Regression analysis
A branch of mathematical statistics that unifies various practical methods for investigating dependence between variables using statistical data (see Regression). The problem of regression in mathematical statistics is characterized by the fact that there is insufficient information about the distributions of the variables under consideration. Suppose, for example, that there are reasons for assuming that a random variable 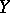 has a given probability distribution at a fixed value
has a given probability distribution at a fixed value  of another variable, so that
of another variable, so that
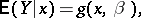 |
where 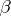 is a set of unknown parameters determining the function
is a set of unknown parameters determining the function 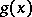 , and that it is required to determine the values of these parameters from results of observations. Depending on the nature of the problem and the aims of the analysis, the results of an experiment
, and that it is required to determine the values of these parameters from results of observations. Depending on the nature of the problem and the aims of the analysis, the results of an experiment 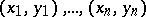 are interpreted in different ways in relation to the variable
are interpreted in different ways in relation to the variable  . To ascertain the connection between the variables in the experiment, one often uses a model based on simplified assumptions:
. To ascertain the connection between the variables in the experiment, one often uses a model based on simplified assumptions:  is a controllable variable, whose values are given in advance for the design of the experiment, and the observed value
is a controllable variable, whose values are given in advance for the design of the experiment, and the observed value 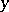 can be written in the form
can be written in the form
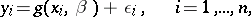 |
where the variables 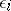 characterize the errors, which are independent for various measurements and identically distributed with mean zero and constant variance. In the case of an uncontrollable variable, the results of the observations
characterize the errors, which are independent for various measurements and identically distributed with mean zero and constant variance. In the case of an uncontrollable variable, the results of the observations 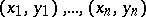 represent a sample from a certain two-dimensional aggregate. The methods of regression analysis are the same in both cases, although the interpretations of the results differ (in the latter case, the analysis is substantially supplemented by methods from the theory of correlation (in statistics)).
represent a sample from a certain two-dimensional aggregate. The methods of regression analysis are the same in both cases, although the interpretations of the results differ (in the latter case, the analysis is substantially supplemented by methods from the theory of correlation (in statistics)).
The study of regression for experimental data is carried out using methods based on the principles of mean-square regression. Regression analysis solves the following fundamental problems: 1) the choice of a regression model, which implies assumptions about the dependence of the regression function on  and
and 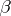 ; 2) an estimate of the parameters
; 2) an estimate of the parameters 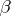 in the selected model, perhaps by the method of least squares; and 3) testing the statistical hypotheses about the regression.
in the selected model, perhaps by the method of least squares; and 3) testing the statistical hypotheses about the regression.
From the point of view of a single method for estimating unknown parameters, the most natural one is a regression model that is linear in these parameters:
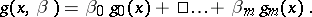 |
The choice of the functions 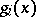 is sometimes arrived at by arranging the experimental values
is sometimes arrived at by arranging the experimental values 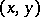 on a scattergram or, more often, by theoretical considerations. It is thus assumed that the variance
on a scattergram or, more often, by theoretical considerations. It is thus assumed that the variance  of the results of the observations is constant (or proportional to a known function of
of the results of the observations is constant (or proportional to a known function of  ). The standard method of regression estimation is based on the use of a polynomial of some degree
). The standard method of regression estimation is based on the use of a polynomial of some degree 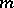 ,
, 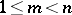 :
:
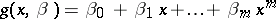 |
or, in the simplest case, of a linear function (linear regression)
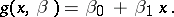 |
There are criteria for testing linearity and for choosing the degree of the approximating polynomial.
According to the principles of mean-square regression, the estimation of the unknown regression coefficients 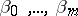 (cf. Regression coefficient) and the variance
(cf. Regression coefficient) and the variance 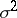 (cf. Dispersion) is realized by the method of least squares. Thus, as statistical estimators of
(cf. Dispersion) is realized by the method of least squares. Thus, as statistical estimators of 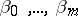 one chooses values
one chooses values 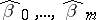 which minimize the expression
which minimize the expression
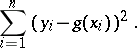 |
The polynomial 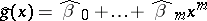 thus obtained is called the empirical regression curve, and is a statistical estimator of the unknown proper regression curve. Assuming linearity of regression, the equation of the empirical regression curve has the form
thus obtained is called the empirical regression curve, and is a statistical estimator of the unknown proper regression curve. Assuming linearity of regression, the equation of the empirical regression curve has the form
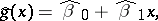 |
where
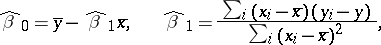 |
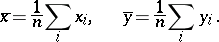 |
The random variables 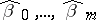 are called sample regression coefficients (or estimated regression coefficients). An unbiased estimator of the parameter
are called sample regression coefficients (or estimated regression coefficients). An unbiased estimator of the parameter 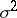 is given by
is given by
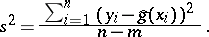 |
If the variance depends on  , the method of least squares is applicable with certain modifications.
, the method of least squares is applicable with certain modifications.
If one studies the dependence of a random variable 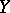 on several variables
on several variables  , then it is more convenient to write the general linear regression model in matrix form: An observation vector
, then it is more convenient to write the general linear regression model in matrix form: An observation vector 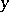 with independent components
with independent components  has mean value and covariance matrix given by
has mean value and covariance matrix given by
 | (*) |
where 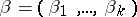 is the vector of regression coefficients,
is the vector of regression coefficients, 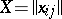 ,
, 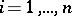 ,
, 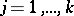 , is a matrix of known variables related to each other, generally speaking, in an arbitrary fashion, and
, is a matrix of known variables related to each other, generally speaking, in an arbitrary fashion, and 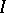 is the identity matrix of order
is the identity matrix of order  ; moreover,
; moreover, 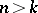 and
and 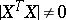 . More generally one can assume that there is correlation between the observations
. More generally one can assume that there is correlation between the observations 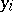 :
:
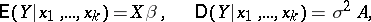 |
for some known matrix 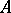 . But this scheme can be reduced to the model (*). An unbiased estimator for
. But this scheme can be reduced to the model (*). An unbiased estimator for 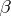 by the method of least squares is given by
by the method of least squares is given by
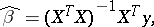 |
and an unbiased estimator for 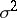 is given by
is given by
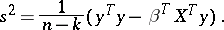 |
Model (*) is the most general linear model, in that it is applicable to various regression situations and encompasses all forms of polynomial regression of 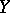 with respect to
with respect to  (in particular, the above polynomial regression of
(in particular, the above polynomial regression of 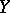 with respect to
with respect to  of order
of order 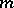 can be reduced to the model (*), in which
can be reduced to the model (*), in which 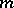 of the regression variables are functionally connected). In this linear interpretation of regression analysis, the problem of estimating
of the regression variables are functionally connected). In this linear interpretation of regression analysis, the problem of estimating 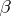 and the calculation of the covariance matrix of estimators
and the calculation of the covariance matrix of estimators 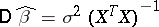 reduces to the problem of inverting the matrix
reduces to the problem of inverting the matrix 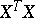 .
.
The above method for constructing an empirical regression assuming a normal distribution of the results of the observations leads to estimators for 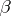 and
and 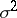 that coincide with the maximum-likelihood estimators. However, the estimators obtained by this method are, in a certain sense, also optimal in the case of deviation from normality, provided only that the sample size is sufficiently large.
that coincide with the maximum-likelihood estimators. However, the estimators obtained by this method are, in a certain sense, also optimal in the case of deviation from normality, provided only that the sample size is sufficiently large.
In the given matrix form, the general linear regression model (*) admits a simple extension to the case when the observed variables 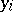 are random vector variables. This does not give rise to any new statistical problem (see Regression matrix).
are random vector variables. This does not give rise to any new statistical problem (see Regression matrix).
The problems of regression analysis are not restricted to the construction of point estimators of the parameters 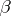 and
and 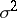 in the general linear model (*). The problem of the accuracy of a constructed empirical relation is most effectively solved under the assumption that the observation vector
in the general linear model (*). The problem of the accuracy of a constructed empirical relation is most effectively solved under the assumption that the observation vector 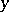 is normally distributed. If
is normally distributed. If 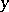 is normally distributed and since the estimator
is normally distributed and since the estimator 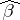 is a linear function of
is a linear function of 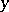 , one can conclude that the variable
, one can conclude that the variable 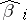 is normally distributed with mean
is normally distributed with mean 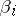 and variance
and variance 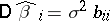 , where
, where 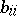 is the diagonal entry of the matrix
is the diagonal entry of the matrix 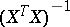 . Apart from this, the estimator
. Apart from this, the estimator 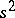 for
for 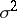 is distributed independently of any component of
is distributed independently of any component of 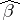 , and the variable
, and the variable 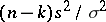 has a "chi-squared" distribution with
has a "chi-squared" distribution with 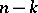 degrees of freedom. Hence the statistic
degrees of freedom. Hence the statistic
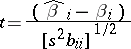 |
has the Student distribution with 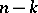 degrees of freedom. This fact is used to construct confidence intervals for the parameters
degrees of freedom. This fact is used to construct confidence intervals for the parameters 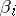 and for testing hypotheses about the values taking by them. One can also find confidence intervals for
and for testing hypotheses about the values taking by them. One can also find confidence intervals for 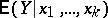 for fixed values of all the regression variables, and confidence intervals containing the
for fixed values of all the regression variables, and confidence intervals containing the 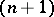 -th subsequent value of
-th subsequent value of 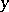 (called prediction intervals). Finally, starting from a vector of sample regression coefficients
(called prediction intervals). Finally, starting from a vector of sample regression coefficients  one can construct a confidence ellipsoid for
one can construct a confidence ellipsoid for 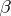 , or for any set of unknown regression coefficients, and also a confidence region for the entire regression curve.
, or for any set of unknown regression coefficients, and also a confidence region for the entire regression curve.
Regression analysis is one of the most widely used methods for processing experimental data when investigating relations in physics, biology, economics, technology, and other fields. Such branches of mathematical statistics as dispersion analysis and the design of experiments are based on models of regression analysis, and these models are widely used in multi-dimensional statistical analysis.
References
| [1] | M.G. Kendall, A. Stuart, "The advanced theory of statistics" , 2. Inference and relationship , Griffin (1979) |
| [2] | N.V. Smirnov, I.V. Dunin-Barkovskii, "Mathematische Statistik in der Technik" , Deutsch. Verlag Wissenschaft. (1969) (Translated from Russian) |
| [3] | S.A. Aivazyan, "Statistical research on dependence" , Moscow (1968) (In Russian) |
| [4] | C.R. Rao, "Linear statistical inference and its applications" , Wiley (1965) |
| [5] | N.R. Draper, H. Smith, "Applied regression analysis" , Wiley (1981) |
Comments
Modern research — inspired by modern computational facilities — is aimed at developing methods for regression analysis when the classical assumptions of regression analysis do not hold. For instance, one can estimate the function 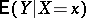 using only smoothness assumptions by adapting methods from density estimation, or one can produce robust estimators (cf. Robust statistics) in the linear regression model by minimizing the sum of absolute deviations from the regression line instead of the sum of their squares.
using only smoothness assumptions by adapting methods from density estimation, or one can produce robust estimators (cf. Robust statistics) in the linear regression model by minimizing the sum of absolute deviations from the regression line instead of the sum of their squares.
References
| [a1] | W. Härdle, "Applied nonparametric regression" , Cambridge Univ. Press (1990) |
Regression analysis. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Regression_analysis&oldid=17714