Zipf law
In 1949 G.K. Zipf published [a25]. A large, if not the main, part of it was devoted to the principles of human use of a language and the following was the main thesis of the author [a25], pp. 20–21: "From the viewpoint of the speaker, there would doubtless exist an important latent economy in a vocabulary that consisted exclusively of one single word — a single word that would mean whatever the speaker wanted it to mean. Thus, if there were 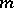 different meanings to be verbalized, this word would have
different meanings to be verbalized, this word would have 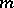 different meanings. [
different meanings. [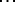 ] But from the viewpoint of the auditor, a single word vocabulary would represent the acme of verbal labour, since he would be faced by the impossible task of determining the particular meaning to which the single word in given situation might refer. Indeed, from the viewpoint of the auditor [
] But from the viewpoint of the auditor, a single word vocabulary would represent the acme of verbal labour, since he would be faced by the impossible task of determining the particular meaning to which the single word in given situation might refer. Indeed, from the viewpoint of the auditor [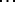 ] the important internal economy of speech would be found rather in vocabulary of such size that [
] the important internal economy of speech would be found rather in vocabulary of such size that [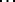 ] if there were
] if there were 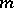 different meanings, there would be
different meanings, there would be 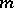 different words, with one meaning per word.
different words, with one meaning per word.
Thus, if there are an 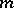 number of different distinctive meanings to be verbalized, there will be 1) a speaker's economy in possessing a vocabulary of one word which will refer to all the distinctive meanings; and there will also be 2) an opposing auditor's economy in possessing a vocabulary of
number of different distinctive meanings to be verbalized, there will be 1) a speaker's economy in possessing a vocabulary of one word which will refer to all the distinctive meanings; and there will also be 2) an opposing auditor's economy in possessing a vocabulary of  different words with one distinctive meaning for each word. Obviously the two opposing economies are in extreme conflict.
different words with one distinctive meaning for each word. Obviously the two opposing economies are in extreme conflict.
In the language of these two [economies or forces] we may say that the vocabulary of a given stream of speech is constantly subject of the opposing Forces of Unification and Diversification which will determine both the number  of actual words in the vocabulary, and also the meaning of those words.
of actual words in the vocabulary, and also the meaning of those words.
"
As far as this was the main thesis, the main data and the main empirical fact discussed thoroughly in the book is: "James Joyce's novel Ulysses, with its  running words, represents a sizable sample of running speech that may fairly be said to have served successfully in the communication of ideas. An index to the number of different words therein, together with the actual frequencies of their respective occurrences, has already been made with exemplary methods by Dr. Miles L. Hanley and associates ([a27]) [
running words, represents a sizable sample of running speech that may fairly be said to have served successfully in the communication of ideas. An index to the number of different words therein, together with the actual frequencies of their respective occurrences, has already been made with exemplary methods by Dr. Miles L. Hanley and associates ([a27]) [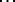 ].
].
To the above published index has been added an appendix from the careful hands of Dr. M. Joos, in which is set forth all the qualitative information that is necessary for our present purposes. For Dr. Joos not only tells us that there are  different words in the
different words in the 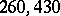 running words; [
running words; [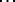 ] and tells us the actual frequency,
] and tells us the actual frequency,  , with which the different ranks,
, with which the different ranks,  , occur.
, occur.
It is evident that the relationship between the various ranks,  , of these words and their respective frequencies,
, of these words and their respective frequencies,  , is potentially quite instructive about the entire matter of vocabulary balance, not only because it involves the frequencies with which the different words occur but also because the terminal rank of the list tells us the number of different words in the sample. And we remember that both the frequencies of occurrence and the number of different words will be important factors in the counterbalancing of the Forces of Unification and Diversification in the hypothetical vocabulary balance of any sample of speech.
, is potentially quite instructive about the entire matter of vocabulary balance, not only because it involves the frequencies with which the different words occur but also because the terminal rank of the list tells us the number of different words in the sample. And we remember that both the frequencies of occurrence and the number of different words will be important factors in the counterbalancing of the Forces of Unification and Diversification in the hypothetical vocabulary balance of any sample of speech.
"
Now, let  be the frequencies of
be the frequencies of  ,
, 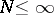 , different disjoint events in a sample of size
, different disjoint events in a sample of size  , like occurrences of different words in a text of
, like occurrences of different words in a text of  running words, and let
running words, and let  be an "empirical vocabulary" , that is, the number of all different events in the sample. Furthermore, let
be an "empirical vocabulary" , that is, the number of all different events in the sample. Furthermore, let  be the order statistic based on the frequencies and
be the order statistic based on the frequencies and 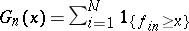 . Clearly,
. Clearly,  is the number of events that occurred in the sample exactly
is the number of events that occurred in the sample exactly  times and
times and  . Consider the statement that
. Consider the statement that
 | (a1) |
in some sense [a25], II.A, p.24. There is a bit of a problem with such statement for high values of the rank 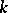 . Indeed, though in general
. Indeed, though in general  for
for 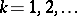 , typically
, typically  and one can replace (a1) by
and one can replace (a1) by
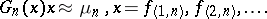 | (a2) |
For 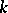 close to
close to  there will be plenty of frequencies of the same value which must have different ranks, and therefore the meaning of (a1) becomes obscure. However, one can use (a2) for all values of
there will be plenty of frequencies of the same value which must have different ranks, and therefore the meaning of (a1) becomes obscure. However, one can use (a2) for all values of 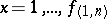 . In the form
. In the form
 | (a3) |
it becomes especially vivid, for it says that even for very large  (of many thousands) half of the empirical vocabulary should come from events which occurred in the sample only once,
(of many thousands) half of the empirical vocabulary should come from events which occurred in the sample only once,  . The events that occurred only twice,
. The events that occurred only twice, 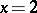 , should constitute
, should constitute  of
of 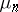 , and the events that occurred not more than
, and the events that occurred not more than  times constitute
times constitute  -th of empirical vocabulary. So, somewhat counterintuitive even in very big samples, rare events should be presented in plenty and should constitute almost total of all different events that occurred. Any of statements (a1), (a2) or (a3) are called Zipf's law.
-th of empirical vocabulary. So, somewhat counterintuitive even in very big samples, rare events should be presented in plenty and should constitute almost total of all different events that occurred. Any of statements (a1), (a2) or (a3) are called Zipf's law.
Assume for simplicity that 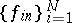 are drawn from a multinomial distribution with probabilities
are drawn from a multinomial distribution with probabilities  which form an array with respect to
which form an array with respect to  . The asymptotic behaviour of the statistics
. The asymptotic behaviour of the statistics 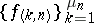 ,
, 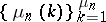 ,
,  , which all are symmetric, is governed by the distribution function of the probabilities
, which all are symmetric, is governed by the distribution function of the probabilities  :
:
 |
Namely, if
 |
then
 | (a4) |
while if
 |
where
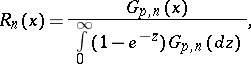 |
then
 | (a5) |
(see, e.g., [a7]). Therefore the limiting expression 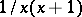 is by no means unique and there are as many possible limiting expressions for the spectral statistics
is by no means unique and there are as many possible limiting expressions for the spectral statistics  as there are measures with
as there are measures with  . The right-hand side of (a5) gives Zipf's law (a3) if and only if
. The right-hand side of (a5) gives Zipf's law (a3) if and only if
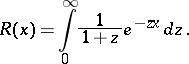 |
The concepts of C. Shannon in information theory were relatively new when B. Mandelbrot [a11] used them to make Zipf's reasoning on a compromise between speaker's and auditor's economies rigorous and derive (a3) formally. Therefore the statement
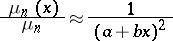 | (a6) |
is frequently called the Zipf–Mandelbrot law. Among earlier work on distributions of the sort,
 | (a7) |
is, of course, the famous Pareto distribution of population over income [a17].
In lexical data, both Mandelbrot [a12] and Zipf [a25] note that the so-called Zipf's law was first observed by J.B. Estoup [a2]. (Note that Zipf's role was not so much the observation itself, which, by the way, he never claimed to be the first to make, as the serious attempt to explain the mechanism behind it.)
G.U. Yule [a24], in his analysis of data of J.G. Willis [a22] on problems of biological taxonomy, introduced the following expression for 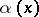 :
:
 | (a8) |
depending on some parameter 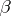 .
.
H.A. Simon [a19] proposed and studied a certain Markov model for 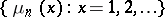 as a process in
as a process in  and obtained (a8) and a somewhat more general form of it as a limiting expression for
and obtained (a8) and a somewhat more general form of it as a limiting expression for  . His core assumption was most natural: as there are
. His core assumption was most natural: as there are 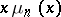 words used
words used  times in the first
times in the first  draws, the probability that a word from this group will be used on the
draws, the probability that a word from this group will be used on the 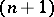 st draw is proportional to
st draw is proportional to  . In other words,
. In other words,
 | (a9) |
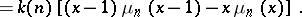 |
His other assumption that a new (unused) word would occur on each trial with the same constant probability 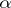 was, perhaps, a little bit controversial. Indeed, it implies that the empirical vocabulary
was, perhaps, a little bit controversial. Indeed, it implies that the empirical vocabulary  increases with the same rate as
increases with the same rate as  , while for Zipf's law in its strict sense of (a3) (or for
, while for Zipf's law in its strict sense of (a3) (or for 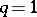 in (a7)) one obviously has
in (a7)) one obviously has
 |
This and some other concerns of analytic nature (cf. the criticism in [a12], [a13] and the replies [a20], [a21]) led Simon to the third assumption: "[a word] may be dropped with the same average rate" . This is described in very clear form in [a20]: "We consider a sequence of 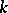 words. We add words to the end of the sequence, and drop words from the sequence at the same average rate, so that the length of the sequence remains
words. We add words to the end of the sequence, and drop words from the sequence at the same average rate, so that the length of the sequence remains  . For the birth process we assume: the probability that the next word added is one that now occurs
. For the birth process we assume: the probability that the next word added is one that now occurs 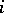 times is proportional to
times is proportional to 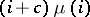 . The probability that the next word is a new word is
. The probability that the next word is a new word is 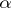 , a constant. For the death process we assume: the probability that the next word dropped is one that now occurs
, a constant. For the death process we assume: the probability that the next word dropped is one that now occurs 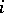 times is proportional to
times is proportional to 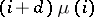 . The terms
. The terms  and
and 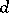 are constant parameters. The steady state relation is:
are constant parameters. The steady state relation is:
 |
 |
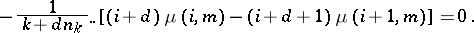 |
A solution to this equation, independent of 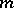 , is:
, is:
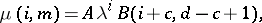 | (a10) |
where
 |
and 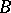 is the beta function.
is the beta function.
"
See [a12] for an analytically beneficial replacement of the difference equations (a9) (for expectations 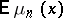 ) by certain partial differential equations. See also [a3] for the exact solution of these difference equations. Simon suggested to call (a8) the Yule distribution, but (a8) and (a10) are more appropriately and more commonly called the Yule–Simon distribution.
) by certain partial differential equations. See also [a3] for the exact solution of these difference equations. Simon suggested to call (a8) the Yule distribution, but (a8) and (a10) are more appropriately and more commonly called the Yule–Simon distribution.
Approximately at the same time, R.H. MacArthur [a10] published a note on a model for the relative abundancy of species. His model of "non-overlapping niches" was very simple: "The environment is compared with a stick of unit length on which 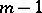 points are thrown at random. The stick is broken at these points and lengths of the
points are thrown at random. The stick is broken at these points and lengths of the 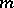 resulting segments are proportional to the abundance of the
resulting segments are proportional to the abundance of the  species. [
species. [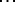 ] The expected length of
] The expected length of  -th shortest interval is given by
-th shortest interval is given by
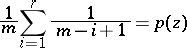 | (a11) |
so that the expected abundance of the  -th rarest species among
-th rarest species among  species and
species and  individuals is
individuals is 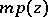 .
.
" It appears (see [a26]) that "bird censuses" from tropical forests and many temperate regions fit this almost perfectly.
The rate of  in
in  is, certainly, very different from
is, certainly, very different from  . Very interestingly, MacArthur suggests, then, to view divergence of a distribution from (a11) as an indication and a measure of heterogeneity of a population. His idea was to "use several sticks of very different size" to produce other curves.
. Very interestingly, MacArthur suggests, then, to view divergence of a distribution from (a11) as an indication and a measure of heterogeneity of a population. His idea was to "use several sticks of very different size" to produce other curves.
In a certain sense, this was actualized in a very elegant model of B. Hill and M. Woodroofe (see [a4], [a5], [a23]).
According to Hill, if 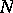 individuals are to be distributed to
individuals are to be distributed to  non-empty genera in accordance with Bose–Einstein statistics, i.e. all allocations are equi-probable, each with probability
non-empty genera in accordance with Bose–Einstein statistics, i.e. all allocations are equi-probable, each with probability
 |
and if 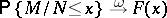 ,
,  ,
,  , then for the number of genera with exactly
, then for the number of genera with exactly  species one has
species one has
 | (a12) |
where the random variable  has distribution
has distribution  . Note that if
. Note that if  has a uniform distribution, then, as a consequence of (a12),
has a uniform distribution, then, as a consequence of (a12),
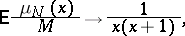 |
which is exactly (a3). By considering a triangular array of independent (or exchangeable, as the authors have it) families of genera 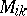 with allocations of
with allocations of  species in each family
species in each family 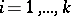 (the different "sticks" of MacArthur [a10]!), Hill and Woodroofe have shown that for combined statistics
(the different "sticks" of MacArthur [a10]!), Hill and Woodroofe have shown that for combined statistics 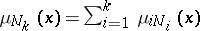 and
and  one has
one has
 | (a13) |
A. Rouault [a18] considered a certain Markov process as a model for formation of a text word by word and obtained the following expression for the limit of spectral statistics:
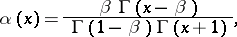 | (a14) |
depending on a parameter  .
.
This Karlin–Rouault law appeared in a very different context in [a8]: Let the unit interval be divided into two in the ratio  . Let each of these two be again subdivided in the same ratio, etc. At step
. Let each of these two be again subdivided in the same ratio, etc. At step  one obtains probabilities
one obtains probabilities 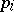 ,
, 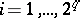 , of the form
, of the form 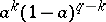 for some
for some 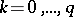 . One can think of filling a questionnaire with "yes-no" questions at random with probability
. One can think of filling a questionnaire with "yes-no" questions at random with probability  for one of the answers in each question. Then the
for one of the answers in each question. Then the  are the probabilities of each particular answer to the questions or "opinion" . It was proved that if
are the probabilities of each particular answer to the questions or "opinion" . It was proved that if  , then
, then
 | (a15) |
and that
 | (a16) |
with  and
and  and with
and with  being a counting measure (concentrated on integers). With
being a counting measure (concentrated on integers). With  replaced by the Lebesgue measure
replaced by the Lebesgue measure 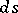 and using the change of variables
and using the change of variables 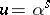 , the right-hand side of (a16) will coincide with (a14).
, the right-hand side of (a16) will coincide with (a14).
A possible heuristic interpretation of (a15) is that if  , then saying "as many men as many minds" is incorrect — though the number of "minds" is infinitely large it is still asymptotically smaller than the number of "men" .
, then saying "as many men as many minds" is incorrect — though the number of "minds" is infinitely large it is still asymptotically smaller than the number of "men" .
One of the present time (2000) characteristics of the study of Zipf's law is the increase of interest in the more general concept of "distributions with a large number of rare events" (LNRE distributions), which was introduced and first systematically studied in [a6] (partly reproduced in [a7]).
For a systematic application of LNRE distributions to the analysis of texts, see [a1]. On the other hand, studies on specific laws continue. In a series of papers, Yu. Orlov (see, e.g., [a14], [a15], [a16]) promoted the hypothesis that the presence of Zipf's law is the characteristic property of a complete, finished and well-balanced text. Though the hypothesis looks beautiful and attractive, for some readers the evidence may look thin. The problem of non-parametric estimation of the functions  and
and 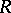 through the expressions (a3) and (a5) provides another most natural example of an "inverse problem" , studied recently by C. Klaassen and R. Mnatsakanov [a9].
through the expressions (a3) and (a5) provides another most natural example of an "inverse problem" , studied recently by C. Klaassen and R. Mnatsakanov [a9].
In conclusion, the following quote from [a12], whose views I share, is given: "The form of Zipf's law [see (a7)] is so striking and also so very different from any classical distribution of statistics that it is quite widely felt that it "should" have a basically simple reason, possibly as "weak" and general as the reasons which account for the role of Gaussian distribution. But, in fact, these laws turn out to be quite resistant to such an analysis. Thus, irrespective of any claim as to their practical importance, the "explanation" of their role has long been one of the best defined and most conspicuous challenges to those interested in statistical laws of nature.
"
References
| [a1] | R.H. Baayen, "Word frequency distribution" , Kluwer Acad. Publ. (2000) |
| [a2] | J.B. Estoup, "Gammes stenographiques" , Paris (1916) (Edition: Fourth) |
| [a3] | R. Gunther, B. Schapiro, P. Wagner, "Physical complexity and Zipf's law" Internat. J. Theoret. Phys. , 31 : 3 (1999) pp. 525–543 |
| [a4] | B.M. Hill, "Zipf's law and prior distributions for the composition of a population" J. Amer. Statist. Assoc. , 65 (1970) pp. 1220–1232 |
| [a5] | B.M. Hill, M. Woodroofe, "Stronger forms of Zipf's law" J. Amer. Statist. Assoc. , 70 (1975) pp. 212–219 |
| [a6] | E.V. Khmaladze, "The statistical analysis of large number of rare events" Techn. Rept. Dept. Math. Statist. CWI, Amsterdam , MS-R8804 (1987) |
| [a7] | E.V. Khmaladze, R.J. Chitashvili, "Statistical analysis of large number of rate events and related problems" Trans. Tbilisi Math. Inst. , 91 (1989) pp. 196–245 |
| [a8] | E.V. Khmaladze, Z.P. Tsigroshvili, "On polynomial distributions with large number of rare events" Math. Methods Statist. , 2 : 3 (1993) pp. 240–247 |
| [a9] | C.A.J. Klaassen, R.M. Mnatsakanov, "Consistent estimation of the structural distribution function" Scand. J. Statist. , 27 (2000) pp. 1–14 |
| [a10] | R.H. MacArthur, "On relative abundancy of bird species" Proc. Nat. Acad. Sci. USA , 43 (1957) pp. 293–295 |
| [a11] | B. Mandelbrot, "An information theory of the statistical structure of language" W.E. Jackson (ed.) , Communication Theory , Acad. Press (1953) pp. 503–512 |
| [a12] | B. Mandelbrot, "A note on a class of skew distribution functions: Analysis and critque of a paper by H.A. Simon" Inform. & Control , 2 (1959) pp. 90–99 |
| [a13] | B. Mandelbrot, "Final note on a class of skew distribution functions: Analysis and critique of a model due to H.A. Simon" Inform. & Control , 4 (1961) pp. 198–216; 300–304 |
| [a14] | Ju.K. Orlov, "Dynamik der Haufigkeitsstrukturen" H. Guiter (ed.) M.V. Arapov (ed.) , Studies on Zipf's law , Brockmeyer, Bochum (1983) pp. 116–153 |
| [a15] | Ju.K. Orlov, "Ein Model der Haufigskeitstruktur des Vokabulars" H. Guiter (ed.) M.V. Arapov (ed.) , Studies on Zipf's law , Brockmeyer, Bochum (1983) pp. 154–233 |
| [a16] | Ju.K. Orlov, R.Y. Chitashvili, "On the statistical interpretation of Zipf's law" Bull. Acad. Sci. Georgia , 109 (1983) pp. 505–508 |
| [a17] | V. Pareto, "Course d'economie politique" , Lausanne and Paris (1897) |
| [a18] | A. Rouault, "Loi de Zipf et sources markoviennes" Ann. Inst. H. Poincaré , 14 (1978) pp. 169–188 |
| [a19] | H.A. Simon, "On a class of skew distribution functions" Biometrika , 42 (1955) pp. 435–440 |
| [a20] | H.A. Simon, "Some further notes on a class of skew distribution functions" Inform. & Control , 3 (1960) pp. 80–88 |
| [a21] | H.A. Simon, "Reply to `final note' by Benoit Mandelbrot" Inform. & Control , 4 (1961) pp. 217–223 |
| [a22] | J.G. Willis, "Age and area" , Cambridge Univ. Press (1922) |
| [a23] | M. Woodroofe, B.M. Hill, "On Zipf's law" J. Appl. Probab. , 12 : 3 (1975) pp. 425–434 |
| [a24] | G.U. Yule, "A mathematical theory of evolution, based on the conclusions of Dr.J.C. Willis, F.R.S." Philos. Trans. Royal Soc. London Ser. B , 213 (1924) pp. 21–87 |
| [a25] | G.K. Zipf, "Human behaviour and the principles of least effort" , Addison-Wesley (1949) |
| [a26] | L.I. Davis, Aud. Field Notes , 9 (1955) pp. 425 |
| [a27] | L.M. Hanley, "Word index to James Joyce's Ulysses" , Madison, Wisc. (1937) (statistical tabulations by M. Joos) |
Zipf law. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Zipf_law&oldid=12733