Least squares, method of
A method in the theory of errors (cf. Errors, theory of) for estimating unknown quantities on the basis of results of measurement involving random errors. It is also used for the approximate representation of a given function by other (simpler) functions and it often proves useful for the processing of observations. It was first proposed by C.F. Gauss (1794–1795) and A. Legendre (1805–1806). The establishment of a rigorous basis for the method of least squares and the delineation of the limits of meaningful applicability of it were provided by A.A. Markov and A.N. Kolmogorov. In the simplest case, that of linear relationships (see below) and observations containing no systematic errors but only random ones, the least-square estimators of the unknown quantities are linear functions of the observed values. These estimators involve no systematic errors, i.e. they are unbiased (see Unbiased estimator). If the random errors in the observations are independent and follow a normal distribution law, the method yields estimators with minimum variance, i.e. they are efficient estimators (see Statistical estimation). It is in this sense that the method of least squares is optimal among all other methods for the determination of unbiased estimators. However, if the distribution of the random errors significantly departs from the normal one, the method is no longer necessarily the best.
In laying rigorous foundations for the method of least squares (in the Gaussian version), one assumes that the "loss" incurred by replacing the (unknown) exact value of some quantity 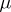 by an approximate value
by an approximate value 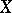 , calculated on the basis of observations, is proportional to the squared error
, calculated on the basis of observations, is proportional to the squared error 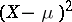 ; as an optimal estimator one takes a value of
; as an optimal estimator one takes a value of 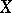 , free of systematic errors, for which the mean
, free of systematic errors, for which the mean 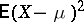 of the "loss" is minimal. This requirement is fundamental to the method of least squares. In the general case, the task of finding an optimal estimator
of the "loss" is minimal. This requirement is fundamental to the method of least squares. In the general case, the task of finding an optimal estimator 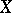 — in the least-square sense — is extremely complex, and so in practice one confines oneself to a narrower goal: One takes
— in the least-square sense — is extremely complex, and so in practice one confines oneself to a narrower goal: One takes 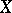 to be a linear function of the observed results which involves no systematic errors, and such that the mean error is minimal relative to the class of all linear functions. If the random errors of the observations are normally distributed and the estimated quantity
to be a linear function of the observed results which involves no systematic errors, and such that the mean error is minimal relative to the class of all linear functions. If the random errors of the observations are normally distributed and the estimated quantity  depends linearly on the mean values of the observed results (a case which arises very frequently in applications of the method of least squares), the solution of this restricted problem turns out to be also the solution of the general problem. Under these conditions, the optimal estimator
depends linearly on the mean values of the observed results (a case which arises very frequently in applications of the method of least squares), the solution of this restricted problem turns out to be also the solution of the general problem. Under these conditions, the optimal estimator 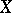 also obeys a normal law with mean
also obeys a normal law with mean 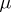 , and so the probability density of
, and so the probability density of 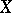 ,
,
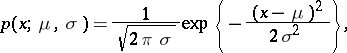 |
attains a maximum at 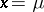 (this property is a rigorous expression of the statement, very common in the theory of errors, that "the estimator X furnished by the method of least squares is the most probable value of the unknown parameter m" ).
(this property is a rigorous expression of the statement, very common in the theory of errors, that "the estimator X furnished by the method of least squares is the most probable value of the unknown parameter m" ).
The case of one unknown.
Assume that an unknown constant 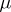 is to be estimated on the basis of
is to be estimated on the basis of  independent observations, which have yielded results
independent observations, which have yielded results 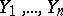 , i.e.
, i.e. 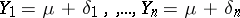 , where the
, where the  are random errors (by the usual definition in the classical theory of errors, random errors are independent random variables with expectation zero:
are random errors (by the usual definition in the classical theory of errors, random errors are independent random variables with expectation zero: 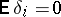 ; if
; if 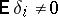 , then the
, then the 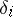 are called systematic errors). According to the method of least squares, one adopts an estimator
are called systematic errors). According to the method of least squares, one adopts an estimator 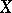 for
for 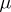 that minimizes the sum of the squares (hence the name of the method)
that minimizes the sum of the squares (hence the name of the method)
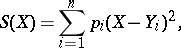 |
where
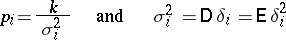 |
(the coefficient 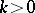 can be arbitrarily chosen). The number
can be arbitrarily chosen). The number 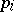 is known as the weight and
is known as the weight and 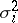 as the squared deviation of the
as the squared deviation of the 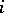 -th measurement. In particular, if all measurements are equally precise, then
-th measurement. In particular, if all measurements are equally precise, then  , and one can then put
, and one can then put 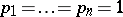 ; but if each
; but if each 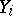 is the arithmetic mean of
is the arithmetic mean of 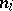 equally-precise measurements, one puts
equally-precise measurements, one puts  .
.
The sum 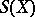 will be minimal if
will be minimal if 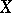 is chosen to be the weighted average
is chosen to be the weighted average
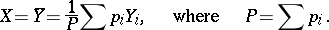 |
The estimator 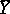 for
for 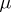 is unbiased, has weight
is unbiased, has weight 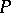 and variance
and variance 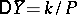 . In particular, if all measurements are equally precise, then
. In particular, if all measurements are equally precise, then 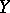 is the arithmetic mean of the results of measurement:
is the arithmetic mean of the results of measurement:
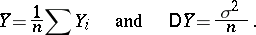 |
Subject to certain general assumptions one can show that if  , the number of observations, is sufficiently large, then the distribution of the estimator
, the number of observations, is sufficiently large, then the distribution of the estimator 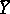 differs only slightly from that of the normal law with expectation
differs only slightly from that of the normal law with expectation  and variance
and variance 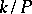 . In this case the absolute error of the approximate equality
. In this case the absolute error of the approximate equality 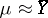 is less than
is less than 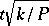 with probability approximately equal to
with probability approximately equal to
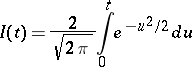 | (1) |
(e.g.  ;
; 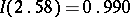 ;
; 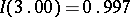 ).
).
If the measurement weights 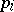 are given and the factor
are given and the factor 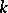 remains undetermined before the observations are taken, then this factor and the variance of
remains undetermined before the observations are taken, then this factor and the variance of 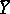 can be estimated by
can be estimated by
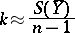 |
and
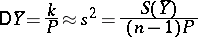 |
(both these estimators are also unbiased).
In the practically important case in which the errors 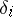 are normally distributed, one can determine the exact probability with which the absolute error of the equality
are normally distributed, one can determine the exact probability with which the absolute error of the equality 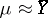 will be less than
will be less than 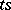 (where
(where 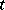 is an arbitrary positive number) as
is an arbitrary positive number) as
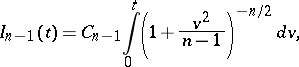 | (2) |
where the constant  is so chosen that
is so chosen that 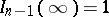 (the Student distribution with
(the Student distribution with 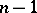 degrees of freedom). For large
degrees of freedom). For large  , formula (2) can be replaced by (1). For relatively small
, formula (2) can be replaced by (1). For relatively small  , however, the use of formula (1) may cause large errors. For example, according to (1), a value
, however, the use of formula (1) may cause large errors. For example, according to (1), a value 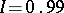 corresponds to
corresponds to 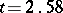 ; the true values of
; the true values of 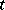 defined for small
defined for small  as the solutions of the equations
as the solutions of the equations 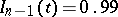 are shown in the following table:'
are shown in the following table:'
<tbody> </tbody>
|



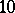
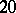
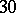
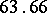
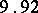
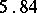
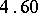
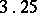
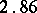
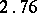
Example. To determine the mass of a body, it was weighted ten times in exactly the same way assuming the different weighings to be independent; the results  (in grams) were:'
(in grams) were:'
<tbody> </tbody>
|
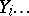
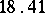
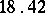
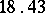
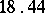
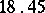
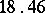
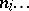


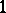
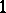
(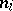 denotes the number of cases in which the mass
denotes the number of cases in which the mass 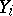 was observed;
was observed; 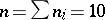 ). Since the different weighings were assumed to be equally precise, one puts
). Since the different weighings were assumed to be equally precise, one puts  and the estimate for the unknown weight
and the estimate for the unknown weight 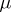 is chosen to be
is chosen to be 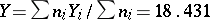 . Putting, say,
. Putting, say,  and checking the tables of the Student distribution with nine degrees of freedom, one finds that
and checking the tables of the Student distribution with nine degrees of freedom, one finds that 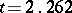 , so that the maximum absolute error in the approximate equality
, so that the maximum absolute error in the approximate equality 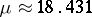 is
is
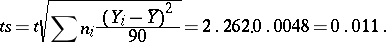 |
Thus, 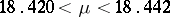 with probability
with probability 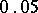 .
.
The case of several unknowns (linear relationships).
Suppose that  measurement results
measurement results 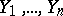 are related to
are related to 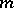 unknown constants
unknown constants 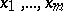 (
(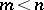 ) by means of independent linear relationships
) by means of independent linear relationships
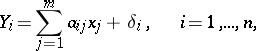 | (3) |
where the 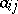 are known coefficients and the
are known coefficients and the 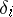 are independent random errors in the measurements. One wishes to estimate the unknown quantities
are independent random errors in the measurements. One wishes to estimate the unknown quantities 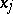 (this problem can be regarded as a generalization of the previous problem, with
(this problem can be regarded as a generalization of the previous problem, with 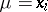 and
and 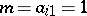 ;
; 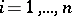 ).
).
Since 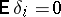 , the mean values of the results,
, the mean values of the results,  , are related to the unknowns
, are related to the unknowns 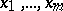 by means of the following linear equations:
by means of the following linear equations:
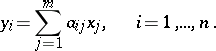 | (4) |
Consequently, the desired values of 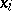 are a solution of the system (4) (on the assumption that the equations are consistent). The precise values of the measured magnitudes
are a solution of the system (4) (on the assumption that the equations are consistent). The precise values of the measured magnitudes 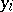 and the random errors
and the random errors 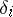 are usually unknown, and so one generally replaces the systems (3) and (4) by the conditional equations:
are usually unknown, and so one generally replaces the systems (3) and (4) by the conditional equations:
 |
In the method of least squares, estimators for the unknowns  are the quantities
are the quantities 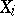 that minimize the sum of the squared deviations
that minimize the sum of the squared deviations
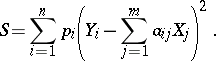 |
(As in the previous case, 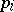 is the weight of the measurement and
is the weight of the measurement and 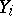 is the quantity inversely proportional to the variance of the random error
is the quantity inversely proportional to the variance of the random error 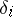 .) The conditional equations are as a rule inconsistent, i.e. for arbitrary values of
.) The conditional equations are as a rule inconsistent, i.e. for arbitrary values of 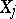 the differences
the differences
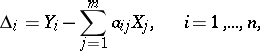 |
cannot all vanish, in general. The method of least squares prescribes taking as estimators those values of 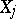 that minimize the sum
that minimize the sum 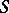 . In those exceptional cases in which the conditional equations are consistent, and therefore solvable, the solution consists precisely of the estimators furnished by the method of least squares.
. In those exceptional cases in which the conditional equations are consistent, and therefore solvable, the solution consists precisely of the estimators furnished by the method of least squares.
The sum 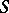 of the squares is a quadratic polynomial in the variables
of the squares is a quadratic polynomial in the variables 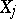 ; this polynomial attains a minimum at the values of
; this polynomial attains a minimum at the values of 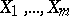 for which all the first partial derivatives vanish:
for which all the first partial derivatives vanish:
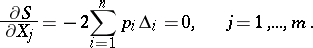 |
Hence it follows that the  furnished by the method of least squares must satisfy the so-called normal equations. In the notation proposed by Gauss, these equations are:
furnished by the method of least squares must satisfy the so-called normal equations. In the notation proposed by Gauss, these equations are:
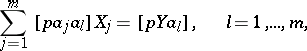 | (5) |
where
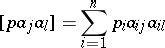 |
and
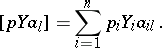 |
Estimators obtained by solving the system of normal equations are unbiased 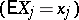 ; the variances
; the variances  are
are 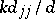 , where
, where 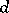 is the determinant of the system (5) and
is the determinant of the system (5) and 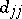 is the minor corresponding to the diagonal entry
is the minor corresponding to the diagonal entry 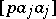 (in other words,
(in other words, 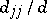 is the weight of the estimator
is the weight of the estimator 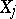 ). If the proportionality factor
). If the proportionality factor 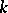 (known as the variance per unit weight) is not known in advance, it can be estimated, and with it the variances
(known as the variance per unit weight) is not known in advance, it can be estimated, and with it the variances 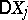 , by the formulas:
, by the formulas:
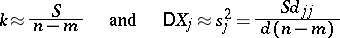 |
(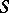 is the minimum value of the original sum of the squares). Subject to certain general assumptions one can show that if the number of observations
is the minimum value of the original sum of the squares). Subject to certain general assumptions one can show that if the number of observations  is sufficiently large, the absolute error of the approximate equality
is sufficiently large, the absolute error of the approximate equality 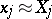 is less than
is less than 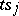 with probability approximately given by the integral (1). If the random errors
with probability approximately given by the integral (1). If the random errors 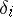 obey a normal law, then all quotients
obey a normal law, then all quotients 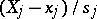 are distributed according to the Student law with
are distributed according to the Student law with 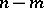 degrees of freedom (a precise estimation of the absolute error of the approximate equality makes use of the integral (2), just as in the case of one unknown). In addition, the minimum value of
degrees of freedom (a precise estimation of the absolute error of the approximate equality makes use of the integral (2), just as in the case of one unknown). In addition, the minimum value of 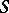 is independent of
is independent of 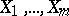 (in the probabilistic sense), and therefore the approximate values of the variances
(in the probabilistic sense), and therefore the approximate values of the variances  are independent of the estimators
are independent of the estimators 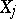 themselves.
themselves.
One of the most typical applications of the method of least squares is in the "smoothing" of observed results 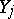 for which
for which 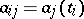 in equations (3), where the
in equations (3), where the 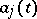 are known functions of some parameter
are known functions of some parameter 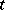 (if
(if 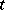 is time, then
is time, then 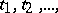 are the times at which the observations are made). A case encountered quite frequently in practical work is that known as parabolic interpolation, when the
are the times at which the observations are made). A case encountered quite frequently in practical work is that known as parabolic interpolation, when the 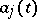 are polynomials (e.g.
are polynomials (e.g. 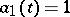 ,
, 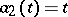 ,
, 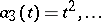 ); if
); if 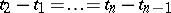 and if the observations are equally precise, then the estimators
and if the observations are equally precise, then the estimators 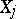 can be calculated by using tables of orthogonal polynomials. Another case of practical importance is harmonic interpolation, when the
can be calculated by using tables of orthogonal polynomials. Another case of practical importance is harmonic interpolation, when the 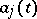 are trigonometric functions (e.g.
are trigonometric functions (e.g. 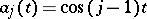 ,
, 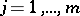 ).
).
Example. In order to estimate the precision of a certain method of chemical analysis, the method was used to determine the concentration of CaO in ten standard samples of known composition. The results are listed in the following table (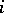 is the number of the experiment,
is the number of the experiment, 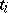 the true concentration of CaO,
the true concentration of CaO, 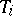 is the concentration of CaO determined by the chemical analysis,
is the concentration of CaO determined by the chemical analysis, 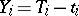 the error in chemical analysis):'
the error in chemical analysis):'
<tbody> </tbody>
|
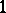


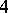

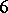
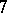
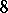
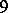

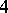

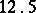
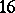
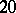
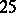
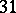
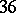
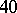
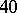
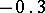
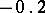
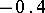
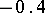
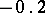
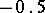
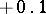
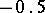


If the results of the chemical analysis do not involve systematic errors, then  . But if such errors exist, they may be represented as a first approximation by
. But if such errors exist, they may be represented as a first approximation by  (
(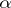 is known as the constant bias,
is known as the constant bias, 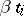 as the methodical bias) or, equivalently,
as the methodical bias) or, equivalently,
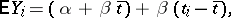 |
where
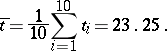 |
To find estimates of 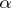 and
and 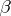 , it will suffice to estimate the quantities
, it will suffice to estimate the quantities 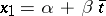 and
and 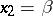 . The conditional equations here are
. The conditional equations here are
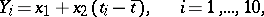 |
so that 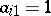 ,
, 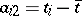 (since by assumption the observations are equally precise or homoscedastic (cf. Homoscedasticity),
(since by assumption the observations are equally precise or homoscedastic (cf. Homoscedasticity), 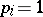 ). Since
). Since 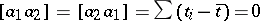 , the system of normal equations assumes a particularly simple form:
, the system of normal equations assumes a particularly simple form:
 |
where
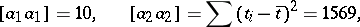 |
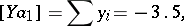 |
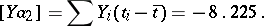 |
The variances of the components of the solution are
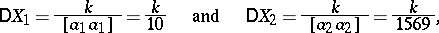 |
where 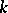 is the unknown variance per unit weight (in this case,
is the unknown variance per unit weight (in this case, 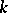 is the variance of any of the quantities
is the variance of any of the quantities 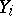 ). Since in this example the components of the solution have values
). Since in this example the components of the solution have values 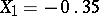 and
and 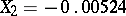 , one finds
, one finds
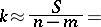 |
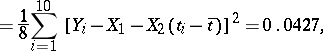 |
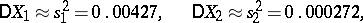 |
 |
If the random errors in the observations follow a normal law, then the quotients 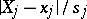 ,
, 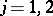 , are distributed according to a Student
, are distributed according to a Student 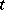 -distribution. In particular, if the results of the observations are free of systematic errors, then
-distribution. In particular, if the results of the observations are free of systematic errors, then 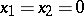 , so that the quotients
, so that the quotients 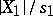 and
and 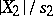 must follow a Student
must follow a Student 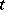 -distribution. Using tables of the Student distribution with
-distribution. Using tables of the Student distribution with 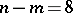 degrees of freedom, one verifies that if indeed
degrees of freedom, one verifies that if indeed 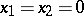 , then with probability 0.999 each of these quotients cannot exceed 5.04 and with probability 0.95 they will not exceed 2.31. In this case
, then with probability 0.999 each of these quotients cannot exceed 5.04 and with probability 0.95 they will not exceed 2.31. In this case 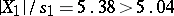 , and therefore the hypothesis that there are no systematic errors should be rejected. At the same time, it should be realized that the hypothesis of absence of systematic errors
, and therefore the hypothesis that there are no systematic errors should be rejected. At the same time, it should be realized that the hypothesis of absence of systematic errors 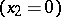 is not contradicted by the results of the observations, since
is not contradicted by the results of the observations, since 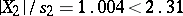 . Thus, it follows that the approximate formula
. Thus, it follows that the approximate formula 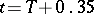 is a logical choice for the determination of
is a logical choice for the determination of 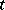 on the basis of the observed value
on the basis of the observed value  .
.
The case of several unknowns (non-linear relationships).
Suppose that the  results
results 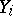 of measurements are related to the
of measurements are related to the 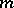 unknowns
unknowns 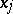 (
(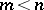 ) by means of functions
) by means of functions 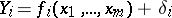 ,
, 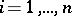 , where the
, where the  are independent random errors, and the functions
are independent random errors, and the functions 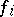 (which need not be linear) are differentiable. According to the method of least squares, estimators
(which need not be linear) are differentiable. According to the method of least squares, estimators 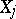 for the
for the 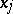 are those for which the sum of squares is smallest. Since the functions
are those for which the sum of squares is smallest. Since the functions 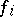 are non-linear, solving the normal equations
are non-linear, solving the normal equations 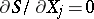 may present considerable difficulties. Sometimes non-linear relationships may be reduced to linear forms by transformation.
may present considerable difficulties. Sometimes non-linear relationships may be reduced to linear forms by transformation.
For example, in the magnetization of iron, the magnetic field strength 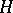 is related to the magnetic induction via the empirical formula
is related to the magnetic induction via the empirical formula 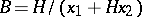 (the coefficients
(the coefficients  and
and  being determined by measuring the values of
being determined by measuring the values of 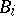 for various preassigned values
for various preassigned values 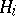 ). The induction
). The induction 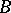 is a non-linear function of
is a non-linear function of 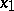 and
and 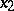 . However, the reciprocal of the induction is a linear function of
. However, the reciprocal of the induction is a linear function of 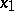 and
and 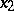 . Application of the method of least squares to the original and the transformed equations may well yield different estimates for the unknowns
. Application of the method of least squares to the original and the transformed equations may well yield different estimates for the unknowns 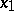 and
and  , but if the variance of the random errors involved in measuring the induction is significantly less than the measured quantities
, but if the variance of the random errors involved in measuring the induction is significantly less than the measured quantities 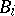 , then
, then 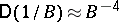 . Thus the quantities
. Thus the quantities 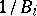 should be assigned weights
should be assigned weights 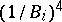 ; it is natural to expect that under these conditions the difference between estimates in the non-linear and linear cases is negligible for practical purposes.
; it is natural to expect that under these conditions the difference between estimates in the non-linear and linear cases is negligible for practical purposes.
In cases when it is not possible to replace the non-linear equations by linear ones via identity transformations, one resorts to another linearization technique. Inspecting the original  equations, single out any
equations, single out any 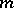 of them, the solution
of them, the solution 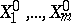 of which will serve as a zero-th approximation for the unknowns
of which will serve as a zero-th approximation for the unknowns 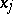 . Putting
. Putting 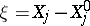 , the conditional equations may be rewritten as
, the conditional equations may be rewritten as
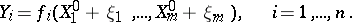 |
Expanding the terms on the right in powers of 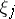 and dropping all but the linear terms, one obtains
and dropping all but the linear terms, one obtains
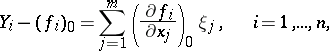 |
where 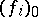 and
and 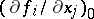 are the values of
are the values of 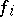 and its derivative with respect to
and its derivative with respect to 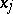 at the point
at the point 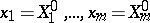 . This is a linear system of equations so that the method of least squares is readily applicable to determine estimates for the unknowns
. This is a linear system of equations so that the method of least squares is readily applicable to determine estimates for the unknowns 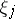 . Once this has been done, one obtains a first approximation for the unknown:
. Once this has been done, one obtains a first approximation for the unknown: 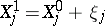 . These quantities are now treated as the initial approximation, and the entire procedure is repeated, as long as two consecutive approximations do not coincide to within the desired precision. If the variance of the errors
. These quantities are now treated as the initial approximation, and the entire procedure is repeated, as long as two consecutive approximations do not coincide to within the desired precision. If the variance of the errors 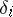 decreases, the procedure is convergent.
decreases, the procedure is convergent.
Very commonly, if 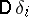 is small, the first approximation alone is quite sufficient; there is no point in requiring
is small, the first approximation alone is quite sufficient; there is no point in requiring 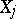 to be determined with precision significantly exceeding
to be determined with precision significantly exceeding 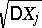 .
.
In many cases of practical importance (in particular, in the estimation of complicated non-linear relationships), the number of unknown parameters becomes very large, and so implementation of the method of least squares becomes effective only if modern computing techniques are employed.
References
| [1] | A.A. Markov, "Wahrscheinlichkeitsrechung" , Teubner (1912) (Translated from Russian) |
| [2] | A.N. Kolmogorov, "On substantiation of the method of least squares" Uspekhi Mat. Nauk , 1 : 1 (1946) pp. 57–70 (In Russian) |
| [3] | Yu.V. Linnik, "Methode der kleinste Quadraten in moderner Darstellung" , Deutsch. Verlag Wissenschaft. (1961) (Translated from Russian) |
| [4] | V.V. Nalimov, "The application of mathematical statistics to chemical analysis" , Pergamon (1963) (Translated from Russian) |
| [5] | F.R. Helmert, "Die Ausgleichungsrechnung nach der Methode der kleinsten Quadrate" , Teubner (1907) |
Comments
In fact, Gauss proposed the normal distribution as a way of justifying the method of least squares. Moreover, his original derivation of the least-square estimator as the "best linear unbiased estimator" (as it is nowadays interpreted; the so-called Gauss–Markov theorem) was actually a derivation of this estimator as "most likely value of m" in a Bayesian sense (cf. Bayesian approach), with respect to a uniform pivot on 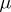 , cf. [a1].
, cf. [a1].
For (the results of) the use of least squares in estimating the coefficients of (presumed) linear relationships 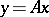 between repeatedly-measured vectors of variables
between repeatedly-measured vectors of variables 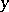 and
and  (linear regression), cf. Regression matrix and Regression analysis.
(linear regression), cf. Regression matrix and Regression analysis.
References
| [a1] | S.M. Stigler, "The history of statistics" , Harvard Univ. Press (1986) |
| [a2] | N.R. Draper, H. Smith, "Applied regression analysis" , Wiley (1981) |
| [a3] | C.R. Rao, "Linear statistical inference and its applications" , Wiley (1965) |
| [a4] | C. Daniel, F.S. Wood, "Fitting equations to data: computer analysis of multifactor data for scientists and engineers" , Wiley (1971) |
Least squares, method of. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Least_squares,_method_of&oldid=47599