Analytic model of a language
analyzing model of a language
A type of mathematical construction used in mathematical linguistics to describe the structure of natural languages. These constructions are used in the formal modelling of basic linguistic categories and of the process of linguistic research itself; in other words, certain sets of "disordered" data about the language (or, more exactly, about speech) are used to deduce certain information about the structural mechanism of the language, i.e. about its grammar in the wider sense of this word. The "functioning" of such a model does not always have the character of an effective construction, since the set of initial data need not be a constructive object; in principle, this does not render such models inferior.
In the most fully developed analytic models of languages, the set of initial data is usually an object which models a set of grammatical sentences of a natural language, viz. some formal language in a given alphabet (vocabulary) 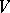 . If
. If 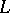 is a language in the vocabulary
is a language in the vocabulary 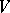 and
and 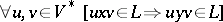 , then one says that the string
, then one says that the string  can be substituted by the string
can be substituted by the string 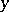 with respect to
with respect to 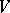 and
and 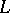 ; if each one the strings
; if each one the strings  and
and 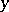 can be substituted by the other with respect to
can be substituted by the other with respect to 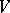 and
and 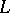 , then one says that
, then one says that  and
and 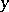 can be mutually substituted with respect to
can be mutually substituted with respect to 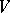 and
and 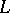 . The concept of mutual substitutability has a simple linguistic meaning: If
. The concept of mutual substitutability has a simple linguistic meaning: If 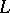 is understood to be the set of grammatical sentences of some natural language, the mutually substitutable sets are "syntactically equivalent" (i.e. fulfilling the same syntactic functions) word combinations. In particular, if a single-symbol string
is understood to be the set of grammatical sentences of some natural language, the mutually substitutable sets are "syntactically equivalent" (i.e. fulfilling the same syntactic functions) word combinations. In particular, if a single-symbol string  (in linguistic interpretation: a word) is mutually substitutable with a string
(in linguistic interpretation: a word) is mutually substitutable with a string  of length
of length 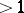 ,
,  is a "potential constituent" , i.e. may be a constituent of the linguistically natural constituent structures of grammatical sentences of this language (cf. Syntactic structure); in such a case the string
is a "potential constituent" , i.e. may be a constituent of the linguistically natural constituent structures of grammatical sentences of this language (cf. Syntactic structure); in such a case the string  is called a first rank configuration of the language
is called a first rank configuration of the language 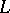 with resultant
with resultant  . Thus, in the English language, the string "uniformly continuous" can be regarded as a first rank configuration with resultant "continuous" . However, first rank configurations do not exhaust all "potential constituents" ; for example, the word combination "continuous function" is not a first rank configuration, since only words such as "function" , "derivative" , etc., can be substituted by it, but it cannot itself be substituted by any of these words ( "fx is a uniformly continuous function" is a correct statement, but "fx is a uniform function" is not). Therefore one introduces the following definition: If
. Thus, in the English language, the string "uniformly continuous" can be regarded as a first rank configuration with resultant "continuous" . However, first rank configurations do not exhaust all "potential constituents" ; for example, the word combination "continuous function" is not a first rank configuration, since only words such as "function" , "derivative" , etc., can be substituted by it, but it cannot itself be substituted by any of these words ( "fx is a uniformly continuous function" is a correct statement, but "fx is a uniform function" is not). Therefore one introduces the following definition: If 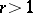 is a natural number and if the concept of a rank
is a natural number and if the concept of a rank 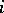 configuration of the language
configuration of the language 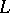 has been defined for each
has been defined for each 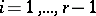 , then a string
, then a string  of length
of length 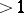 is called a rank
is called a rank  configuration of the language
configuration of the language 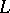 with resultant
with resultant  , where
, where 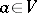 , if the following condition holds: If
, if the following condition holds: If  can be substituted by
can be substituted by  with respect to
with respect to 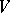 and
and 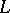 , if
, if 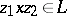 and if
and if 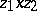 does not contain occurrances of configurations of ranks lower than
does not contain occurrances of configurations of ranks lower than  overlapping the considered
overlapping the considered  but not entirely contained in it, then
but not entirely contained in it, then 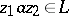 . In English, the word combination "continuous function" can be regarded as a second rank configuration, the word "function" being the resultant (the word "derivative" , for example, is also a resultant). It may be shown that, in a certain sense, a language is fully determined by the set of its configurations.
. In English, the word combination "continuous function" can be regarded as a second rank configuration, the word "function" being the resultant (the word "derivative" , for example, is also a resultant). It may be shown that, in a certain sense, a language is fully determined by the set of its configurations.
The configurational model belongs to the so-called syntagmatic analytic models of a language, which are intended to describe the relations between the elements of segments of speech (in linguistics such relations are called syntagmatic). Another class of analytic models of a language are paradigmatic models, intended to describe paradigmatic relations, i.e. relations between the elements of a language in its system. In such models the usual procedure is to construct certain relations on the vocabulary, which are often (but not always) equivalence relations. In particular, paradigmatic analytic models of a language serve to construct formal analogues of traditional linguistic categories such as parts of speech, case, gender, phoneme, etc. A set of grammatical sentences also serves as the "starting material" in many paradigmatic analytic models of a language; the concept of substitutability is employed in several models of this type. The simplest equivalence relation obtained in this way is the mutual substitutability relation on the vocabulary (i.e. on the set of all one-element strings); the equivalence classes induced by this relation are called families. If one introduces an additional relation on the vocabulary, consisting of "to be different forms of the same word" (more precisely, of one lexeme; this is, e.g., the relation between "to limit" and "limiting" or between "number" and "numbers" ; it involves a certain idealization in that it is assumed that a word may be the form of one lexeme only; the respective equivalence classes are called neighbourhoods), then these two relations may be used to introduce certain other classifications, which may be regarded as approximations to the formal analogues of parts of speech and other traditional grammatical concepts, in particular the concepts of case and gender of nouns. These last two concepts are particularly intensively studied; a number of models based on the concept of grammaticality as well as other types of models have been suggested for their formalization. In one model, in particular, each case of nouns is treated as a set of "uniformly directed" forms of nouns, while each gender is treated as a set of "uniformly directing" nouns. The initial data in this model, which serve to determine the gender, are the vocabulary, the set of neighbourhoods, the set of nouns and the binary relation of "potential subordination" in the vocabulary:  potentially subordinates
potentially subordinates 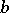 if, in some "linguistically natural" dependency structure (cf. Syntactic structure) of a grammatical sentence in this language, some occurrence of
if, in some "linguistically natural" dependency structure (cf. Syntactic structure) of a grammatical sentence in this language, some occurrence of 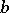 (immediately) depends on some occurrence of
(immediately) depends on some occurrence of  ; additional initial data of the same nature are added to determine the gender. Models based on "potential subordination" or other concepts related to dependency structures apparently permit a better formalization of traditional grammatical categories than do models involving strings only, since in the former models syntactic and linear relations are separated (cf. Grammar, transformational).
; additional initial data of the same nature are added to determine the gender. Models based on "potential subordination" or other concepts related to dependency structures apparently permit a better formalization of traditional grammatical categories than do models involving strings only, since in the former models syntactic and linear relations are separated (cf. Grammar, transformational).
The mathematical apparatus employed in the construction of analytic models of a language is usually fairly simple. In some models it merely involves the simplest concepts of set theory (such models are frequently called set-theoretic, and this term is sometimes extended to cover all analytic models of a language). In other cases algebraic concepts are employed, in particular those of the theory of semi-groups and of the algebra of binary relations; this is why the theory of analytic models of a language is sometimes referred to as algebraic linguistics.
References
| [1] | O.S. Kulagina, "On a means of defining grammatical concepts on the base of set theory" Problemy Kibernet. , 1 (1958) pp. 203–214 (In Russian) |
| [2] | V.A. Uspenskii, "On the Kolmogorov definition of case" Byull. Obshch. Problemy Mashinnogo Perevoda : 5 (1957) pp. 11–18 (In Russian) |
| [3] | V.A. Uspenskii, "A model for the concept of phoneme" Voprosy Yazykoznaniya : 6 (1964) pp. 39–53 (In Russian) |
| [4] | S. Markus, "Algebraic linguistics: analytical models" , Acad. Press (1967) |
| [5] | I.I. Revzin, "Modelling and typologizing Slavic languages" , Moscow (1967) (In Russian) |
| [6] | A.V. [A.V. Gladkii] Gladkij, I.A. [I.A. Mel'chuk] Mel'Avcuk, "Elements of mathematical linguistics" , Mouton (1983) |
| [7] | A.V. Gladkii, "Formal grammars and languages" , Moscow (1973) (In Russian) |
Analytic model of a language. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Analytic_model_of_a_language&oldid=45177