Robust statistics
The branch of mathematical statistics concerned with the construction and investigation of statistical procedures (such as parameter estimators and tests) that still behave well when the usual assumptions are not satisfied. For instance, the observations may not follow the normal (Gaussian) distribution exactly, because in practice the data often contain outliers (aberrant values) which are caused by transcription errors, misplaced decimal points, exceptional phenomena, etc.
It has been known for many years that the classical procedures (such as the sample average) loose their optimality, and can in fact give arbitrarily bad results, when even a small percentage of the data are outlying. In such situations applied statisticians have turned to alternative methods (e.g. the sample median) which they knew to be less affected by possible outlying values. However, the intuitive notion of robustness was not formalized until the 1960's. The theoretical foundations of robust statistics have been developed in the three stages described below.
The first mathematical approach is due to P.J. Huber [a1], who found the solution 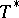 to a minimax variational problem:
to a minimax variational problem:
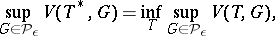 |
where 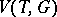 denotes the asymptotic variance of an estimator
denotes the asymptotic variance of an estimator  at a distribution
at a distribution 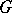 . The set
. The set  (for some
(for some 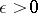 ) consists of all mixture distributions
) consists of all mixture distributions 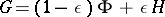 , where
, where 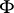 is the standard normal distribution and
is the standard normal distribution and 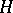 is arbitrary (e.g., the Cauchy distribution). In the framework of a univariate location parameter, the solution
is arbitrary (e.g., the Cauchy distribution). In the framework of a univariate location parameter, the solution 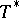 has come to be known as the Huber estimator. For a survey of this work see [a2].
has come to be known as the Huber estimator. For a survey of this work see [a2].
The second approach was based on the influence function [a3]
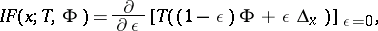 |
where 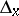 is the probability distribution which puts all its mass in the point
is the probability distribution which puts all its mass in the point  . The influence function describes the effect of a single outlier at
. The influence function describes the effect of a single outlier at  on (the asymptotic version of) the estimator
on (the asymptotic version of) the estimator 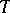 . In this approach one obtains optimally robust estimators and tests by maximizing the asymptotic efficiency subject to an upper bound on the supremum norm of the influence function. Unlike the minimax variance approach, it can also be applied to multivariate problems. The main results of this methodology are found in [a4].
. In this approach one obtains optimally robust estimators and tests by maximizing the asymptotic efficiency subject to an upper bound on the supremum norm of the influence function. Unlike the minimax variance approach, it can also be applied to multivariate problems. The main results of this methodology are found in [a4].
The third approach aims for a high breakdown point. The breakdown point of an estimator is the largest fraction of arbitrary outliers it can tolerate without becoming unbounded. This goes beyond the second approach, where only the effect of a single outlier was considered. In linear regression analysis, the first equivariant high-breakdown estimator was the least median of squares [a5], defined by
 |
where 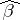 is the vector of regression coefficients and
is the vector of regression coefficients and 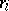 is the residual of the
is the residual of the 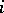 -th observation. High-breakdown estimators also exist for other multivariate situations. A survey of these methods is given in [a6], which also describes applications.
-th observation. High-breakdown estimators also exist for other multivariate situations. A survey of these methods is given in [a6], which also describes applications.
At present (1990's), research is focussed on the construction of estimators that have a high breakdown point as well as bounded influence function and good asymptotic efficiency. The more recently developed estimators make increasing use of computing resources.
References
| [a1] | P.J. Huber, "Robust estimation of a location parameter" Ann. Math. Stat. , 35 (1964) pp. 73–101 |
| [a2] | P.J. Huber, "Robust statistics" , Wiley (1981) |
| [a3] | F.R. Hampel, "The influence curve and its role in robust estimation" J. Amer. Statist. Assoc. , 69 (1974) pp. 383–393 |
| [a4] | F.R. Hampel, E.M. Ronchetti, P.J. Rousseeuw, W.A. Stahel, "Robust statistics. The approach based on influence functions" , Wiley (1986) |
| [a5] | P.J. Rousseeuw, "Least median of squares regression" J. Amer. Statist. Assoc. , 79 (1984) pp. 871–880 |
| [a6] | P.J. Rousseeuw, A.M. Leroy, "Robust regression and outlier detection" , Wiley (1987) |
Robust statistics. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Robust_statistics&oldid=17575