Difference between revisions of "Algorithm, computational complexity of an"
(Importing text file) |
m (→Comments: links) |
||
| Line 45: | Line 45: | ||
The area has considerably expanded from the state described in the article above. Two key references [[#References|[a1]]], [[#References|[a5]]] are listed below. | The area has considerably expanded from the state described in the article above. Two key references [[#References|[a1]]], [[#References|[a5]]] are listed below. | ||
| − | The results on Turing machines referred to, up to the result on multiplication, hold for Turing machines in the original version only (single input/work tape, no extra work tapes). In the West, the standard Turing machine is nowadays the (off-line) model with multiple work tapes. Turing machines are useful, because of their simplicity, to obtain lower bounds on the computational complexity of problems. Upper bounds, by exhibiting actual algorithms, are usually based on the RAM (random access machine), which more realistically models the "von Neumann" computer. The two alternatives can simulate each other with a constant multiplicative factor in space and a polynomial time overhead. The latter property characterizes all "reasonable" models (First Machine Class) for sequential computations (Invariance Thesis). The determination of such overheads is a subject of the theory of machine models. For instance, multi-tape Turing machines with one-way input (no backup on the input tape) can be simulated in square time by a Turing machine with one-way input and a single work tape in an obvious way, and it has been shown that less than square time is insufficient [[#References|[a2]]], [[#References|[a3]]]. One can simulate <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180084.png" /> work tapes by 2 work tapes in time order <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180085.png" />; it is not known whether this is optimal, but the lower bound is non-linear. In contrast, multicounter machines can be simulated in real time (step-for-step) by a Turing machine with a single work tape [[#References|[a4]]]. (A counter is a storage device which can hold any integer and supports unit increments, unit decrements, and check for zero.) The Invariance Thesis yields a justification for the identification of the class of problems which can be solved deterministically in polynomial time (denoted by P) as the class of "tractable" problems. Adding the feature of non-determinism gives the class <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180087.png" /> (non-deterministic polynomial time), which is known to contain a large variety of problems which one likes to solve in daily life. The best known deterministic algorithms for solving <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180088.png" />-problems require exponential time. On the other hand, it is unknown whether <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180090.png" />. I.e., it is unknown whether these exponential time algorithms can be replaced by deterministic polynomial time ones. This question is generally considered the most important open problem in the theory of computation. It is known that the complexity of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180091.png" /> is exemplified in specific <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180092.png" /> problems. These <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180094.png" />-complete problems have the property that <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180095.png" /> if and only if such a problem can be solved in deterministic polynomial time (is in <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180096.png" />). Similar questions arise with respect to the relations between different space complexities, and the relations between time and space. The fundamental complexity classes related to space are PSPACE (NPSPACE), which consist of those problems which can be solved in polynomial space by deterministic (non-deterministic) machines from the First Machine Class. It is known (Savitch's theorem) that <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180097.png" />. Clearly, <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180098.png" /> contains <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180099.png" /> but it is unknown whether the inclusion is strict. | + | The results on Turing machines referred to, up to the result on multiplication, hold for Turing machines in the original version only (single input/work tape, no extra work tapes). In the West, the standard Turing machine is nowadays the (off-line) model with multiple work tapes. Turing machines are useful, because of their simplicity, to obtain lower bounds on the computational complexity of problems. Upper bounds, by exhibiting actual algorithms, are usually based on the RAM (random access machine), which more realistically models the "von Neumann" computer. The two alternatives can simulate each other with a constant multiplicative factor in space and a polynomial time overhead. The latter property characterizes all "reasonable" models (First Machine Class) for sequential computations (Invariance Thesis). The determination of such overheads is a subject of the theory of machine models. For instance, multi-tape Turing machines with one-way input (no backup on the input tape) can be simulated in square time by a Turing machine with one-way input and a single work tape in an obvious way, and it has been shown that less than square time is insufficient [[#References|[a2]]], [[#References|[a3]]]. One can simulate <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180084.png" /> work tapes by 2 work tapes in time order <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180085.png" />; it is not known whether this is optimal, but the lower bound is non-linear. In contrast, multicounter machines can be simulated in real time (step-for-step) by a Turing machine with a single work tape [[#References|[a4]]]. (A counter is a storage device which can hold any integer and supports unit increments, unit decrements, and check for zero.) The Invariance Thesis yields a justification for the identification of the class of problems which can be solved deterministically in polynomial time (denoted by P) as the class of "tractable" problems. Adding the feature of non-determinism gives the class <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180087.png" /> (non-deterministic polynomial time), which is known to contain a large variety of problems which one likes to solve in daily life. The best known deterministic algorithms for solving <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180088.png" />-problems require exponential time. On the other hand, it is unknown whether <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180090.png" />. I.e., it is unknown whether these exponential time algorithms can be replaced by deterministic polynomial time ones. This question is generally considered the most important open problem in the theory of computation. It is known that the complexity of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180091.png" /> is exemplified in specific <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180092.png" /> problems. These <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180094.png" />-complete problems have the property that <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180095.png" /> if and only if such a problem can be solved in deterministic polynomial time (is in <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180096.png" />). Similar questions arise with respect to the relations between different space complexities, and the relations between time and space. The fundamental complexity classes related to space are [[PSPACE]] ([[NPSPACE]]), which consist of those problems which can be solved in polynomial space by deterministic (non-deterministic) machines from the First Machine Class. It is known (Savitch's theorem) that <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180097.png" />. Clearly, <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180098.png" /> contains <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a01180099.png" /> but it is unknown whether the inclusion is strict. |
There exists a large variety of models for parallel computation. Many of those models (Second Machine Class) have the property that time on the parallel model is equivalent to space on the sequential model, up to a polynomial overhead (Parallel Computation Thesis). Each problem in <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a011800100.png" /> can be solved in deterministic polynomial time on a machine of the Second Machine Class. Other models seem to be even more powerfull, albeit totally unrealistic. The power of the parallel models is rooted in the possible activation of at least an exponential amount of hardware in a polynomial number of computation cycles (called "time" ). As soon as one enforces realistic bounds (e.g., because of the bounded speed of light) on the amount of hardware which can be activated by a computation in a given timespan, the Parallel Computation Thesis becomes invalid. For many specific problems it has been shown that they can be solved on a parallel device with a polynomial amount of hardware in time order <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a011800101.png" /> (<img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a011800102.png" /> complexity class). | There exists a large variety of models for parallel computation. Many of those models (Second Machine Class) have the property that time on the parallel model is equivalent to space on the sequential model, up to a polynomial overhead (Parallel Computation Thesis). Each problem in <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a011800100.png" /> can be solved in deterministic polynomial time on a machine of the Second Machine Class. Other models seem to be even more powerfull, albeit totally unrealistic. The power of the parallel models is rooted in the possible activation of at least an exponential amount of hardware in a polynomial number of computation cycles (called "time" ). As soon as one enforces realistic bounds (e.g., because of the bounded speed of light) on the amount of hardware which can be activated by a computation in a given timespan, the Parallel Computation Thesis becomes invalid. For many specific problems it has been shown that they can be solved on a parallel device with a polynomial amount of hardware in time order <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a011800101.png" /> (<img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/a/a011/a011800/a011800102.png" /> complexity class). | ||
Revision as of 06:57, 24 September 2017
A function giving a numerical estimate of the difficulty (amount of time/storage involved) of the process of application of an algorithm to the inputs. A more precise definition of the computational complexity of an algorithm is the concept of a cost function (step-counting function) — defined as a decidable relation between the objects to which the algorithm is applicable and the natural numbers, and which has a range of definition coinciding with the range of applicability of the algorithm.
Usually, the time and space characteristics of algorithmic processes are considered. Thus, for a Turing machine 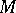 the time cost function (duration of work)
the time cost function (duration of work) 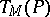 is the number
is the number 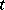 of cycles of work of
of cycles of work of 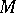 required for the conversion of the initial configuration of
required for the conversion of the initial configuration of 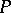 into the final configuration; the memory cost function (or space function)
into the final configuration; the memory cost function (or space function) 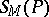 is defined as the number of cells on the tape scanned by the head of the machine. Time and storage costs for normal algorithms (cf. Normal algorithm), iterative arrays, multi-head and multi-tape Turing machines, etc., are defined in a similar manner.
is defined as the number of cells on the tape scanned by the head of the machine. Time and storage costs for normal algorithms (cf. Normal algorithm), iterative arrays, multi-head and multi-tape Turing machines, etc., are defined in a similar manner.
The common feature of such cost functions is the fact that there exists an effective procedure establishing for any algorithm 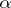 (i.e. in particular for a Turing machine or, rather, for its program), any input
(i.e. in particular for a Turing machine or, rather, for its program), any input  and any non-negative integer
and any non-negative integer 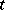 , whether or not the process of applying
, whether or not the process of applying 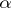 to
to  will terminate with complexity
will terminate with complexity 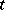 . This observation leads to the abstract theory of computational complexity [1]. An effective procedure
. This observation leads to the abstract theory of computational complexity [1]. An effective procedure  is called a computational measure if: 1) it always ends in the result 0 or 1 when applied to triplets of the form
is called a computational measure if: 1) it always ends in the result 0 or 1 when applied to triplets of the form 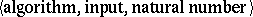 ; and 2) it has the property that for any algorithm
; and 2) it has the property that for any algorithm 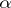 and any input
and any input  the equality
the equality 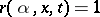 is true for not more than one natural number
is true for not more than one natural number 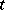 , this
, this 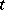 existing if and only if the process of application of
existing if and only if the process of application of 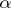 to
to  eventually terminates. The cost function
eventually terminates. The cost function 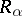 with respect to the measure
with respect to the measure  for
for 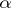 is introduced if and only if
is introduced if and only if 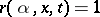 , and then
, and then 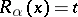 .
.
This last equality is equivalent to the statement "the computational complexity a on x is t (in the measure r)" .
Given some computational measure, one can consider the complexity of computation of a given function 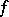 — for example, that of finding an algorithm
— for example, that of finding an algorithm  which computes
which computes 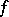 "better than other algorithms" . However, as exemplified by the speed-up theorem (see below), such a formulation is not always well-posed. The real problem may be the description of the rate of growth of the cost function
"better than other algorithms" . However, as exemplified by the speed-up theorem (see below), such a formulation is not always well-posed. The real problem may be the description of the rate of growth of the cost function 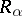 , where
, where 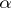 computes
computes 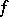 . For example, find upper and lower bounds for the computational complexity of
. For example, find upper and lower bounds for the computational complexity of 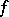 , i.e. two functions
, i.e. two functions 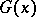 and
and 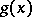 such that there exists a computation
such that there exists a computation 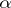 for the function
for the function 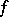 for which
for which 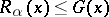 , and such that for any algorithm
, and such that for any algorithm 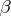 which computes
which computes 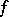 the function
the function 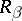 in a certain sense majorizes
in a certain sense majorizes 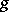 .
.
Another important branch of the theory of computational complexity is the study of complexity classes — sets of functions for which there exist computations with a complexity not exceeding some bound out of the set of bounds which defines the class. This branch also includes problems of comparative computational complexity for various types of algorithms (automata): the transition to another algorithmic system and another measure of complexity is usually equivalent to considering a new measure for the first algorithmic system.
Below a few fundamental results are given which are independent of the choice of measure of complexity (and of the formalization), as long as there exists, for example, an effective mutual simulation of the algorithms of the type under consideration and ordinary Turing machines. (For the sake of simplicity, it is assumed that the subject is the computation time of Turing machines computing functions from non-negative integers to non-negative integers.) Let 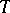 and
and 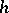 be computable integer-valued functions (cf. Computable function) on the domain of the algorithms, and let
be computable integer-valued functions (cf. Computable function) on the domain of the algorithms, and let  be a function defined on this domain which can assume two values only — say, 0 and 1.
be a function defined on this domain which can assume two values only — say, 0 and 1.
First, there exist functions whose computation may be as complex as one pleases. More exactly, for any function 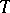 there exists a computable function
there exists a computable function 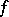 such that for any algorithm
such that for any algorithm 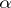 which computes
which computes 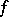 , the inequality
, the inequality
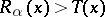 |
is false only in a finite number of cases.
Secondly, there exist functions, any computation of which may in principle be improved as much as one pleases. More precisely, the speed-up theorem is valid: For any function 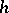 (e.g.
(e.g. 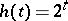 ) it is possible to find a computable function
) it is possible to find a computable function 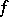 such that for any algorithm
such that for any algorithm 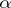 which computes
which computes 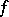 it will always be possible to find (no effective procedure is assumed) an algorithm
it will always be possible to find (no effective procedure is assumed) an algorithm 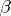 which also computes
which also computes 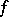 and such that for all
and such that for all  (except for a finite set)
(except for a finite set)
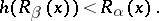 |
In case 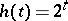 this yields
this yields
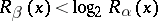 |
for almost all  .
.
For the computational measures of time and space (for Turing machines), the result of the speed-up theorem is valid for most computations in the following form: If 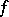 is computable with complexity
is computable with complexity 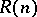 , it is also computable with complexity
, it is also computable with complexity 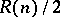 (one says that
(one says that 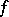 is computable with complexity
is computable with complexity 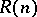 if, for some
if, for some 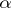 which computes it,
which computes it, 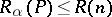 for all words
for all words 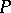 of length
of length  in the alphabet under consideration). For this reason time and space computational complexities of concrete functions are often order of magnitude estimates. Some specific results are quoted below.
in the alphabet under consideration). For this reason time and space computational complexities of concrete functions are often order of magnitude estimates. Some specific results are quoted below.
The time to decide the equality of words (of length  ) is of order
) is of order  for Turing machines and normal algorithms; any property of words which may be decided on Turing machines in a time asymptotically less than
for Turing machines and normal algorithms; any property of words which may be decided on Turing machines in a time asymptotically less than 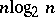 can also be decided in time
can also be decided in time  ; computations by a Turing machine of time
; computations by a Turing machine of time 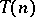 (with the order of
(with the order of 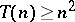 ) can be simulated by a Turing machine with space
) can be simulated by a Turing machine with space  . Furthermore, the multiplication of two
. Furthermore, the multiplication of two  -digit numbers on multi-tape Turing machines can be performed in time
-digit numbers on multi-tape Turing machines can be performed in time 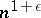 , but not in time order
, but not in time order  , but iterative arrays can achieve this in real time, i.e. the
, but iterative arrays can achieve this in real time, i.e. the 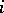 -th digit of the product is produced before the
-th digit of the product is produced before the 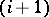 -th digits of the factors are inputted. When algorithmic processes of one type are modeled by other processes, the computational complexity usually changes. Thus, a reduction in the dimension of the iterative arrays results in longer computation time. Multi-head Turing machines and multi-tape Turing machines can simulate each other in real time. Many types of algorithms can be simulated on Turing machines, such that the computation time increases polynomially (usually quadratically) with an insignificant increase in space complexity (usually, an additional constant factor).
-th digits of the factors are inputted. When algorithmic processes of one type are modeled by other processes, the computational complexity usually changes. Thus, a reduction in the dimension of the iterative arrays results in longer computation time. Multi-head Turing machines and multi-tape Turing machines can simulate each other in real time. Many types of algorithms can be simulated on Turing machines, such that the computation time increases polynomially (usually quadratically) with an insignificant increase in space complexity (usually, an additional constant factor).
The complexity approach is useful in studying certain hierarchies of classes of general recursive functions (cf. General recursive function), in connection with their logical and algebraic features. For instance, primitive recursive functions coincide with the functions computable by Turing machines in space bounded by a primitive recursive function. The existence of arbitrarily complex functions is established by diagonalization methods. Natural analogues for such lower bounds on computational complexity were found for the validity problem in certain decidable theories and in areas related to mathematical linguistics. However, for many problems of practical importance the problem of obtaining non-trivial lower bounds presents considerable difficulties. This is the case, in particular, for certain combinatorial problems which are formalized (in one variant) as problems of finding, out of all words of a given word length, those which satisfy a predicate computable in polynomial time. One can also mention the complexity of the computations performed by non-deterministic automata and probabilistic automata (cf. Automaton, probabilistic). In the non-deterministic case the computational device can choose both ways when presented with a choice of how to continue the computation, by "splitting" into two independent copies, each of which has the same capabilities as its parent. Its computational complexity is understood to mean the complexity of the "simplest" successful computation trace. In the probabilistic case, the actual course of the computation is determined not only by the program and the argument, but also by a random sequence of numbers, and the result should coincide, to a great degree of probability, with the value of the function being computed. In both cases the computational complexity can sometimes be proved to be less than that of deterministic computations for the same problem.
The quality of algorithms is evaluated not only by their computational complexity, but also by the complexity of description an algorithm (cf. Algorithm, complexity of description of an). In some publications, both these approaches are combined.
References
| [1] | J. Hartmanis, J.E. Hopcroft, "An overview of the theory of computational complexity" J. ACM , 18 (1971) pp. 444–475 |
Comments
The area has considerably expanded from the state described in the article above. Two key references [a1], [a5] are listed below.
The results on Turing machines referred to, up to the result on multiplication, hold for Turing machines in the original version only (single input/work tape, no extra work tapes). In the West, the standard Turing machine is nowadays the (off-line) model with multiple work tapes. Turing machines are useful, because of their simplicity, to obtain lower bounds on the computational complexity of problems. Upper bounds, by exhibiting actual algorithms, are usually based on the RAM (random access machine), which more realistically models the "von Neumann" computer. The two alternatives can simulate each other with a constant multiplicative factor in space and a polynomial time overhead. The latter property characterizes all "reasonable" models (First Machine Class) for sequential computations (Invariance Thesis). The determination of such overheads is a subject of the theory of machine models. For instance, multi-tape Turing machines with one-way input (no backup on the input tape) can be simulated in square time by a Turing machine with one-way input and a single work tape in an obvious way, and it has been shown that less than square time is insufficient [a2], [a3]. One can simulate 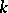 work tapes by 2 work tapes in time order
work tapes by 2 work tapes in time order 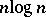 ; it is not known whether this is optimal, but the lower bound is non-linear. In contrast, multicounter machines can be simulated in real time (step-for-step) by a Turing machine with a single work tape [a4]. (A counter is a storage device which can hold any integer and supports unit increments, unit decrements, and check for zero.) The Invariance Thesis yields a justification for the identification of the class of problems which can be solved deterministically in polynomial time (denoted by P) as the class of "tractable" problems. Adding the feature of non-determinism gives the class
; it is not known whether this is optimal, but the lower bound is non-linear. In contrast, multicounter machines can be simulated in real time (step-for-step) by a Turing machine with a single work tape [a4]. (A counter is a storage device which can hold any integer and supports unit increments, unit decrements, and check for zero.) The Invariance Thesis yields a justification for the identification of the class of problems which can be solved deterministically in polynomial time (denoted by P) as the class of "tractable" problems. Adding the feature of non-determinism gives the class 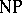 (non-deterministic polynomial time), which is known to contain a large variety of problems which one likes to solve in daily life. The best known deterministic algorithms for solving
(non-deterministic polynomial time), which is known to contain a large variety of problems which one likes to solve in daily life. The best known deterministic algorithms for solving 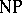 -problems require exponential time. On the other hand, it is unknown whether
-problems require exponential time. On the other hand, it is unknown whether  . I.e., it is unknown whether these exponential time algorithms can be replaced by deterministic polynomial time ones. This question is generally considered the most important open problem in the theory of computation. It is known that the complexity of
. I.e., it is unknown whether these exponential time algorithms can be replaced by deterministic polynomial time ones. This question is generally considered the most important open problem in the theory of computation. It is known that the complexity of 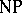 is exemplified in specific
is exemplified in specific  problems. These
problems. These 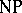 -complete problems have the property that
-complete problems have the property that 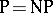 if and only if such a problem can be solved in deterministic polynomial time (is in
if and only if such a problem can be solved in deterministic polynomial time (is in 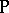 ). Similar questions arise with respect to the relations between different space complexities, and the relations between time and space. The fundamental complexity classes related to space are PSPACE (NPSPACE), which consist of those problems which can be solved in polynomial space by deterministic (non-deterministic) machines from the First Machine Class. It is known (Savitch's theorem) that
). Similar questions arise with respect to the relations between different space complexities, and the relations between time and space. The fundamental complexity classes related to space are PSPACE (NPSPACE), which consist of those problems which can be solved in polynomial space by deterministic (non-deterministic) machines from the First Machine Class. It is known (Savitch's theorem) that 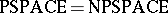 . Clearly,
. Clearly,  contains
contains 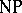 but it is unknown whether the inclusion is strict.
but it is unknown whether the inclusion is strict.
There exists a large variety of models for parallel computation. Many of those models (Second Machine Class) have the property that time on the parallel model is equivalent to space on the sequential model, up to a polynomial overhead (Parallel Computation Thesis). Each problem in 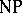 can be solved in deterministic polynomial time on a machine of the Second Machine Class. Other models seem to be even more powerfull, albeit totally unrealistic. The power of the parallel models is rooted in the possible activation of at least an exponential amount of hardware in a polynomial number of computation cycles (called "time" ). As soon as one enforces realistic bounds (e.g., because of the bounded speed of light) on the amount of hardware which can be activated by a computation in a given timespan, the Parallel Computation Thesis becomes invalid. For many specific problems it has been shown that they can be solved on a parallel device with a polynomial amount of hardware in time order
can be solved in deterministic polynomial time on a machine of the Second Machine Class. Other models seem to be even more powerfull, albeit totally unrealistic. The power of the parallel models is rooted in the possible activation of at least an exponential amount of hardware in a polynomial number of computation cycles (called "time" ). As soon as one enforces realistic bounds (e.g., because of the bounded speed of light) on the amount of hardware which can be activated by a computation in a given timespan, the Parallel Computation Thesis becomes invalid. For many specific problems it has been shown that they can be solved on a parallel device with a polynomial amount of hardware in time order 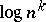 (
(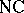 complexity class).
complexity class).
References
| [a1] | M.R. Gary, "Computers and intractability: a guide to the theory of NP-completeness" , Freeman (1978) |
| [a2] | W. Maass, "Combinatorial lower bound arguments for deterministic and nondeterministic Turing machines" Trans. Amer. Math. Soc. , 292 (1985) pp. 675–693 |
| [a3] | P.M.B. Vitányi, M. Li, "Tape versus stack and queue: the lower bounds" Information and Computation (To appear) |
| [a4] | P.M.B. Vitányi, "An optimal simulation of counter machines" SIAM J. on Computing , 14 (1985) pp. 1–33 |
| [a5] | K. Wagner, G. Wechsung, "Complexity theory" , Reidel (1986) |
Algorithm, computational complexity of an. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Algorithm,_computational_complexity_of_an&oldid=41941