Difference between revisions of "Intermediate efficiency"
(Importing text file) |
(latex details) |
||
| (2 intermediate revisions by one other user not shown) | |||
| Line 1: | Line 1: | ||
| + | <!--This article has been texified automatically. Since there was no Nroff source code for this article, | ||
| + | the semi-automatic procedure described at https://encyclopediaofmath.org/wiki/User:Maximilian_Janisch/latexlist | ||
| + | was used. | ||
| + | If the TeX and formula formatting is correct and if all png images have been replaced by TeX code, please remove this message and the {{TEX|semi-auto}} category. | ||
| + | |||
| + | Out of 112 formulas, 111 were replaced by TEX code.--> | ||
| + | |||
| + | {{TEX|semi-auto}}{{TEX|part}} | ||
''Kallenberg efficiency'' | ''Kallenberg efficiency'' | ||
| − | A concept used to compare the performance of statistical tests (cf. also [[Statistical hypotheses, verification of|Statistical hypotheses, verification of]]). Write | + | A concept used to compare the performance of statistical tests (cf. also [[Statistical hypotheses, verification of|Statistical hypotheses, verification of]]). Write $N ( \alpha , \beta , \theta )$ for the sample size required to attain with a level-$\alpha$ test a prescribed power $\beta$ at an alternative $\theta$. If one has two tests with corresponding numbers $N _ { 1 }$ and $N_{2}$, respectively, the ratio $N _ { 2 } / N _ { 1 }$ is called the relative efficiency of test $1$ with respect to test $2$. If the relative efficiency equals $3$, test $2$ needs $3$ times as much observations to perform equally well as test $1$ and hence test $1$ is $3$ times as efficient as test $2$ (cf. also [[Efficient test|Efficient test]]). |
| − | In general, the relative efficiency is hard to compute and, if it can be computed, hard to evaluate, as it depends on three arguments: | + | In general, the relative efficiency is hard to compute and, if it can be computed, hard to evaluate, as it depends on three arguments: $\alpha$, $\beta$ and $\theta$. (Note that $\theta$ is not restricted to be a Euclidean parameter; it can also be an abstract parameter, as for instance the distribution function.) Therefore, an asymptotic approach, where $N$ tends to infinity, is welcome to simplify both the computation and interpretation, thus hoping that the limit gives a sufficiently good approximation of the far more complicated finite-sample case. |
| − | When sending | + | When sending $N$ to infinity, two guiding principles are: |
| − | a) to "decrease the significance probability as N increases" , i.e. to send | + | a) to "decrease the significance probability as N increases" , i.e. to send $\alpha$ to $0$; or |
| − | b) to "move the alternative hypothesis steadily closer to the null hypothesis" , i.e. to send | + | b) to "move the alternative hypothesis steadily closer to the null hypothesis" , i.e. to send $\theta$ to $H _ { 0 }$. Both principles are attractive: with more observations it seems reasonable to have a stronger requirement on the level and, on the other hand, for alternatives far away from the null hypothesis there is no need for statistical methods, since they are obviously different from $H _ { 0 }$. |
In Pitman's asymptotic efficiency concept, method b) is used, while one deals with fixed levels, thus ignoring principle a). In Bahadur's asymptotic efficiency concept, method a) is actually used, while one considers fixed alternatives, thereby ignoring principle b). (Cf. also [[Bahadur efficiency|Bahadur efficiency]]; [[Efficiency, asymptotic|Efficiency, asymptotic]].) Intermediate or Kallenberg efficiency applies both attractive principles simultaneously. | In Pitman's asymptotic efficiency concept, method b) is used, while one deals with fixed levels, thus ignoring principle a). In Bahadur's asymptotic efficiency concept, method a) is actually used, while one considers fixed alternatives, thereby ignoring principle b). (Cf. also [[Bahadur efficiency|Bahadur efficiency]]; [[Efficiency, asymptotic|Efficiency, asymptotic]].) Intermediate or Kallenberg efficiency applies both attractive principles simultaneously. | ||
| − | As a consequence of Bahadur's approach, in typical cases the level of significance | + | As a consequence of Bahadur's approach, in typical cases the level of significance $\alpha _ { N }$ required to attain a fixed power $\beta$ at a fixed alternative $\theta$ tends to zero at an exponential rate as the number of observations $N$ tends to infinity. There remains a whole range of sequences of levels "intermediate" between these two extremes of very fast convergence to zero of $\alpha _ { N }$ and the fixed $\alpha$ in the case of Pitman efficiency. The efficiency concept introduced by W.C.M. Kallenberg [[#References|[a11]]] deals with this intermediate range and is therefore called intermediate efficiency, or, for short, i-efficiency. |
A related approach is applied by P. Groeneboom [[#References|[a5]]], Sect. 3.4, studying very precisely the behaviour of several tests for the multivariate linear hypothesis from an "intermediate" point of view. Other efficiency concepts with an "intermediate" flavour can be found in [[#References|[a6]]], [[#References|[a18]]] and [[#References|[a2]]]. | A related approach is applied by P. Groeneboom [[#References|[a5]]], Sect. 3.4, studying very precisely the behaviour of several tests for the multivariate linear hypothesis from an "intermediate" point of view. Other efficiency concepts with an "intermediate" flavour can be found in [[#References|[a6]]], [[#References|[a18]]] and [[#References|[a2]]]. | ||
| Line 19: | Line 27: | ||
Instead of applying principles a) and b) simultaneously, in a lot of papers they are applied one after the other. For an excellent treatment in the case of non-parametric tests see [[#References|[a16]]], where also many further references can be found (cf. also [[Non-parametric test|Non-parametric test]]). General results on limiting equivalence of local and non-local measures of efficiency are presented in [[#References|[a4]]], [[#References|[a14]]] and [[#References|[a13]]]. | Instead of applying principles a) and b) simultaneously, in a lot of papers they are applied one after the other. For an excellent treatment in the case of non-parametric tests see [[#References|[a16]]], where also many further references can be found (cf. also [[Non-parametric test|Non-parametric test]]). General results on limiting equivalence of local and non-local measures of efficiency are presented in [[#References|[a4]]], [[#References|[a14]]] and [[#References|[a13]]]. | ||
| − | The definition of intermediate or Kallenberg efficiency is as follows. Let | + | The definition of intermediate or Kallenberg efficiency is as follows. Let $X _ { 1 } , X _ { 2 } , \dots$ be a sequence of independent, identically distributed random variables with distribution $P _ { \theta }$ for some $\theta$ in the parameter space $\Theta$. The hypothesis $H _ { 0 }$: $\theta \in \Theta _ { 0 }$ has to be tested against $H _ { 1 }$: $\theta \in \Theta _ { 1 } \subset \Theta - \Theta _ { 0 }$, where $\Theta _ { 0 }$ and $\Theta _ { 1 }$ are given subsets of $\Theta$. For a family of tests $\{ T ( n , \alpha ) : n \in \mathbf{N} , 0 < \alpha < 1 \}$, denote the power at $\theta$ by $\beta ( n , \alpha , \theta ; T )$, where $n$ is the available number of observations and $\alpha$ is the level of the test (cf. also [[Significance level|Significance level]]). Suppose one has two families of tests, $\{ T ( n , \alpha ) \}$ and $\{ V ( n , \alpha ) \}$. Let $\{ \alpha _ { n } \}$ be a sequence of levels with |
| − | + | \begin{equation} \tag{a1} \operatorname { lim } _ { n \rightarrow \infty } \alpha _ { n } = 0 = \operatorname { lim } _ { n \rightarrow \infty } n ^ { - 1 } \operatorname { log } \alpha _ { n }, \end{equation} | |
| − | thus ensuring that | + | thus ensuring that $\alpha _ { n }$ tends to $0$, but not exponentially fast. Let $\{ \theta _ { n } \}$ be a sequence of alternatives tending to the null hypothesis, in the sense that |
| − | + | \begin{equation} \tag{a2} \operatorname { lim } _ { n \rightarrow \infty } H ( \theta _ { n } , \Theta _ { 0 } ) = 0 , \operatorname { lim } _ { n \rightarrow \infty } n H ^ { 2 } ( \theta _ { n } , \Theta _ { 0 } ) = \infty , \end{equation} | |
and | and | ||
| − | + | \begin{equation} \tag{a3} 0 < \operatorname { liminf } _ { n \rightarrow \infty } \beta ( n , \alpha , \theta ; T ) \leq \operatorname { limsup } _ { n \rightarrow \infty } \beta ( n , \alpha , \theta ; T ) < 1. \end{equation} | |
| − | Here, | + | Here, $H ( \theta , \Theta _ { 0 } ) = \operatorname { inf } \{ H ( \theta , \theta _ { 0 } ) : \theta _ { 0 } \in \Theta _ { 0 } \}$ and $H ( \theta , \theta _ { 0 } )$ denotes the [[Hellinger distance|Hellinger distance]] between the probability measures $P _ { \theta }$ and $P _ { \theta _ { 0 } }$. This ensures that the alternatives tend to $H _ { 0 }$, but in a slower way than contiguous alternatives, cf. [[#References|[a17]]]. Typically, for Euclidean parameters, $H ( \theta , \theta _ { 0 } ) \sim c \| \theta - \theta _ { 0 } \| ^ { 2 }$ as $\theta \rightarrow \theta _ { 0 }$ and hence in such cases formula (a3) concerns convergence of $\theta _ { n }$ to $\Theta _ { 0 }$ at a rate slower than $n ^ { - 1 / 2 }$. (The latter is the usual rate for contiguous alternatives.) |
| − | Define | + | Define $m ( n ; T , V )$ as the smallest number of observations needed for $V$ to perform as well as $T$ in the sense that $\beta ( m + k , \alpha _ { n } , \theta _ { n } ; V )$, the power at $\theta _ { n }$ of the level-$\alpha _ { n }$ test of $V$ based on $m + k$ observations, is, for all <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/i/i120/i120050/i12005077.png"/>, at least as large as $\beta ( m , \alpha _ { n } , \theta _ { n } ; T )$, the power at $\theta _ { n }$ of the level-$\alpha _ { n }$ test of $T$ based on $n$ observations. If the sequence of levels $\{ \alpha _ { n } \}$ satisfies next to (a1) also |
| − | + | \begin{equation} \tag{a4} \operatorname { log } \alpha _ { n } = o ( n ^ { 1 / 3 } ) \text { as } n \rightarrow \infty \end{equation} | |
and if | and if | ||
| − | + | \begin{equation*} e ( T , V ) = \operatorname { lim } _ { n \rightarrow \infty } \frac { m ( n ; T , V ) } { n } \end{equation*} | |
| − | exists and does not depend on the special sequences | + | exists and does not depend on the special sequences $\{ \theta _ { n } \}$, $\{ \alpha _ { n } \}$ under consideration, one says that the intermediate or Kallenberg efficiency of $T$ with respect to $V$ equals $e ( T , V )$. If (a4) is replaced by |
| − | + | \begin{equation*} \operatorname { log } \alpha _ { n } = o ( \operatorname { log } n ) \text { as } n \rightarrow \infty \end{equation*} | |
| − | one speaks of weak intermediate or weak Kallenberg efficiency of | + | one speaks of weak intermediate or weak Kallenberg efficiency of $T$ with respect to $V$ and one uses the notation $e ^ { w } ( T , V )$. Otherwise, that is, if all sequences $\{ \alpha _ { n } \}$ satisfying (a1) are under consideration, one speaks of strong intermediate or strong Kallenberg efficiency of $T$ with respect to $V$, with notation $e ^ { s } ( T , V )$. Note that |
| − | + | \begin{equation*} e ^ { s } ( T , V ) = e \Rightarrow e ( T , V ) = e \Rightarrow e ^ { w } ( T , V ) = e. \end{equation*} | |
| − | So, the whole intermediate range of levels between the Pitman and Bahadur case is built up with three increasing ranges. For example, if an i-efficiency result can be proved only for | + | So, the whole intermediate range of levels between the Pitman and Bahadur case is built up with three increasing ranges. For example, if an i-efficiency result can be proved only for $\alpha _ { n} \rightarrow 0$ at a lower rate than powers of $n$, that is, $\operatorname { log } \alpha _ { n } = o ( \operatorname { log } n )$, one speaks of a weak i-efficiency result. The several types of i-efficiency correspond with the existence of several types of moderate and Cramér-type large deviation theorems. |
| − | To compute | + | To compute $e ( T , V )$ under the null hypothesis, one needs a moderate deviation result (see [[#References|[a7]]] and references therein for results of this type), since $\alpha _ { n }$ tends to $0$. Under the alternatives a kind of [[Law of large numbers|law of large numbers]] is involved. The precise computation is described in [[#References|[a11]]], Lemma 2.1; Corol. 2.2, where also many examples are presented. |
In many testing problems, likelihood-ratio tests (cf. also [[Likelihood-ratio test|Likelihood-ratio test]]) are asymptotically optimal (cf. also [[Asymptotic optimality|Asymptotic optimality]]) when comparison is made in a non-local way, cf. [[#References|[a1]]], [[#References|[a3]]], [[#References|[a10]]]. On the other hand, likelihood ratio tests usually are not asymptotically optimal with respect to criteria based on the local performance of tests. It turns out that in exponential families, likelihood ratio tests have strong i-efficiency greater than or equal to one with respect to every other test, thus being optimal according to the criterion of i-efficiency. | In many testing problems, likelihood-ratio tests (cf. also [[Likelihood-ratio test|Likelihood-ratio test]]) are asymptotically optimal (cf. also [[Asymptotic optimality|Asymptotic optimality]]) when comparison is made in a non-local way, cf. [[#References|[a1]]], [[#References|[a3]]], [[#References|[a10]]]. On the other hand, likelihood ratio tests usually are not asymptotically optimal with respect to criteria based on the local performance of tests. It turns out that in exponential families, likelihood ratio tests have strong i-efficiency greater than or equal to one with respect to every other test, thus being optimal according to the criterion of i-efficiency. | ||
| Line 59: | Line 67: | ||
Optimality, in the sense of weak i-efficiency, of certain goodness-of-fit tests (cf. also [[Goodness-of-fit test|Goodness-of-fit test]]) in the case of censored data is shown in [[#References|[a15]]], while i-efficiency of decomposable statistics in a multinomial scheme is analyzed in [[#References|[a9]]]. For a generalization of the concept see [[#References|[a8]]], where it is shown that data-driven Neyman tests are asymptotically optimal. | Optimality, in the sense of weak i-efficiency, of certain goodness-of-fit tests (cf. also [[Goodness-of-fit test|Goodness-of-fit test]]) in the case of censored data is shown in [[#References|[a15]]], while i-efficiency of decomposable statistics in a multinomial scheme is analyzed in [[#References|[a9]]]. For a generalization of the concept see [[#References|[a8]]], where it is shown that data-driven Neyman tests are asymptotically optimal. | ||
| − | Application of an intermediate approach in estimation theory can be found in [[#References|[a12]]]. This is based on the probability that a [[Statistical estimator|statistical estimator]] deviates by more than | + | Application of an intermediate approach in estimation theory can be found in [[#References|[a12]]]. This is based on the probability that a [[Statistical estimator|statistical estimator]] deviates by more than $\epsilon _ { n }$ from its target $\theta$, for instance $P _ { \theta } ( | \overline{X} - \theta | > \epsilon _ { n } )$ for the estimator $\overline{X}$. The intermediate range concerns $\epsilon _ { n } \rightarrow 0$ and $n ^ { 1 / 2 } \epsilon _ { n } \rightarrow \infty$. Under certain regularity conditions, there is an asymptotic lower bound for $P _ { \theta } ( \| T _ { N } - \theta \| > \epsilon _ { N } )$, similar to the (Fisher) information bound in the local theory. An estimator is called optimal in the intermediate sense if it attains this lower bound. |
====References==== | ====References==== | ||
| − | <table>< | + | <table><tr><td valign="top">[a1]</td> <td valign="top"> R.R. Bahadur, "An optimal property of the likelihood ratio statistic" , ''Proc. 5th Berkeley Symp. Math. Stat. Probab.'' , '''1''' , Univ. California Press (1965) pp. 13–26</td></tr><tr><td valign="top">[a2]</td> <td valign="top"> A.A. Borovkov, A.A. Mogulskii, "Large deviations and statistical invariance principle" ''Th. Probab. Appl.'' , '''37''' (1993) pp. 7–13</td></tr><tr><td valign="top">[a3]</td> <td valign="top"> L.D. Brown, "Non-local asymptotic optimality of appropriate likelihood ratio tests" ''Ann. Math. Stat.'' , '''42''' (1971) pp. 1206–1240</td></tr><tr><td valign="top">[a4]</td> <td valign="top"> H.S. Wieand, "A condition under which the Pitman and Bahadur approaches to efficiency coincide" ''Ann. Statist.'' , '''4''' (1976) pp. 1003–1011</td></tr><tr><td valign="top">[a5]</td> <td valign="top"> P. Groeneboom, "Large deviations and asymptotic efficiencies" , ''Math. Centre Tracts'' , '''118''' , Math. Centre Amsterdam (1980)</td></tr><tr><td valign="top">[a6]</td> <td valign="top"> W. Hoeffding, "Asymptotic optimal tests for multinomial distributions" ''Ann. Math. Stat.'' , '''36''' (1965) pp. 369–405</td></tr><tr><td valign="top">[a7]</td> <td valign="top"> T. Inglot, W.C.M. Kallenberg, T. Ledwina, "Strong moderate deviation theorems" ''Ann. of Probab.'' , '''20''' (1992) pp. 987–1003</td></tr><tr><td valign="top">[a8]</td> <td valign="top"> T. Inglot, T. Ledwina, "Asymptotic optimality of data-driven Neyman's tests for uniformity" ''Ann. Statist.'' , '''24''' (1996) pp. 1982–2019</td></tr><tr><td valign="top">[a9]</td> <td valign="top"> G.I. Ivchenko, Sh.A. Mirakhemedov, "Large deviations and intermediate efficiency of decomposable statistics in a multinomial scheme" ''Math. Methods Statist.'' , '''4''' (1995) pp. 294–311</td></tr><tr><td valign="top">[a10]</td> <td valign="top"> W.C.M. Kallenberg, "Bahadur deficiency of likelihood ratio tests in exponential families" ''J. Multivariate Anal.'' , '''11''' (1981) pp. 506–531</td></tr><tr><td valign="top">[a11]</td> <td valign="top"> W.C.M. Kallenberg, "Intermediate efficiency, theory and examples" ''Ann. Statist.'' , '''11''' (1983) pp. 170–182</td></tr><tr><td valign="top">[a12]</td> <td valign="top"> W.C.M. Kallenberg, "On moderate deviation theory in estimation" ''Ann. Statist.'' , '''11''' (1983) pp. 498–504</td></tr><tr><td valign="top">[a13]</td> <td valign="top"> W.C.M. Kallenberg, A.J. Koning, "On Wieand's theorem" ''Statist. Probab. Lett.'' , '''25''' (1995) pp. 121–132</td></tr><tr><td valign="top">[a14]</td> <td valign="top"> W.C.M. Kallenberg, T. Ledwina, "On local and nonlocal measures of efficiency" ''Ann. Statist.'' , '''15''' (1987) pp. 1401–1420</td></tr><tr><td valign="top">[a15]</td> <td valign="top"> A.J. Koning, "Approximation of stochastic integrals with applications to goodness-of-fit tests" ''Ann. Statist.'' , '''20''' (1992) pp. 428–454</td></tr><tr><td valign="top">[a16]</td> <td valign="top"> Ya.Yu. Nikitin, "Asymptotic efficiency of nonparametric tests" , Cambridge Univ. Press (1995)</td></tr><tr><td valign="top">[a17]</td> <td valign="top"> J. Oosterhoff, W.R. van Zwet, "A note on contiguity and Hellinger distance" J. Jurečkova (ed.) , ''Contributions to Statistics: J. Hájek Memorial Vol.'' , Acad. Prague (1979) pp. 157–166</td></tr><tr><td valign="top">[a18]</td> <td valign="top"> H. Rubin, J. Sethuraman, "Bayes risk efficiency" ''Sankhyā Ser. A'' , '''27''' (1965) pp. 347–356</td></tr></table> |
Latest revision as of 16:10, 11 February 2024
Kallenberg efficiency
A concept used to compare the performance of statistical tests (cf. also Statistical hypotheses, verification of). Write $N ( \alpha , \beta , \theta )$ for the sample size required to attain with a level-$\alpha$ test a prescribed power $\beta$ at an alternative $\theta$. If one has two tests with corresponding numbers $N _ { 1 }$ and $N_{2}$, respectively, the ratio $N _ { 2 } / N _ { 1 }$ is called the relative efficiency of test $1$ with respect to test $2$. If the relative efficiency equals $3$, test $2$ needs $3$ times as much observations to perform equally well as test $1$ and hence test $1$ is $3$ times as efficient as test $2$ (cf. also Efficient test).
In general, the relative efficiency is hard to compute and, if it can be computed, hard to evaluate, as it depends on three arguments: $\alpha$, $\beta$ and $\theta$. (Note that $\theta$ is not restricted to be a Euclidean parameter; it can also be an abstract parameter, as for instance the distribution function.) Therefore, an asymptotic approach, where $N$ tends to infinity, is welcome to simplify both the computation and interpretation, thus hoping that the limit gives a sufficiently good approximation of the far more complicated finite-sample case.
When sending $N$ to infinity, two guiding principles are:
a) to "decrease the significance probability as N increases" , i.e. to send $\alpha$ to $0$; or
b) to "move the alternative hypothesis steadily closer to the null hypothesis" , i.e. to send $\theta$ to $H _ { 0 }$. Both principles are attractive: with more observations it seems reasonable to have a stronger requirement on the level and, on the other hand, for alternatives far away from the null hypothesis there is no need for statistical methods, since they are obviously different from $H _ { 0 }$.
In Pitman's asymptotic efficiency concept, method b) is used, while one deals with fixed levels, thus ignoring principle a). In Bahadur's asymptotic efficiency concept, method a) is actually used, while one considers fixed alternatives, thereby ignoring principle b). (Cf. also Bahadur efficiency; Efficiency, asymptotic.) Intermediate or Kallenberg efficiency applies both attractive principles simultaneously.
As a consequence of Bahadur's approach, in typical cases the level of significance $\alpha _ { N }$ required to attain a fixed power $\beta$ at a fixed alternative $\theta$ tends to zero at an exponential rate as the number of observations $N$ tends to infinity. There remains a whole range of sequences of levels "intermediate" between these two extremes of very fast convergence to zero of $\alpha _ { N }$ and the fixed $\alpha$ in the case of Pitman efficiency. The efficiency concept introduced by W.C.M. Kallenberg [a11] deals with this intermediate range and is therefore called intermediate efficiency, or, for short, i-efficiency.
A related approach is applied by P. Groeneboom [a5], Sect. 3.4, studying very precisely the behaviour of several tests for the multivariate linear hypothesis from an "intermediate" point of view. Other efficiency concepts with an "intermediate" flavour can be found in [a6], [a18] and [a2].
Instead of applying principles a) and b) simultaneously, in a lot of papers they are applied one after the other. For an excellent treatment in the case of non-parametric tests see [a16], where also many further references can be found (cf. also Non-parametric test). General results on limiting equivalence of local and non-local measures of efficiency are presented in [a4], [a14] and [a13].
The definition of intermediate or Kallenberg efficiency is as follows. Let $X _ { 1 } , X _ { 2 } , \dots$ be a sequence of independent, identically distributed random variables with distribution $P _ { \theta }$ for some $\theta$ in the parameter space $\Theta$. The hypothesis $H _ { 0 }$: $\theta \in \Theta _ { 0 }$ has to be tested against $H _ { 1 }$: $\theta \in \Theta _ { 1 } \subset \Theta - \Theta _ { 0 }$, where $\Theta _ { 0 }$ and $\Theta _ { 1 }$ are given subsets of $\Theta$. For a family of tests $\{ T ( n , \alpha ) : n \in \mathbf{N} , 0 < \alpha < 1 \}$, denote the power at $\theta$ by $\beta ( n , \alpha , \theta ; T )$, where $n$ is the available number of observations and $\alpha$ is the level of the test (cf. also Significance level). Suppose one has two families of tests, $\{ T ( n , \alpha ) \}$ and $\{ V ( n , \alpha ) \}$. Let $\{ \alpha _ { n } \}$ be a sequence of levels with
\begin{equation} \tag{a1} \operatorname { lim } _ { n \rightarrow \infty } \alpha _ { n } = 0 = \operatorname { lim } _ { n \rightarrow \infty } n ^ { - 1 } \operatorname { log } \alpha _ { n }, \end{equation}
thus ensuring that $\alpha _ { n }$ tends to $0$, but not exponentially fast. Let $\{ \theta _ { n } \}$ be a sequence of alternatives tending to the null hypothesis, in the sense that
\begin{equation} \tag{a2} \operatorname { lim } _ { n \rightarrow \infty } H ( \theta _ { n } , \Theta _ { 0 } ) = 0 , \operatorname { lim } _ { n \rightarrow \infty } n H ^ { 2 } ( \theta _ { n } , \Theta _ { 0 } ) = \infty , \end{equation}
and
\begin{equation} \tag{a3} 0 < \operatorname { liminf } _ { n \rightarrow \infty } \beta ( n , \alpha , \theta ; T ) \leq \operatorname { limsup } _ { n \rightarrow \infty } \beta ( n , \alpha , \theta ; T ) < 1. \end{equation}
Here, $H ( \theta , \Theta _ { 0 } ) = \operatorname { inf } \{ H ( \theta , \theta _ { 0 } ) : \theta _ { 0 } \in \Theta _ { 0 } \}$ and $H ( \theta , \theta _ { 0 } )$ denotes the Hellinger distance between the probability measures $P _ { \theta }$ and $P _ { \theta _ { 0 } }$. This ensures that the alternatives tend to $H _ { 0 }$, but in a slower way than contiguous alternatives, cf. [a17]. Typically, for Euclidean parameters, $H ( \theta , \theta _ { 0 } ) \sim c \| \theta - \theta _ { 0 } \| ^ { 2 }$ as $\theta \rightarrow \theta _ { 0 }$ and hence in such cases formula (a3) concerns convergence of $\theta _ { n }$ to $\Theta _ { 0 }$ at a rate slower than $n ^ { - 1 / 2 }$. (The latter is the usual rate for contiguous alternatives.)
Define $m ( n ; T , V )$ as the smallest number of observations needed for $V$ to perform as well as $T$ in the sense that $\beta ( m + k , \alpha _ { n } , \theta _ { n } ; V )$, the power at $\theta _ { n }$ of the level-$\alpha _ { n }$ test of $V$ based on $m + k$ observations, is, for all 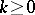 , at least as large as $\beta ( m , \alpha _ { n } , \theta _ { n } ; T )$, the power at $\theta _ { n }$ of the level-$\alpha _ { n }$ test of $T$ based on $n$ observations. If the sequence of levels $\{ \alpha _ { n } \}$ satisfies next to (a1) also
, at least as large as $\beta ( m , \alpha _ { n } , \theta _ { n } ; T )$, the power at $\theta _ { n }$ of the level-$\alpha _ { n }$ test of $T$ based on $n$ observations. If the sequence of levels $\{ \alpha _ { n } \}$ satisfies next to (a1) also
\begin{equation} \tag{a4} \operatorname { log } \alpha _ { n } = o ( n ^ { 1 / 3 } ) \text { as } n \rightarrow \infty \end{equation}
and if
\begin{equation*} e ( T , V ) = \operatorname { lim } _ { n \rightarrow \infty } \frac { m ( n ; T , V ) } { n } \end{equation*}
exists and does not depend on the special sequences $\{ \theta _ { n } \}$, $\{ \alpha _ { n } \}$ under consideration, one says that the intermediate or Kallenberg efficiency of $T$ with respect to $V$ equals $e ( T , V )$. If (a4) is replaced by
\begin{equation*} \operatorname { log } \alpha _ { n } = o ( \operatorname { log } n ) \text { as } n \rightarrow \infty \end{equation*}
one speaks of weak intermediate or weak Kallenberg efficiency of $T$ with respect to $V$ and one uses the notation $e ^ { w } ( T , V )$. Otherwise, that is, if all sequences $\{ \alpha _ { n } \}$ satisfying (a1) are under consideration, one speaks of strong intermediate or strong Kallenberg efficiency of $T$ with respect to $V$, with notation $e ^ { s } ( T , V )$. Note that
\begin{equation*} e ^ { s } ( T , V ) = e \Rightarrow e ( T , V ) = e \Rightarrow e ^ { w } ( T , V ) = e. \end{equation*}
So, the whole intermediate range of levels between the Pitman and Bahadur case is built up with three increasing ranges. For example, if an i-efficiency result can be proved only for $\alpha _ { n} \rightarrow 0$ at a lower rate than powers of $n$, that is, $\operatorname { log } \alpha _ { n } = o ( \operatorname { log } n )$, one speaks of a weak i-efficiency result. The several types of i-efficiency correspond with the existence of several types of moderate and Cramér-type large deviation theorems.
To compute $e ( T , V )$ under the null hypothesis, one needs a moderate deviation result (see [a7] and references therein for results of this type), since $\alpha _ { n }$ tends to $0$. Under the alternatives a kind of law of large numbers is involved. The precise computation is described in [a11], Lemma 2.1; Corol. 2.2, where also many examples are presented.
In many testing problems, likelihood-ratio tests (cf. also Likelihood-ratio test) are asymptotically optimal (cf. also Asymptotic optimality) when comparison is made in a non-local way, cf. [a1], [a3], [a10]. On the other hand, likelihood ratio tests usually are not asymptotically optimal with respect to criteria based on the local performance of tests. It turns out that in exponential families, likelihood ratio tests have strong i-efficiency greater than or equal to one with respect to every other test, thus being optimal according to the criterion of i-efficiency.
Locally most powerful tests are often Pitman efficient. On the other hand, locally most powerful tests are far from optimal from a non-local point of view. It turns out that in curved exponential families locally most powerful tests have strong i-efficiency greater than or equal to one with respect to every other test, thus being optimal according to the criterion of i-efficiency.
Optimality, in the sense of weak i-efficiency, of certain goodness-of-fit tests (cf. also Goodness-of-fit test) in the case of censored data is shown in [a15], while i-efficiency of decomposable statistics in a multinomial scheme is analyzed in [a9]. For a generalization of the concept see [a8], where it is shown that data-driven Neyman tests are asymptotically optimal.
Application of an intermediate approach in estimation theory can be found in [a12]. This is based on the probability that a statistical estimator deviates by more than $\epsilon _ { n }$ from its target $\theta$, for instance $P _ { \theta } ( | \overline{X} - \theta | > \epsilon _ { n } )$ for the estimator $\overline{X}$. The intermediate range concerns $\epsilon _ { n } \rightarrow 0$ and $n ^ { 1 / 2 } \epsilon _ { n } \rightarrow \infty$. Under certain regularity conditions, there is an asymptotic lower bound for $P _ { \theta } ( \| T _ { N } - \theta \| > \epsilon _ { N } )$, similar to the (Fisher) information bound in the local theory. An estimator is called optimal in the intermediate sense if it attains this lower bound.
References
| [a1] | R.R. Bahadur, "An optimal property of the likelihood ratio statistic" , Proc. 5th Berkeley Symp. Math. Stat. Probab. , 1 , Univ. California Press (1965) pp. 13–26 |
| [a2] | A.A. Borovkov, A.A. Mogulskii, "Large deviations and statistical invariance principle" Th. Probab. Appl. , 37 (1993) pp. 7–13 |
| [a3] | L.D. Brown, "Non-local asymptotic optimality of appropriate likelihood ratio tests" Ann. Math. Stat. , 42 (1971) pp. 1206–1240 |
| [a4] | H.S. Wieand, "A condition under which the Pitman and Bahadur approaches to efficiency coincide" Ann. Statist. , 4 (1976) pp. 1003–1011 |
| [a5] | P. Groeneboom, "Large deviations and asymptotic efficiencies" , Math. Centre Tracts , 118 , Math. Centre Amsterdam (1980) |
| [a6] | W. Hoeffding, "Asymptotic optimal tests for multinomial distributions" Ann. Math. Stat. , 36 (1965) pp. 369–405 |
| [a7] | T. Inglot, W.C.M. Kallenberg, T. Ledwina, "Strong moderate deviation theorems" Ann. of Probab. , 20 (1992) pp. 987–1003 |
| [a8] | T. Inglot, T. Ledwina, "Asymptotic optimality of data-driven Neyman's tests for uniformity" Ann. Statist. , 24 (1996) pp. 1982–2019 |
| [a9] | G.I. Ivchenko, Sh.A. Mirakhemedov, "Large deviations and intermediate efficiency of decomposable statistics in a multinomial scheme" Math. Methods Statist. , 4 (1995) pp. 294–311 |
| [a10] | W.C.M. Kallenberg, "Bahadur deficiency of likelihood ratio tests in exponential families" J. Multivariate Anal. , 11 (1981) pp. 506–531 |
| [a11] | W.C.M. Kallenberg, "Intermediate efficiency, theory and examples" Ann. Statist. , 11 (1983) pp. 170–182 |
| [a12] | W.C.M. Kallenberg, "On moderate deviation theory in estimation" Ann. Statist. , 11 (1983) pp. 498–504 |
| [a13] | W.C.M. Kallenberg, A.J. Koning, "On Wieand's theorem" Statist. Probab. Lett. , 25 (1995) pp. 121–132 |
| [a14] | W.C.M. Kallenberg, T. Ledwina, "On local and nonlocal measures of efficiency" Ann. Statist. , 15 (1987) pp. 1401–1420 |
| [a15] | A.J. Koning, "Approximation of stochastic integrals with applications to goodness-of-fit tests" Ann. Statist. , 20 (1992) pp. 428–454 |
| [a16] | Ya.Yu. Nikitin, "Asymptotic efficiency of nonparametric tests" , Cambridge Univ. Press (1995) |
| [a17] | J. Oosterhoff, W.R. van Zwet, "A note on contiguity and Hellinger distance" J. Jurečkova (ed.) , Contributions to Statistics: J. Hájek Memorial Vol. , Acad. Prague (1979) pp. 157–166 |
| [a18] | H. Rubin, J. Sethuraman, "Bayes risk efficiency" Sankhyā Ser. A , 27 (1965) pp. 347–356 |
Intermediate efficiency. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Intermediate_efficiency&oldid=18699