NP
One major goal of complexity theory is to obtain precise bounds on the number of operations performed by algorithms for solving a particular problem. This purpose splits into two directions: the design of specific algorithms leads to upper bounds on the computational complexity of a problem; the analysis of all permitted algorithms together with the structure of a problem can provide lower bounds (cf. also Algorithm; Algorithm, computational complexity of an).
If both bounds match, the ideal situation of an optimal algorithm is reached. However, in many situations such optimal bounds are not (yet) available. Consequently, one is tempted to give at least a classification of problems in terms of statements like: one problem is at least as hard to solve as another one. This leads to the notions of reducibility and completeness.
Consider a computational model for uniform algorithms over a set 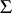 . Two prominent examples are
. Two prominent examples are
1) The Turing machine: here,  is a finite alphabet, typically
is a finite alphabet, typically  . Operations used are bit operations on strings over
. Operations used are bit operations on strings over 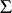 (see [a2]).
(see [a2]).
2) The real Turing or Blum–Shub–Smale machine (BSS model): here, 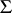 is the set of real numbers. Operations used are the arithmetic operations
is the set of real numbers. Operations used are the arithmetic operations 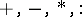 , together with a test-instruction "x≥ 0?" for an
, together with a test-instruction "x≥ 0?" for an 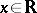 (see [a1]).
(see [a1]).
A decision problem is a subset 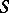 of the set
of the set 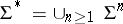 . An algorithm solves
. An algorithm solves 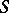 if it computes the characteristic function of
if it computes the characteristic function of  in
in 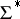 . In order to speak about complexity, a size measure for a problem instance
. In order to speak about complexity, a size measure for a problem instance 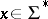 as well as a cost measure for algorithms must be introduced. In the above settings, the size of
as well as a cost measure for algorithms must be introduced. In the above settings, the size of  is
is 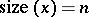 , whereas the cost or running time of a corresponding algorithm is the number of executed operations. (In particular, for computations over integers the Turing model uses a logarithmic size measure together with bit-costs whereas in the BSS model one exploits algebraic measures.)
, whereas the cost or running time of a corresponding algorithm is the number of executed operations. (In particular, for computations over integers the Turing model uses a logarithmic size measure together with bit-costs whereas in the BSS model one exploits algebraic measures.)
Next, complexity classes (of decision problems) can be defined by bounding the running time of an algorithm in the size of a problem instance. Of particular importance is the class  of problems solvable in polynomial time. A problem is in
of problems solvable in polynomial time. A problem is in 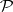 if it can be decided by an algorithm the running time of which is bounded by a polynomial function in the input size.
if it can be decided by an algorithm the running time of which is bounded by a polynomial function in the input size.
For example, the linear programming problem is in  over the integers in the Turing model (see [a4]). It is not yet (1998) known to belong to
over the integers in the Turing model (see [a4]). It is not yet (1998) known to belong to 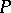 over the real numbers.
over the real numbers.
Problems in 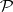 are considered to be efficiently solvable. However, for a large class of problems it can only be shown that there exist fast verification procedures instead of fast decision procedures. The latter is formalized by defining the class
are considered to be efficiently solvable. However, for a large class of problems it can only be shown that there exist fast verification procedures instead of fast decision procedures. The latter is formalized by defining the class 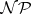 .
.
A decision problem 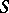 is in the class
is in the class 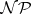 if there exists an algorithm
if there exists an algorithm 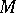 such that the following holds: As input
such that the following holds: As input 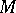 takes an element
takes an element 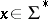 (the current problem-instance) together with an additional "guess"
(the current problem-instance) together with an additional "guess" 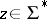 (representing a possible proof of "x S" ). If
(representing a possible proof of "x S" ). If 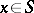 , there must exist a suitable guess
, there must exist a suitable guess  such that
such that 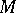 on input
on input  accepts in polynomial time with respect to
accepts in polynomial time with respect to 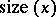 . If
. If 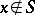 , no
, no  exists for which
exists for which 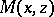 accepts.
accepts.
Such algorithms are called non-deterministic since there is no information available on how to obtain a correct  efficiently.
efficiently.
Note that  ; the question whether equality holds is the major open (1998) problem in complexity theory.
; the question whether equality holds is the major open (1998) problem in complexity theory.
Examples.
Turing model.
Given a graph 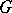 over
over  nodes, the
nodes, the  problem asks for the existence of a Hamiltonian circuit (cf. also Graph circuit). A fast verification procedure is given by guessing a permutation of
problem asks for the existence of a Hamiltonian circuit (cf. also Graph circuit). A fast verification procedure is given by guessing a permutation of 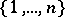 and checking whether it represents such a circuit of
and checking whether it represents such a circuit of 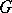 . Thus,
. Thus, 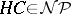 over
over  .
.
BSS-model.
Given a polynomial 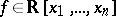 of degree
of degree  , the problem
, the problem 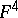 asks for the existence of a real zero for
asks for the existence of a real zero for 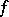 . A fast verification procedure is given by guessing a possible zero
. A fast verification procedure is given by guessing a possible zero  , plugging it into
, plugging it into  and checking whether
and checking whether 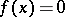 . Thus
. Thus  over
over 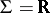 .
.
Remarks.
For the above examples (and for many more), no optimal complexity bounds are known. Nevertheless, among all other problems within the corresponding 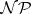 class they have a particular status. A decision problem
class they have a particular status. A decision problem 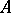 is called reducible in polynomial time to another problem
is called reducible in polynomial time to another problem 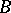 if there exists a polynomial-time algorithm
if there exists a polynomial-time algorithm  mapping
mapping  to
to 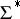 such that
such that 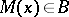 if and only if
if and only if  . Problem
. Problem 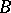 is called
is called 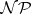 -hard if all problems in
-hard if all problems in 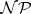 are reducible to
are reducible to 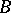 in polynomial time. It is called
in polynomial time. It is called 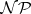 -complete if, in addition,
-complete if, in addition, 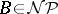 holds.
holds.
Examples.
Turing-model.
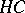 is
is 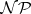 -complete over
-complete over  (cf. [a2]).
(cf. [a2]).
BSS-model.
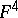 is
is 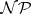 -complete over
-complete over  (cf. [a1]).
(cf. [a1]).
Remarks.
If any 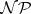 -hard or
-hard or  -complete problem would be solvable in polynomial time, then
-complete problem would be solvable in polynomial time, then  . This is the substantiation why
. This is the substantiation why  -complete problems are of particular interest in complexity theory.
-complete problems are of particular interest in complexity theory.
Knowing the completeness or hardness of a problem does not remove the necessity of solving it. There is a huge literature on that issue in connection with many complete problems. As starting point with respect to the above-mentioned problems in graph theory and polynomial system solving, see [a3], respectively [a1].
Finally, it should be noted that hardness and completeness notions can also be defined with respect to other resources, such as space or parallel computational devices (cf. [a2]).
References
| [a1] | L. Blum, F. Cucker, M. Shub, S. Smale, "Complexity and real computation" , Springer (1997) |
| [a2] | M.R. Garey, D.S. Johnson, "Computers and intractability" , Freeman (1979) |
| [a3] | M. Grötschel, L. Lovász, A. Schrijver, "Geometric algorithms and combinatorial optimization" , Springer (1988) |
| [a4] | L.G. Khachiyan, "A polynomial algorithm in linear programming" Soviet Math. Dokl. , 20 (1979) pp. 191–194 Dokl. Akad. Nauk SSSR , 244 (1979) pp. 1093–1096 |
NP. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=NP&oldid=15503