Difference between revisions of "Confidence estimation"
m |
m |
||
| Line 1: | Line 1: | ||
| − | {{TEX| | + | {{TEX|want}} |
A method in mathematical statistics for the construction of a set of approximate values of the unknown parameters of probability distributions. | A method in mathematical statistics for the construction of a set of approximate values of the unknown parameters of probability distributions. | ||
Revision as of 10:22, 11 December 2013
A method in mathematical statistics for the construction of a set of approximate values of the unknown parameters of probability distributions.
Let 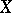 be a random vector assuming values in a set
be a random vector assuming values in a set 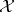 in a Euclidean space and let the probability distribution of this vector belong to the parametric family of distributions defined by the densities
in a Euclidean space and let the probability distribution of this vector belong to the parametric family of distributions defined by the densities 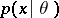 ,
, 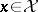 ,
, 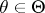 , with respect to some measure
, with respect to some measure 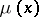 . It is assumed that the true value of the parametric point
. It is assumed that the true value of the parametric point 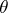 corresponding to the result of observations of
corresponding to the result of observations of 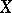 is unknown. Confidence estimation consists in constructing a certain set
is unknown. Confidence estimation consists in constructing a certain set 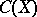 , depending on
, depending on 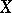 , containing the value of a given function
, containing the value of a given function 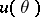 corresponding to the unknown true value of
corresponding to the unknown true value of 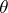 .
.
Let 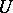 be the range of values of the function
be the range of values of the function 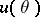 ,
, 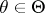 , and let
, and let 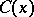 ,
, 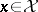 , be some family of sets belonging to
, be some family of sets belonging to 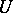 for all
for all  from
from 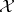 ; moreover, it is assumed that for an arbitrary element
; moreover, it is assumed that for an arbitrary element 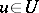 and any value of
and any value of 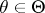 the probability of the event
the probability of the event 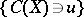 is defined. This probability is given by the integral
is defined. This probability is given by the integral
 |
and is said to be the covering probability of the value of  by the set
by the set 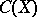 for a given value of
for a given value of 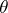 .
.
If the true value of 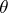 is unknown, the set
is unknown, the set 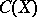 (from the family of sets
(from the family of sets 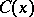 ,
, 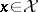 ) which corresponds to the results of observations of
) which corresponds to the results of observations of 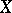 is said to be a confidence set or an interval estimator for the unknown true value of the function
is said to be a confidence set or an interval estimator for the unknown true value of the function 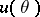 . The confidence probability
. The confidence probability 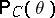 , which can be expressed, in terms of the covering probability, by the equation
, which can be expressed, in terms of the covering probability, by the equation
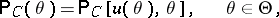 |
is employed as the probability characteristic of the interval estimator 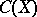 constructed according to the above rule. In other words,
constructed according to the above rule. In other words, 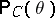 is the probability of covering by the set
is the probability of covering by the set 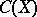 of the value of a given function
of the value of a given function 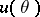 corresponding to the unknown true parametric point
corresponding to the unknown true parametric point 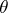 .
.
If the confidence probability 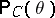 is independent of
is independent of 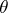 , the interval estimator
, the interval estimator 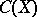 is said to be similar to the sampling space. This name is due to the analogy between the formulas
is said to be similar to the sampling space. This name is due to the analogy between the formulas
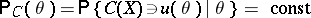 |
and
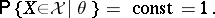 |
In a more general situation 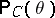 depends on the unknown
depends on the unknown 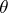 , and for this reason the quality of the interval estimator is usually characterized in practical work by the confidence level
, and for this reason the quality of the interval estimator is usually characterized in practical work by the confidence level
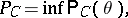 |
where the lower bound is calculated over the set 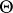 . (The confidence level is sometimes called the confidence coefficient.)
. (The confidence level is sometimes called the confidence coefficient.)
Optimization of confidence estimation is defined by the requirements to be met by interval estimators. For instance, if the objective is to construct confidence sets similar to sampling spaces, with a given confidence level 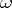 (
(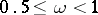 ), the first requirement is expressed by the identity
), the first requirement is expressed by the identity
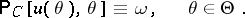 |
It is natural to look for an interval estimator that covers the true value of 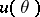 with a probability at least that of covering an arbitrary value
with a probability at least that of covering an arbitrary value 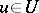 . In other words, the second requirement, known as the requirement of unbiasedness, is expressed by the inequality
. In other words, the second requirement, known as the requirement of unbiasedness, is expressed by the inequality
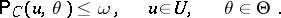 |
Under these conditions, the "best" interval estimator 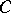 may reasonably be taken as one which covers any value
may reasonably be taken as one which covers any value  other than the true value
other than the true value 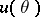 with a smaller probability. Hence the third requirement of "highest accuracy" : For any set
with a smaller probability. Hence the third requirement of "highest accuracy" : For any set 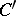 other than
other than 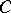 and meeting the condition
and meeting the condition
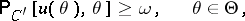 |
the inequality
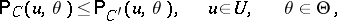 |
must be valid.
The task of finding interval estimators 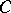 satisfying all three requirements is equivalent to the task of constructing unbiased most-powerful statistical tests similar to the sampling space and having significance level
satisfying all three requirements is equivalent to the task of constructing unbiased most-powerful statistical tests similar to the sampling space and having significance level 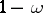 . The problem of the existence of a solution to this problem and its constructive description form the base of the general theory of statistical hypothesis testing.
. The problem of the existence of a solution to this problem and its constructive description form the base of the general theory of statistical hypothesis testing.
Confidence estimation is most often used when 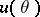 is a scalar function. Let
is a scalar function. Let 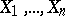 ,
, 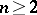 , be independent random variables subject to the same normal distribution, with the unknown parameters
, be independent random variables subject to the same normal distribution, with the unknown parameters 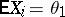 and
and 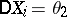 . The problem is to construct an interval estimator for
. The problem is to construct an interval estimator for 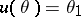 . Let
. Let
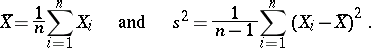 |
Since the random variable 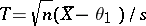 is subject to the Student distribution with
is subject to the Student distribution with 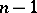 degrees of freedom, and since this distribution does not depend on the unknown parameters
degrees of freedom, and since this distribution does not depend on the unknown parameters 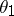 and
and 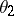 (
(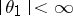 ,
, 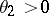 ), it follows that, for any positive
), it follows that, for any positive  , the probability of occurrence of the event
, the probability of occurrence of the event
 |
depends only on 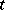 . If this interval is taken as the interval estimator
. If this interval is taken as the interval estimator 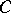 for
for 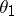 , it will correspond to the confidence probability
, it will correspond to the confidence probability
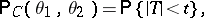 |
which is independent of 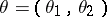 . Such an interval estimator is known as a confidence interval, while its end points are known as confidence bounds; in this case the confidence interval is a confidence estimator similar to the sampling space. In this example the interval estimator is most accurate unbiased.
. Such an interval estimator is known as a confidence interval, while its end points are known as confidence bounds; in this case the confidence interval is a confidence estimator similar to the sampling space. In this example the interval estimator is most accurate unbiased.
References
| [1] | S.S. Wilks, "Mathematical statistics" , Wiley (1962) |
| [2] | L. Schmetterer, "Introduction to mathematical statistics" , Springer (1974) (Translated from German) |
| [3] | E.L. Lehmann, "Testing statistical hypotheses" , Wiley (1986) |
| [4] | L.N. Bol'shev, "On the construction of confidence limits" Theor. Probab. Appl. , 10 (1965) pp. 173–177 Teor. Veroyatnost. i Primenen. , 10 : 1 (1965) pp. 187–192 |
Confidence estimation. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Confidence_estimation&oldid=30939