as accurate a statistical estimator for  as the maximum-likelihood estimator
as the maximum-likelihood estimator 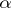 , the number of observations has to be increased by
, the number of observations has to be increased by 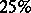 . If the losses in the experiment are great, then, in the definition of
. If the losses in the experiment are great, then, in the definition of  , that statistical estimator
, that statistical estimator 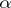 must be used, which, in the given case, is defined as the root of the equation
must be used, which, in the given case, is defined as the root of the equation
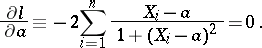 |
As a first approximation, 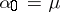 is used, and this equation is then solved by successive approximation using the formula
is used, and this equation is then solved by successive approximation using the formula
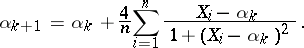 |
See also Point estimator.
Interval estimators.
An interval estimator is a statistical estimator which is represented geometrically as a set of points in the parameter space. An interval estimator can be seen as a set of point estimators. This set depends on the results of observations, and is consequently random; every interval estimator is therefore (partly) characterized by the probability with which this estimator will "cover" the unknown parameter point. This probability, in general, depends on unknown parameters; therefore, as a characteristic of the reliability of an interval estimator a confidence coefficient is used; this is the lowest possible value of the given probability. Interesting statistical conclusions can be drawn for only those interval estimators which have a confidence coefficient close to one.
If a single parameter  is estimated, then an interval estimator is usually a certain interval
is estimated, then an interval estimator is usually a certain interval 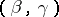 (the so-called confidence interval), the end-points
(the so-called confidence interval), the end-points 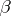 and
and 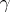 of which are functions of the observations; the confidence coefficient
of which are functions of the observations; the confidence coefficient 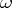 in the given case is defined as the lower bound of the probability of the simultaneous realization of the two events
in the given case is defined as the lower bound of the probability of the simultaneous realization of the two events 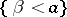 and
and  , which can be calculated using all possible values of the parameter
, which can be calculated using all possible values of the parameter  :
:
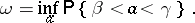 |
If the mid-point 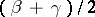 of such an interval is taken as a point estimator for the parameter
of such an interval is taken as a point estimator for the parameter  , then it can be claimed, with probability not less that
, then it can be claimed, with probability not less that 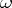 , that the absolute error of this statistical estimator does not exceed half the length of the interval,
, that the absolute error of this statistical estimator does not exceed half the length of the interval, 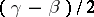 . In other words, if one is guided by the rule of estimation of the absolute error, then an erroneous conclusion will be obtained on the average in less than
. In other words, if one is guided by the rule of estimation of the absolute error, then an erroneous conclusion will be obtained on the average in less than 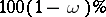 of the cases. Given a fixed confidence coefficient
of the cases. Given a fixed confidence coefficient 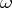 , the most suitable are the shortest confidence intervals for which the mathematical expectation of the length
, the most suitable are the shortest confidence intervals for which the mathematical expectation of the length 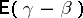 attains its lowest value.
attains its lowest value.
If the distribution of random variables 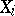 depends only on one unknown parameter
depends only on one unknown parameter  , then the construction of the confidence interval is usually realized by the use of a certain point estimator
, then the construction of the confidence interval is usually realized by the use of a certain point estimator  . For the majority of cases of practical interest, the distribution function
. For the majority of cases of practical interest, the distribution function 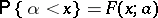 of a sensibly chosen statistical estimator
of a sensibly chosen statistical estimator 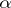 depends monotonically on the parameter
depends monotonically on the parameter  . Under these conditions, when seeking an interval estimator it makes sense to insert
. Under these conditions, when seeking an interval estimator it makes sense to insert 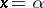 in
in 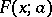 and to determine the roots
and to determine the roots 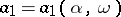 and
and 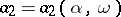 of the equations
of the equations
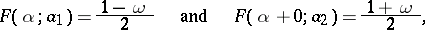 | (9) |
where
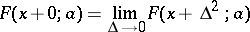 |
(for continuous distributions 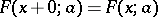 ). The points with coordinates
). The points with coordinates 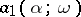 and
and 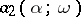 bound the confidence interval with confidence coefficient
bound the confidence interval with confidence coefficient 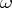 . It is reasonable to expect that such a simply constructed interval differs in many cases from the optimal (shortest) interval. However, if
. It is reasonable to expect that such a simply constructed interval differs in many cases from the optimal (shortest) interval. However, if 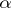 is an asymptotically efficient statistical estimator for
is an asymptotically efficient statistical estimator for  , then, given a sufficiently large number of observations, such an interval estimator differs from the optimal, although in practice the difference is immaterial. This is particularly true for maximum-likelihood estimators, since they are asymptotically normally distributed (see (8)). In cases where solving the equations (9) is difficult, the interval estimator is calculated approximately, using a maximum-likelihood point estimator and the relation (8):
, then, given a sufficiently large number of observations, such an interval estimator differs from the optimal, although in practice the difference is immaterial. This is particularly true for maximum-likelihood estimators, since they are asymptotically normally distributed (see (8)). In cases where solving the equations (9) is difficult, the interval estimator is calculated approximately, using a maximum-likelihood point estimator and the relation (8):
 |
where  is the root of the equation
is the root of the equation 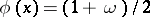 .
.
If 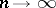 , then the true confidence coefficient of the interval estimator
, then the true confidence coefficient of the interval estimator 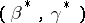 tends to
tends to 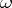 . In a more general case, the distribution of the results of observations
. In a more general case, the distribution of the results of observations 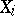 depends on various parameters
depends on various parameters 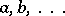 . Then the above rules for the construction of confidence intervals often prove to be not feasible, since the distribution of a point estimator
. Then the above rules for the construction of confidence intervals often prove to be not feasible, since the distribution of a point estimator 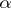 depends, as a rule, not only on
depends, as a rule, not only on  , but also on other parameters. However, in cases of practical interest the statistical estimator
, but also on other parameters. However, in cases of practical interest the statistical estimator 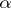 can be replaced by a function of the observations
can be replaced by a function of the observations 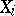 and an unknown parameter
and an unknown parameter  , the distribution of which does not depend (or "nearly does not depend" ) on all unknown parameters. An example of such a function is a normalized maximum-likelihood estimator
, the distribution of which does not depend (or "nearly does not depend" ) on all unknown parameters. An example of such a function is a normalized maximum-likelihood estimator 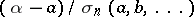 ; if in the denominator the arguments
; if in the denominator the arguments 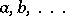 are replaced by maximum-likelihood estimators
are replaced by maximum-likelihood estimators 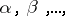 then the limit distribution will remain the same as in formula (8). The approximate confidence intervals for each parameter in isolation can therefore be constructed in the same way as in the case of a single parameter.
then the limit distribution will remain the same as in formula (8). The approximate confidence intervals for each parameter in isolation can therefore be constructed in the same way as in the case of a single parameter.
As has already been noted, if 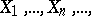 are independent and identically normally distributed random variables, then
are independent and identically normally distributed random variables, then 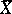 and
and 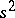 are the best statistical estimators for the parameters
are the best statistical estimators for the parameters  and
and 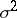 , respectively. The distribution function of the statistical estimator is expressed by the formula
, respectively. The distribution function of the statistical estimator is expressed by the formula
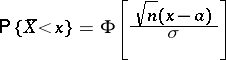 |
and, consequently, it depends not only on  but also on
but also on 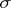 . At the same time, the distribution of the so-called Student statistic
. At the same time, the distribution of the so-called Student statistic
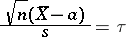 |
does not depend on  or
or 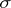 , and
, and
 |
where the constant 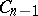 is chosen so that the equality
is chosen so that the equality 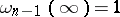 is satisfied. Thus, the confidence coefficient
is satisfied. Thus, the confidence coefficient 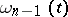 corresponds to the confidence interval
corresponds to the confidence interval
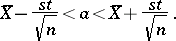 |
The distribution of the estimator  depends only on
depends only on 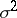 , while the distribution function of
, while the distribution function of 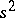 is defined by the formula
is defined by the formula
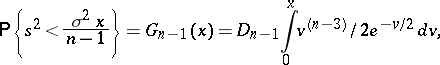 |
where the constant 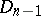 is defined by the condition
is defined by the condition 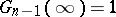 (the so-called
(the so-called 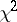 -distribution with
-distribution with 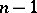 degrees of freedom, cf. "Chi-squared" distribution). Since the probability
degrees of freedom, cf. "Chi-squared" distribution). Since the probability 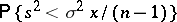 increases monotonically when
increases monotonically when 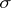 increases, rule (9) can be used to construct an interval estimator. Thus, if
increases, rule (9) can be used to construct an interval estimator. Thus, if 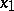 and
and 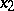 are the roots of the equations
are the roots of the equations 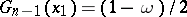 and
and 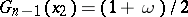 , then the confidence coefficient
, then the confidence coefficient 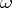 corresponds to the confidence interval
corresponds to the confidence interval
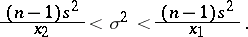 |
Hence it follows that the confidence interval for the relative error is defined by the inequalities
 |
Detailed tables of the Student distribution function 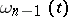 and of the
and of the 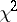 -distribution
-distribution 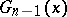 can be found in most textbooks on mathematical statistics.
can be found in most textbooks on mathematical statistics.
Until now it has been supposed that the distribution function of the results of observations is known up to values of various parameters. However, in practice the form of the distribution function is often unknown. In this case, when estimating the parameters, the so-called non-parametric methods in statistics can prove useful (i.e. methods which do not depend on the initial probability distribution). Suppose, for example, that the median 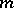 of a theoretical continuous distribution of independent random variables
of a theoretical continuous distribution of independent random variables 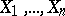 has to be estimated (for symmetric distributions, the median coincides with the mathematical expectation, provided, of course, that it exists). Let
has to be estimated (for symmetric distributions, the median coincides with the mathematical expectation, provided, of course, that it exists). Let 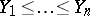 be the same variables
be the same variables 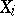 arranged in ascending order. Then, if
arranged in ascending order. Then, if  is an integer which satisfies the inequalities
is an integer which satisfies the inequalities 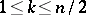 ,
,
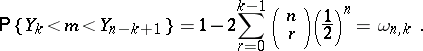 |
Thus, 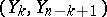 is an interval estimator for
is an interval estimator for 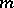 with confidence coefficient
with confidence coefficient 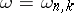 . This conclusion holds for any continuous distribution of the random variables
. This conclusion holds for any continuous distribution of the random variables 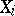 .
.
It has already been noted that a sample distribution is a point estimator for an unknown theoretical distribution. Moreover, the sample distribution function  is an unbiased estimator for a theoretical distribution function
is an unbiased estimator for a theoretical distribution function 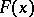 . Here, as A.N. Kolmogorov demonstrated, the distribution of the statistic
. Here, as A.N. Kolmogorov demonstrated, the distribution of the statistic
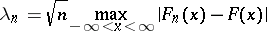 |
does not depend on the unknown theoretical distribution and, when  , tends to a limit distribution
, tends to a limit distribution 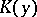 , which is called a Kolmogorov distribution. Thus, if
, which is called a Kolmogorov distribution. Thus, if 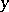 is the solution of the equation
is the solution of the equation 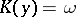 , then it can be claimed, with probability
, then it can be claimed, with probability 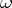 , that the graph of the function of the theoretical distribution function
, that the graph of the function of the theoretical distribution function 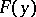 is completely "covered" by a strip enclosed between the graphs of the functions
is completely "covered" by a strip enclosed between the graphs of the functions 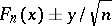 (when
(when 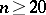 , the difference between the exact and limit distributions of the statistic
, the difference between the exact and limit distributions of the statistic 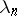 is immaterial). An interval estimator of this type is called a confidence region. See also Interval estimator.
is immaterial). An interval estimator of this type is called a confidence region. See also Interval estimator.
Statistical estimators in the theory of errors.
The theory of errors is an area of mathematical statistics devoted to the numerical determination of unknown variables by means of results of measurements. Owing to the random nature of measurement errors, and possibly of the actual phenomenon being studied, these results are not all equally correct: when measurements are repeated, some results are encountered more frequently, some less frequently.
The theory of errors is based on a mathematical model according to which the totality of all conceivable results of the measurements is treated as the set of values of a certain random variable. The theory of statistical estimators is therefore of considerable importance. The conclusions drawn from the theory of errors are of a statistical character. The sense and content of these conclusions (and indeed of the conclusions of the theory of statistical estimation) become clear only in the light of the law of large numbers (an example of this approach is the statistical interpretation of the sense of the confidence coefficient discussed above).
In proposing the result of a measurement 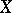 of a random variable, there are three separate basic types of error measurements: systematic, random and gross (qualitative descriptions of these errors are given under Errors, theory of). Here, the difference
of a random variable, there are three separate basic types of error measurements: systematic, random and gross (qualitative descriptions of these errors are given under Errors, theory of). Here, the difference 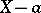 is called the error of the measurement of the unknown variable
is called the error of the measurement of the unknown variable  ; the mathematical expectation of this difference,
; the mathematical expectation of this difference, 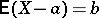 , is called the systematic error (if
, is called the systematic error (if  , then the measurements are said to be free of systematic errors), while the difference
, then the measurements are said to be free of systematic errors), while the difference 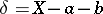 is called the random error (
is called the random error (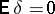 ). Thus, if
). Thus, if  independent measurements of the variable
independent measurements of the variable  are taken, then their results can be written in the form of the equalities
are taken, then their results can be written in the form of the equalities
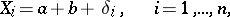 | (10) |
where  and
and 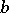 are constants, while
are constants, while 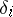 are random variables. In a more general case
are random variables. In a more general case
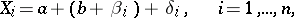 | (11) |
where 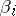 are random variables which do not depend on
are random variables which do not depend on 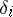 , and which are equal to zero with probability very close to one (every other value
, and which are equal to zero with probability very close to one (every other value 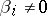 is therefore improbable). The values
is therefore improbable). The values 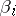 are called the gross errors (or outliers).
are called the gross errors (or outliers).
The problem of estimating (and eliminating) systematic errors does not normally fall within the limits of mathematical statistics. Two exceptions to this rule are the standard method, in which, when estimating 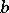 , a series of measurements of the known value
, a series of measurements of the known value  is made (in this method,
is made (in this method, 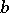 is a value to be estimated and
is a value to be estimated and  is a known systematic error) and dispersion analysis, in which the systematic divergence between various series of measurements is estimated.
is a known systematic error) and dispersion analysis, in which the systematic divergence between various series of measurements is estimated.
The fundamental problem in the theory of errors is to find a statistical estimator for an unknown variable  and to estimate the accuracy of the measurements. If the systematic error is eliminated
and to estimate the accuracy of the measurements. If the systematic error is eliminated 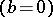 and the observations do not contain gross errors, then according to (10),
and the observations do not contain gross errors, then according to (10), 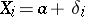 , and in this case the problem of estimating
, and in this case the problem of estimating  reduces to the problem of finding the optimal statistical estimator in one sense or another for the mathematical expectation of the identically distributed random variables
reduces to the problem of finding the optimal statistical estimator in one sense or another for the mathematical expectation of the identically distributed random variables 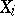 . As shown above, the form of such a statistical (point or interval) estimator depends essentially on the distribution law of the random errors. If this law is known up to various unknown parameters, then the maximum-likelihood method can be used to find an estimator for
. As shown above, the form of such a statistical (point or interval) estimator depends essentially on the distribution law of the random errors. If this law is known up to various unknown parameters, then the maximum-likelihood method can be used to find an estimator for  ; in the alternative case, a statistical estimator for an unknown distribution function of the random errors
; in the alternative case, a statistical estimator for an unknown distribution function of the random errors 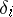 has to be found, using the results of the observations of
has to be found, using the results of the observations of 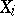 (the "non-parametric" interval estimator of this function is shown above). In practice, two statistical estimators
(the "non-parametric" interval estimator of this function is shown above). In practice, two statistical estimators  and
and 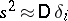 often suffice (see (1) and (2)). If
often suffice (see (1) and (2)). If 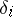 are identically normally distributed, then these statistical estimators are the best; in other cases, these estimators can prove to be quite inefficient.
are identically normally distributed, then these statistical estimators are the best; in other cases, these estimators can prove to be quite inefficient.
The appearance of outliers (gross errors) complicates the problem of estimating the parameter  . The proportion of observations in which
. The proportion of observations in which 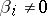 is usually small, while the mathematical expectation of non-zero
is usually small, while the mathematical expectation of non-zero 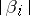 is significantly higher than
is significantly higher than 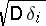 (gross errors arise as a result of random miscalculation, incorrect reading of the measuring equipment, etc.). Results of measurements which contain gross errors are often easily spotted, as they differ greatly from the other results. Under these conditions, the most advisable means of identifying (and eliminating) gross errors is to carry out a direct analysis of the measurements, to check carefully that all experiments were carried out under the same conditions, to make a "double note" of the results, etc. Statistical methods of finding gross errors are only to be used in cases of doubt.
(gross errors arise as a result of random miscalculation, incorrect reading of the measuring equipment, etc.). Results of measurements which contain gross errors are often easily spotted, as they differ greatly from the other results. Under these conditions, the most advisable means of identifying (and eliminating) gross errors is to carry out a direct analysis of the measurements, to check carefully that all experiments were carried out under the same conditions, to make a "double note" of the results, etc. Statistical methods of finding gross errors are only to be used in cases of doubt.
The simplest example of these methods is the statistical occurrence of an outlier, when either 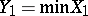 or
or 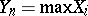 is open to doubt (it is proposed that in the equalities (11)
is open to doubt (it is proposed that in the equalities (11) 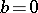 and that the distribution law of the variables
and that the distribution law of the variables 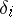 is known). In order to establish whether the hypothesis of the presence of an outlier is justified, a joint interval estimator (or prediction region) for the pair
is known). In order to establish whether the hypothesis of the presence of an outlier is justified, a joint interval estimator (or prediction region) for the pair 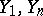 is calculated (a confidence region), by proposing that all
is calculated (a confidence region), by proposing that all 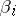 are equal to zero. If this statistical estimator "covers" the point with coordinates
are equal to zero. If this statistical estimator "covers" the point with coordinates 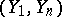 , then the doubt over the presence of an outlier has to be considered statistically unjustified; in the alternative case, the hypothesis of the absence of an outlier has to be accepted (the rejected theory is then usually discarded, as it is statistically impossible to reliably estimate the value of the outlier at all using one observation).
, then the doubt over the presence of an outlier has to be considered statistically unjustified; in the alternative case, the hypothesis of the absence of an outlier has to be accepted (the rejected theory is then usually discarded, as it is statistically impossible to reliably estimate the value of the outlier at all using one observation).
For example, let  be unknown, let
be unknown, let 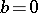 and let
and let 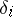 be independent and identically normally distributed (the variance is unknown). If all
be independent and identically normally distributed (the variance is unknown). If all 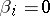 , then the distribution of the random variable
, then the distribution of the random variable
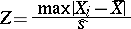 |
does not depend on unknown parameters (the statistical estimators 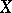 and
and 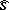 are calculated, using all
are calculated, using all  observations, according to the formulas (1) and (2)). For large values
observations, according to the formulas (1) and (2)). For large values
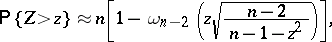 |
where 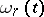 is the Student distribution function, as defined above. Thus, with confidence coefficient
is the Student distribution function, as defined above. Thus, with confidence coefficient
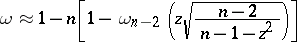 | (12) |
it can be claimed that in the absence of an outlier the inequality 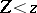 is satisfied, or, put another way,
is satisfied, or, put another way,
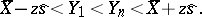 |
(The error in the estimation of the confidence coefficient by means of formula (12) does not exceed 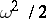 .) Therefore, if all results of the measurements of
.) Therefore, if all results of the measurements of 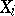 fall within the limits
fall within the limits 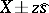 , then there are no grounds for supposing that any measurement contains an outlier.
, then there are no grounds for supposing that any measurement contains an outlier.
References
| [1] | H. Cramér, M.R. Leadbetter, "Stationary and related stochastic processes" , Wiley (1967) pp. Chapts. 33–34 |
| [2] | N.V. Smirnov, I.V. Dunin-Barkovskii, "Mathematische Statistik in der Technik" , Deutsch. Verlag Wissenschaft. (1969) (Translated from Russian) |
| [3] | Yu.V. Linnik, "Methode der kleinste Quadraten in moderner Darstellung" , Deutsch. Verlag Wissenschaft. (1961) (Translated from Russian) |
| [4] | B.L. van der Waerden, "Mathematische Statistik" , Springer (1957) |
| [5] | N. Arley, K.R. Buch, "Introduction to the theory of probability and statistics" , Wiley (1950) |
| [6] | A.N. Kolmogorov, "On the statistical estimation of the parameters of the Gauss distribution" Izv. Akad. Nauk SSSR Ser. Mat. , 6 : 1–2 (1942) pp. 3–32 (In Russian) (French abstract) |
Comments
This article passes by the possibility of robust estimation, whereby procedures for dealing with gross errors ( "outlieroutliers" ) are integrated with estimation of the parameter concerned. See e.g. [a1] and Robust statistics.
References
| [a1] | F.R. Hampel, E.M. Ronchetti, P.J. Rousseeuw, W.A. Stahel, "Robust statistics. The approach based on influence functions" , Wiley (1986) |
| [a2] | E.L. Lehmann, "Theory of point estimation" , Wiley (1983) |
| [a3] | D.R. Cox, D.V. Hinkley, "Theoretical statistics" , Chapman & Hall (1974) pp. 21 |
| [a4] | E.A. Nadaraya, "Nonparametric estimation of probability densities and regression curves" , Kluwer (1989) (Translated from Russian) |
Statistical estimator. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Statistical_estimator&oldid=13861