Minimization methods for functions depending strongly on a few variables
Numerical methods for finding minima of functions of several variables. Suppose one is given a function that is bounded from below and twice continuously differentiable,
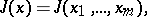 |
and that is known to take its least value at a vector 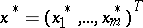 (where
(where 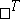 denotes transposition). One wishes to construct a sequence of vectors
denotes transposition). One wishes to construct a sequence of vectors  ,
, 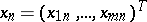 , such that
, such that
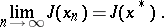 |
There are many methods for obtaining such a sequence. However, the majority of algorithms suffer from a sharp deterioration when the level surfaces 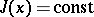 of the function to be minimized have a structure which is far from spherical. In this case a domain
of the function to be minimized have a structure which is far from spherical. In this case a domain 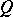 in which the norm of the gradient vector
in which the norm of the gradient vector
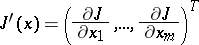 |
is essentially smaller than in the rest of the space is called a bottom of a valley, and the function itself is called a valley function. If the dimension of the space of arguments of the function to be minimized exceeds two, the structure of the level surfaces of the valley function may be very complicated. 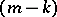 -dimensional valleys occur, where
-dimensional valleys occur, where 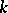 varies from 1 to
varies from 1 to 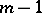 . In three-dimensional space, for example, one and two-dimensional valleys are possible.
. In three-dimensional space, for example, one and two-dimensional valleys are possible.
Functions of valley type are locally characterized by an ill-conditioned matrix of second derivatives (Hesse matrix or Hessian)
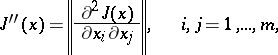 |
which leads to strong variations of 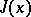 along directions coinciding with eigen vectors of the Hesse matrix corresponding to large eigen values, and to small variations along directions corresponding to small eigen values.
along directions coinciding with eigen vectors of the Hesse matrix corresponding to large eigen values, and to small variations along directions corresponding to small eigen values.
Most known methods of optimization allow a fairly rapid descent to the bottom  of the valley, leading sometimes to a considerable reduction in the values of
of the valley, leading sometimes to a considerable reduction in the values of 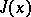 as compared with its value at the starting point (descent into the bottom of the valley). However, the process then slows down sharply, and practically stops at some point of
as compared with its value at the starting point (descent into the bottom of the valley). However, the process then slows down sharply, and practically stops at some point of 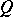 which may be far from the required minimum point.
which may be far from the required minimum point.
A twice continuously-differentiable function 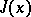 is called a valley function (see [1]) if there exists a domain
is called a valley function (see [1]) if there exists a domain 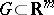 in which the eigen values of the Hesse matrix
in which the eigen values of the Hesse matrix 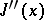 , in order of decreasing modulus, satisfy, at any point
, in order of decreasing modulus, satisfy, at any point 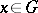 , the inequality
, the inequality
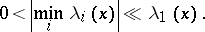 | (1) |
The degree of steepness of the valley is characterized by the number
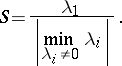 | (2) |
If the eigen values of 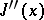 in
in 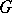 satisfy the inequalities
satisfy the inequalities
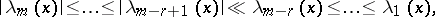 |
then the number  is called the dimension of the valley of the function
is called the dimension of the valley of the function 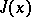 at
at 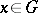 (see [1]).
(see [1]).
The system of differential equations describing the trajectory of descent of 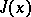 ,
,
 | (3) |
is a stiff differential system.
In particular, when 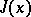 is strictly convex and the Hesse matrix is positive definite (all its eigen values are strictly positive), the inequalities (1) coincide with the well-known requirement for ill-conditioning of the Hesse matrix:
is strictly convex and the Hesse matrix is positive definite (all its eigen values are strictly positive), the inequalities (1) coincide with the well-known requirement for ill-conditioning of the Hesse matrix:
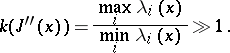 |
In this case the spectral condition number is the same as the degree of steepness of the valley.
The coordinate-wise descent method (see [2])
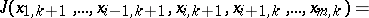 | (4) |
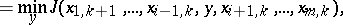 |
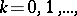 |
in spite of its simplicity and universality, is effective in the valley situation only in the rare case when the orientation of the valleys is along the coordinate axes.
A modernization of the method (4) was proposed in [2], consisting of a rotation of the coordinate axes so that one of the axes lies along 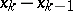 , after which the search begins at the
, after which the search begins at the 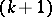 -st step. Such an approach leads to one of the axes having a tendency to align along a generator of the bottom of the valley, allowing one to perform successfully the minimization of functions with one-dimensional valleys in several cases. The method is unsuitable for multi-dimensional valleys.
-st step. Such an approach leads to one of the axes having a tendency to align along a generator of the bottom of the valley, allowing one to perform successfully the minimization of functions with one-dimensional valleys in several cases. The method is unsuitable for multi-dimensional valleys.
The scheme of the method of steepest descent (cf. Steepest descent, method of) is given by the difference equation
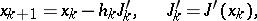 | (5) |
where 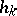 is chosen by the condition
is chosen by the condition
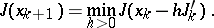 |
For strictly-convex valley functions, in particular for quadratic ones
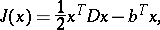 | (6) |
the sequence 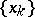 constructed by algorithm (5) converges geometrically to the minimum point
constructed by algorithm (5) converges geometrically to the minimum point 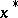 of the function (see [3]):
of the function (see [3]):
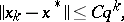 |
where  and
and
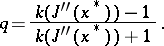 |
Since 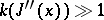 for a valley function,
for a valley function, 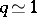 and convergence is effectively absent.
and convergence is effectively absent.
A similar picture can be seen for the simple gradient scheme (see [4]; Gradient method)
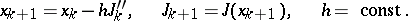 | (7) |
Acceleration of its convergence is based on using the results of the previous iterations to make the bottom of the valley more precise. The gradient method (7) could be used (see [4], [5]) with computation of the ratio 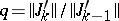 at each iteration. When it becomes steady near the constant value
at each iteration. When it becomes steady near the constant value 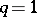 , a large accelerating step is performed in accordance with the expression
, a large accelerating step is performed in accordance with the expression
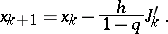 |
Then descent by the gradient method is continued until the next accelerating step.
Various versions of the method of parallel tangents (see [4]–[6]) are based on carrying out the accelerating step along the direction 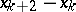 given by the points
given by the points 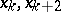 in the gradient method. In the "heavy-sphere" method (see [4]; Heavy sphere, method of the) the next approximation has the form
in the gradient method. In the "heavy-sphere" method (see [4]; Heavy sphere, method of the) the next approximation has the form
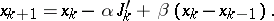 |
In the valley method (see [7]) local descents are carried out by the gradient method (7) from two arbitrarily chosen starting points, and then an accelerating step is made in a direction given by two of the points at the bottom of the valley.
These methods are not much more complicated than the gradient method (7), and they are based on it. Accelerated convergence is obtained for a one-dimensional valley. In more general cases of multi-dimensional valleys, where convergence of these methods slows down sharply, one has to turn to the more powerful methods of quadratic approximation, based on Newton's method (cf. Newton method)
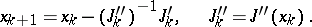 | (8) |
The minimum of the function (6) satisfies the system of linear equations
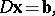 | (9) |
and under the condition of absolute accuracy of all computations, for a quadratic function Newton's method is independent of the degree of steepness of the valley (2) and the dimension of the valley, and leads to the minimum in one step. In reality, with a large condition number 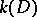 and a restricted number of digits in computation, the problem of solving (9) may be ill-posed, and small changes in the elements of the matrix
and a restricted number of digits in computation, the problem of solving (9) may be ill-posed, and small changes in the elements of the matrix 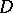 and the vector
and the vector 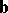 can lead to large variations in
can lead to large variations in 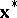 .
.
With moderate degrees of steepness in a convex situation, Newton's method often turns out to be preferable, with respect to speed of convergence, to other methods, such as the gradient method.
A large class of quadratic (quasi-Newtonian) methods are based on the use of conjugate directions (see [2], [3], [8]). For the case of minimization of a convex function these algorithms are very effective, since having a quadratic termination they do not require a computation of the matrix of second derivatives.
Sometimes (see [8]) the iteration is performed according to the scheme
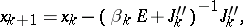 | (10) |
where 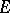 is the identity matrix. The scalars
is the identity matrix. The scalars 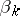 are chosen so that the matrix
are chosen so that the matrix 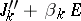 is positive definite and
is positive definite and
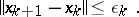 |
There are several similar approaches (see [8]) based on obtaining strictly positive definite approximations to the Hesse matrix. For the minimization of valley functions such algorithms turn out to be inefficient because of the difficulty in choosing the parameters 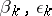 , etc. The choice of these parameters is based on information on the size of the eigen values of smallest modulus of the Hesse matrix, and for real calculations and a high degree of steepness this information is strongly distorted.
, etc. The choice of these parameters is based on information on the size of the eigen values of smallest modulus of the Hesse matrix, and for real calculations and a high degree of steepness this information is strongly distorted.
A more appropriate generalization of Newton's method for the case of minimization of valley functions is based on the continuous principle of optimization. The function 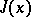 is juxtaposed to a differential system (3), which is integrable by the system method (see Stiff differential system). The minimization algorithm takes the form
is juxtaposed to a differential system (3), which is integrable by the system method (see Stiff differential system). The minimization algorithm takes the form
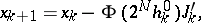 | (11a) |
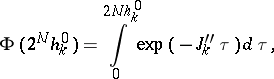 | (11b) |
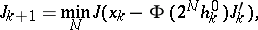 | (11c) |
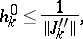 |
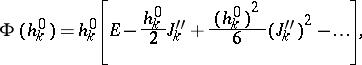 | (11d) |
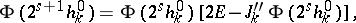 | (11e) |
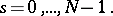 |
In [1], an algorithm for the minimization of valley functions has been proposed based on the use of properties of stiff systems. Let the function 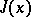 be approximated in a neighbourhood of
be approximated in a neighbourhood of 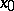 by the quadratic function (6). The matrix
by the quadratic function (6). The matrix 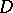 and the vector
and the vector 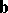 are computed by, for example, finite-difference approximation. From the representation of the elements of the matrix
are computed by, for example, finite-difference approximation. From the representation of the elements of the matrix
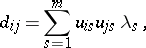 |
where 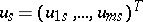 ,
, 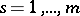 , is an orthonormal basis of eigen vectors of
, is an orthonormal basis of eigen vectors of 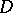 , it follows that imprecise measurement of these elements distorts the information about the smallest eigen values of an ill-conditioned matrix, and hence leads to ill-posedness of the problem of minimization of (6).
, it follows that imprecise measurement of these elements distorts the information about the smallest eigen values of an ill-conditioned matrix, and hence leads to ill-posedness of the problem of minimization of (6).
Moreover, the system of differential equations of descent for the valley function (6),
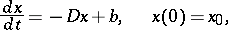 |
has a solution in which, by virtue of condition (1), the terms with factors 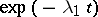 have an influence only on a small initial interval of length
have an influence only on a small initial interval of length 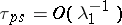 .
.
In other words, the components of the vector 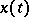 satisfy the equation
satisfy the equation
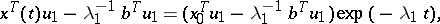 |
which quickly goes over to the stationary relation
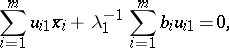 | (12) |
where 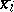 are the components of a vector satisfying (12). This property is used in the algorithm. Expressing the
are the components of a vector satisfying (12). This property is used in the algorithm. Expressing the 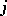 -th component of the vector
-th component of the vector 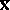 to which the maximal component of the vector
to which the maximal component of the vector 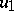 corresponds in terms of the remaining components, one replaces
corresponds in terms of the remaining components, one replaces 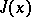 by a new function with argument of dimension
by a new function with argument of dimension 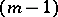 :
:
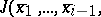 | (13) |
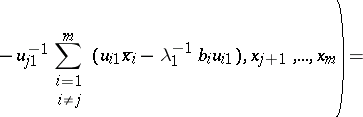 |
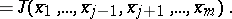 |
One then finds a new matrix 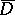 of order
of order 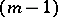 and a new vector
and a new vector 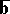 from the function (13) by means of finite-difference approximation. Here it is not so much the reduction of the dimension of the search space that is important, as the reduction of the degree of steepness, so that in the minimization of the new function in the subspace orthogonal to the vector
from the function (13) by means of finite-difference approximation. Here it is not so much the reduction of the dimension of the search space that is important, as the reduction of the degree of steepness, so that in the minimization of the new function in the subspace orthogonal to the vector 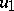 , the largest eigen value no longer influences the computation. The requirement that
, the largest eigen value no longer influences the computation. The requirement that 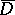 and
and 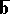 are obtained in terms of the function (13), and not in terms of
are obtained in terms of the function (13), and not in terms of 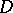 and
and 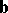 , is a very important point here. The coefficients of relation (12) are found by the power method as coefficients of an arbitrary equation of the system
, is a very important point here. The coefficients of relation (12) are found by the power method as coefficients of an arbitrary equation of the system
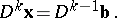 |
If the degree of steepness is not reduced or is reduced insignificantly, then the process of elimination of coordinates of the vector  is continued recursively until the necessary reduction is obtained.
is continued recursively until the necessary reduction is obtained.
References
| [1] | Yu.V. Rakitskii, S.M. Ustinov, I.G. Chernorustskii, "Computational methods for the solution of stiff systems" , Moscow (1979) (In Russian) |
| [2] | J. Céa, "Optimisation. Théorie et algorithmes" , Dunod (1971) |
| [3] | B.N. Pshenichnyi, Yu.M. Danilin, "Numerical methods in extremal problems" , MIR (1978) (Translated from Russian) |
| [4] | B.T. Polyak, "Methods for minimizing functions of several variables" Ekonom. i Mat. Metody , 3 : 6 (1967) pp. 881–902 (In Russian) |
| [5] | D.K. Faddeev, V.N. Faddeeva, "Computational methods of linear algebra" , Freeman (1963) (Translated from Russian) |
| [6] | D.J. Wilde, "Optimum seeking methods" , Prentice-Hall (1964) |
| [7] | I.M. Gel'fand, M.L. Tsetlin, "The principle of nonlocal search in automatic optimization systems" Soviet Phys. Dokl. , 6 (1961) pp. 192–194 Dokl. Akad. Nauk SSSR , 137 : 2 (1961) pp. 295–298 |
| [8] | P.E. Gill (ed.) W. Murray (ed.) , Numerical methods for constrained optimization , Acad. Press (1974) |
Comments
References
| [a1] | D.G. Luenberger, "Linear and nonlinear programming" , Addison-Wesley (1984) |
Minimization methods for functions depending strongly on a few variables. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Minimization_methods_for_functions_depending_strongly_on_a_few_variables&oldid=16514