Information-based complexity
IBC
Computational complexity studies the intrinsic difficulty of solving mathematically posed problems. Discrete computational complexity studies discrete problems and often uses the Turing machine model of computation. Continuous computational complexity studies continuous problems and tends to use the real number model; see [a1], [a3] as well as Optimization of computational algorithms.
Information-based complexity is part of continuous computational complexity. Typically, it studies infinite-dimensional problems for which the input is an element of an infinite-dimensional space. Examples of such problems include multivariate integration or approximation, solution of ordinary or partial differential equations, integral equations, optimization, and solution of non-linear equations. The input of such problems is usually a multivariate function on the real numbers, represented by an oracle (subroutine) which computes, for example, the function value at a given point. This oracle can be used only a finite number of times. That is why only partial information is available when solving an infinite-dimensional problem on a digital computer. This partial information is often contaminated with errors such as round-off errors, measurement errors, or human errors. Thus, the available information is partial and/or contaminated. Therefore, the original problem can be solved only approximately. The goal of information-based complexity is to compute such an approximation at minimal cost. The error and the cost of approximation can be defined in different settings including worst case, average case (see also Bayesian numerical analysis), probabilistic, randomized (see also Monte-Carlo method; Stochastic numerical algorithm) and mixed settings.
The  -complexity is defined as the minimal cost of computing an approximation with error at most
-complexity is defined as the minimal cost of computing an approximation with error at most  . For many problems, sharp complexity bounds are obtained by studying only the information cost.
. For many problems, sharp complexity bounds are obtained by studying only the information cost.
Information-based complexity is a branch of computational complexity and is formulated as an abstract theory with applications in many areas. Since continuous computational problems are of interest in many fields, information-based complexity has common interests and has greatly benefited from these fields. Questions, concepts, and results from approximation theory, numerical analysis, applied mathematics, statistics, complexity theory, algorithmic analysis, number theory, analysis and measure theory have all been influential. See also [a2], [a4], [a5], [a6], [a8].
Recent emphasis in information-based complexity is on the study of complexity of linear multivariate problems involving functions of 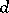 variables with large or even infinite
variables with large or even infinite 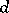 . For example, for path integration one has
. For example, for path integration one has 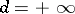 , while the approximation of path integrals yields multivariate integration with huge
, while the approximation of path integrals yields multivariate integration with huge 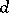 , see [a7].
, see [a7].
Linear multivariate problems are studied in various settings. The main question is to check which linear multivariate problems are tractable, i.e., their complexity is polynomial in  and in
and in 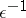 . The Smolyak algorithm, or a modification of it, is often near optimal for general multivariate problems defined over tensor product spaces. Some of such problems are tractable even in the worst-case setting.
. The Smolyak algorithm, or a modification of it, is often near optimal for general multivariate problems defined over tensor product spaces. Some of such problems are tractable even in the worst-case setting.
In the worst-case setting, many multivariate problems defined over isotropic spaces are intractable. This means that they suffer the curse of dimension, since their complexity is an exponential function of  . The curse of dimension can be sometimes broken by switching to another setting, such as an average case or randomized setting, or by shrinking the class of input functions.
. The curse of dimension can be sometimes broken by switching to another setting, such as an average case or randomized setting, or by shrinking the class of input functions.
References
| [a1] | L. Blum, M. Shub, S. Smale, "On a theory of computation and complexity over the real numbers: NP-completeness, recursive functions and universal machines" Bull. Amer. Math. Soc. , 21 (1989) pp. 1–46 |
| [a2] | E. Novak, "Deterministic and stochastic error bounds in numerical analysis" , Lecture Notes Math. , 1349 , Springer (1988) |
| [a3] | E. Novak, "The real number model in numerical analysis" J. Complexity , 11 (1995) pp. 57–73 |
| [a4] | L. Plaskota, "Noisy information and computational complexity" , Cambridge Univ. Press (1996) |
| [a5] | J.F. Traub, G.W. Wasilkowski, H. Woźniakowski, "Information-based complexity" , Acad. Press (1988) |
| [a6] | J.F. Traub, A.G. Werschulz, "Complexity and information" , Cambridge Univ. Press (1998) |
| [a7] | G.W. Wasilkowski, H. Woźniakowski, "On tractability of path integration" J. Math. Phys. , 37 (1996) pp. 2071–2088 |
| [a8] | A.G. Werschulz, "The computational complexity of differential and integral equations: An information-based approach" , Oxford Univ. Press (1991) |
Information-based complexity. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Information-based_complexity&oldid=12167