Multi-dimensional statistical analysis
multivariate statistical analysis
The branch of mathematical statistics devoted to mathematical methods for constructing optimal designs for the collection, systematization and processing of multivariate statistical data, directed towards clarifying the nature and the structure of the correlations between the components of the multivariate attribute in question, and intended for obtaining scientific and practical inferences. By a multivariate attribute is meant a 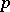 -dimensional vector
-dimensional vector 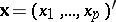 of components (laws, variables)
of components (laws, variables)  which may be quantitative, that is, measuring in some fixed scale the degree of manifestation of the studied property of an object, it may be ordering (or ordinal), that is, allowing the objects being analyzed to be ordered relative to the degree of manifestation in them of the studied property, and it may be classifying (or nominal), that is, allow the collection of objects being investigated, which does not lend itself to ordering, to be separated into homogeneous (relative to the analyzed property) classes. The results of measuring these components,
which may be quantitative, that is, measuring in some fixed scale the degree of manifestation of the studied property of an object, it may be ordering (or ordinal), that is, allowing the objects being analyzed to be ordered relative to the degree of manifestation in them of the studied property, and it may be classifying (or nominal), that is, allow the collection of objects being investigated, which does not lend itself to ordering, to be separated into homogeneous (relative to the analyzed property) classes. The results of measuring these components,
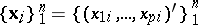 | (1) |
for each of  objects of a collection, forms a sequence of multivariate observations, or an initial ensemble of multivariate data, for conducting a multivariate statistical analysis. A significant part of multivariate statistical analysis involves the situation in which
objects of a collection, forms a sequence of multivariate observations, or an initial ensemble of multivariate data, for conducting a multivariate statistical analysis. A significant part of multivariate statistical analysis involves the situation in which  is interpreted as a multivariate random variable, and the corresponding sequence of observations (1) is a population sample. In this case the choice of a method for processing the initial statistical data and the analysis of their properties is carried out on the basis of assumptions regarding the nature of the multivariate (joint) law of the probability distribution
is interpreted as a multivariate random variable, and the corresponding sequence of observations (1) is a population sample. In this case the choice of a method for processing the initial statistical data and the analysis of their properties is carried out on the basis of assumptions regarding the nature of the multivariate (joint) law of the probability distribution 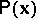 .
.
The content of multivariate statistical analysis can be conventionally divided into three basic subdivisions: the multivariate statistical analysis of multivariate distributions and their basic characteristics; the multivariate statistical analysis of the nature and structure of the correlations between the components of the multivariate attribute being investigated; and the multivariate statistical analysis of the geometric structure of the set of multi-dimensional observations being investigated.
Multivariate statistical analysis of multivariate distributions and their fundamental characteristics.
This branch covers only situations in which the observations (1) being processed have a probabilistic nature, that is, can be interpreted as a sample from a corresponding population. The basic problems of this branch are: the statistical estimation, for the multivariate distributions in question, of their fundamental numerical characteristics and parameters; the investigation of the properties of the statistical estimators used; and the investigation of the probability distributions of a number of statistics that are used to construct statistical tests for the verification of various hypotheses on the nature of the multi-dimensional data being analyzed. The fundamental results are related to the particular case when the attribute in question,  , is subject to a multivariate normal law
, is subject to a multivariate normal law 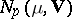 , with density function
, with density function 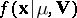 given by
given by
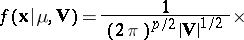 | (2) |
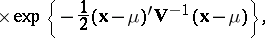 |
where 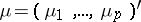 is the vector of mathematical expectations (cf. Mathematical expectation) of the components of
is the vector of mathematical expectations (cf. Mathematical expectation) of the components of  , that is,
, that is,  ,
, 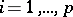 , and
, and 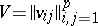 is the covariance matrix of
is the covariance matrix of  , that is,
, that is, 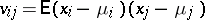 is the covariance of these components of
is the covariance of these components of  (the non-degenerate case
(the non-degenerate case 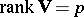 is considered; in case
is considered; in case 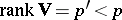 , all the results remain true, but in a subspace of a smaller dimension
, all the results remain true, but in a subspace of a smaller dimension 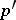 on which the probability distribution of
on which the probability distribution of  is concentrated).
is concentrated).
Thus, if (1) is a sequence of independent observations, forming a random sample from 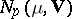 , then the maximum-likelihood estimators for the parameters
, then the maximum-likelihood estimators for the parameters 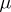 and
and 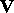 in (2) are, respectively, the statistics (see [1], [2])
in (2) are, respectively, the statistics (see [1], [2])
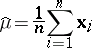 | (3) |
and
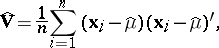 | (4) |
where the random vector  is subject to the
is subject to the 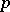 -dimensional normal law
-dimensional normal law 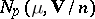 and is statistically independent of
and is statistically independent of  , and the joint distribution of the elements of the matrix
, and the joint distribution of the elements of the matrix 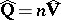 is described by the so-called Wishart distribution (see [4]) with density
is described by the so-called Wishart distribution (see [4]) with density
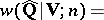 |
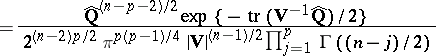 |
if 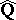 is positive definite, and 0 otherwise.
is positive definite, and 0 otherwise.
Within this scheme, the distribution and moments of sampling characteristics of multivariate random variables such as the coefficients of paired, partial and multiple correlations, the generalized variance (i.e., the statistic 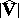 ) and the generalized Hotelling
) and the generalized Hotelling  -statistic (cf. Hotelling
-statistic (cf. Hotelling 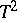 -distribution and [5]) have been investigated. In particular (see [1]), if the sample covariance matrix
-distribution and [5]) have been investigated. In particular (see [1]), if the sample covariance matrix 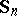 is defined as the estimator
is defined as the estimator 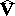 made "unbiased" , namely:
made "unbiased" , namely:
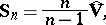 | (5) |
then the distribution of 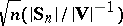 tends to
tends to 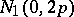 as
as 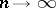 , and the random variables
, and the random variables
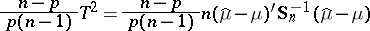 | (6) |
and
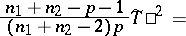 | (7) |
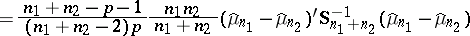 |
have the Fisher 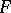 -distribution with degrees of freedom
-distribution with degrees of freedom 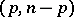 and
and  , respectively. In (7),
, respectively. In (7), 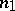 and
and 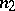 are the sizes of two independent samples of the form (1) taken from the same population
are the sizes of two independent samples of the form (1) taken from the same population 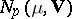 ,
, 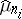 and
and 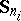 being estimators of the form (3) and (4)–(5), constructed with respect to the
being estimators of the form (3) and (4)–(5), constructed with respect to the 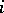 -th sample, and
-th sample, and
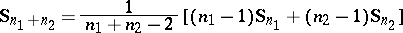 |
is the common sample covariance matrix constructed with respect to the estimators 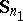 and
and 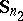 .
.
Multivariate statistical analysis of the nature and structure of correlations between the components of the multivariate attribute in question.
This branch unifies the ideas and results used in such methods and models of multivariate statistical analysis as multiple regression; multivariate dispersion analysis and covariance analysis; factor analysis; the method of principal components; and the analysis of canonical correlations. The results of this branch may be conventionally divided into two basic types.
1) The construction of best (in a specified sense) statistical estimators for the parameters of these models and the analysis of their properties (more precisely, and in a probabilistic formulation, of their distribution laws, confidence regions, etc.). Thus, let the multivariate attribute  be interpreted as a vector-valued random variable subject to the
be interpreted as a vector-valued random variable subject to the 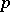 -dimensional normal distribution
-dimensional normal distribution 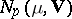 , and let it be partitioned into two subvectors
, and let it be partitioned into two subvectors 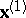 and
and 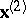 of dimensions
of dimensions 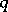 and
and 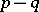 , respectively. This defines a corresponding partition of the expectation vector
, respectively. This defines a corresponding partition of the expectation vector 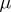 and of the theoretical and sample covariance matrices
and of the theoretical and sample covariance matrices  and
and 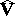 , namely:
, namely:
 |
Then (see [1], [2]) the conditional distribution of the subvector  (under the condition that the second subvector
(under the condition that the second subvector  takes a fixed value) will also be normal
takes a fixed value) will also be normal  . Here the maximum-likelihood estimators
. Here the maximum-likelihood estimators  and
and  of the matrices of regression coefficients
of the matrices of regression coefficients 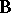 and covariances
and covariances 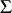 , in this classical multivariate model of multiple regression
, in this classical multivariate model of multiple regression
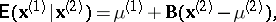 | (8) |
will be the mutually independent statistics
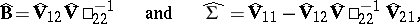 |
respectively. Here the distribution of 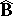 is the normal law
is the normal law 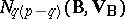 , and
, and 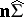 has the Wishart distribution with parameters
has the Wishart distribution with parameters 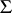 and
and 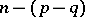 (the elements of
(the elements of  are given in terms of the elements of
are given in terms of the elements of 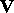 ).
).
The basic results on the construction of estimators of parameters and in the investigation of their properties in models of factor analysis, of principal components and of canonical correlations are related to the analysis of the probabilistic-statistical properties of the eigen values (characteristic values) and eigen vectors of the various covariance matrices.
In schemes not falling within the limits of the classical normal model or even within the limits of any probabilistic model, the basic results are concerned with the construction of algorithms (and the investigation of their properties) for calculating estimators of parameters which are best from the point of view of some exogeneously given functional of the quality (or adequacy) of the model.
2) The construction of statistical tests for the verification of various hypotheses on the structure of the correlations being investigated. Within the limits of a multivariate normal model (sequences of observations of the form (1) are interpreted as random samples from the corresponding multivariate normal population) statistical tests have been constructed for testing, for example, the following hypotheses.
I) The hypothesis 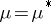 , i.e., that the expectation of the variables studied be equal to a specific vector
, i.e., that the expectation of the variables studied be equal to a specific vector 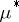 ; this is tested via the Hotelling
; this is tested via the Hotelling  -statistic by substituting
-statistic by substituting 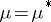 in (6).
in (6).
II) The hypothesis 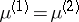 of equality of the expectation vectors in two populations (with identical but unknown covariance matrices), based on two samples; this is tested via the statistic
of equality of the expectation vectors in two populations (with identical but unknown covariance matrices), based on two samples; this is tested via the statistic 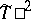 (see [7]).
(see [7]).
III) The hypothesis 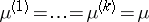 of equality of the expectation vectors in several populations (with identical but unknown covariance matrices), based on samples from them; this is tested via the statistic
of equality of the expectation vectors in several populations (with identical but unknown covariance matrices), based on samples from them; this is tested via the statistic
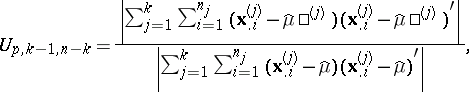 |
in which 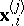 is the
is the 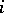 -th
-th 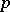 -dimensional observation in a sample of size
-dimensional observation in a sample of size 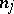 , representing the
, representing the 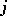 -th population, and
-th population, and 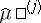 and
and  are estimators of the form (3), constructed separately with respect to each of the samples and with respect to the joint sample of size
are estimators of the form (3), constructed separately with respect to each of the samples and with respect to the joint sample of size 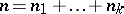 , respectively.
, respectively.
IV) The hypotheses 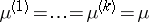 and
and 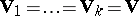 of equivalence of several normal populations, based on samples from them
of equivalence of several normal populations, based on samples from them 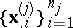 ,
, 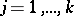 ; this is tested via the statistic
; this is tested via the statistic
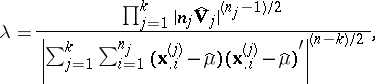 |
in which the 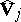 are estimators of the form (4) constructed separately with respect to the observations from the
are estimators of the form (4) constructed separately with respect to the observations from the 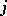 -th sample,
-th sample, 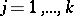 .
.
V) The hypothesis of mutual independence of the subvectors 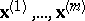 of dimensions
of dimensions 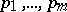 , respectively, into which the initial
, respectively, into which the initial 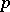 -dimensional vector
-dimensional vector  has been partitioned,
has been partitioned, 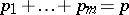 ; this is tested via the statistic
; this is tested via the statistic
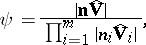 |
in which 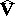 and
and 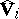 are sample covariance matrices of the form (4) for the vector
are sample covariance matrices of the form (4) for the vector  and its subvectors
and its subvectors 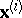 , respectively.
, respectively.
Multivariate statistical analysis of the geometric structure of the set of multi-dimensional observations being investigated.
This branch unifies notions and results of models and schemes such as discriminant analysis, mixtures of probability distributions, cluster analysis, taxonomy, and multi-dimensional scaling. The key in all of these schemes is a notion of distance (measure of proximity, measure of similarity) between the elements being analyzed. Here the objects being analyzed may both be real objects, in each of which the values of the components  are fixed — then in the geometrical representation the
are fixed — then in the geometrical representation the 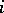 -th object will be a point
-th object will be a point 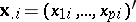 in the corresponding
in the corresponding 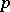 -dimensional space, as well as the variables
-dimensional space, as well as the variables 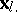 ,
, 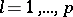 , themselves — in the geometrical representation the
, themselves — in the geometrical representation the 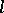 -th index will be a point
-th index will be a point 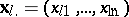 in the corresponding
in the corresponding  -dimensional space.
-dimensional space.
The methods and results of discriminant analysis (see [1], [2], [7]) are directed to the solution of the following problem. Suppose that the existence of a specific number 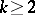 of populations is known and that there is a sample from each (a "training sample" ) known. It is required to construct, on the basis of training samples, the best, in a specified sense, classifying rule which allows one to attribute some new element (an observation
of populations is known and that there is a sample from each (a "training sample" ) known. It is required to construct, on the basis of training samples, the best, in a specified sense, classifying rule which allows one to attribute some new element (an observation  ) to its population, when the investigator does not know in advance to which population the element belongs. Usually, a classification rule means a sequence of actions; the calculation of a scalar function of the variables in question, based on which a decision is taken on assigning the element to one of the classes (the construction of a discriminant function); an ordering of the variables themselves according to their degree of informativeness from the point of view of a proper assignment of elements to classes; and a calculation of the corresponding probabilities of the errors in the classification.
) to its population, when the investigator does not know in advance to which population the element belongs. Usually, a classification rule means a sequence of actions; the calculation of a scalar function of the variables in question, based on which a decision is taken on assigning the element to one of the classes (the construction of a discriminant function); an ordering of the variables themselves according to their degree of informativeness from the point of view of a proper assignment of elements to classes; and a calculation of the corresponding probabilities of the errors in the classification.
The problem of analysis of a mixture of probability distributions (see [7]) most often (but not always) also arises in connection with the investigation of the "geometric structure" of some population. Here the idea of the  -th homogeneous class is formalized with the help of a population described by some (as a rule, unimodal) distribution law
-th homogeneous class is formalized with the help of a population described by some (as a rule, unimodal) distribution law 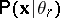 , so that the distribution of the general population from which the sample (1) is extracted is described by a mixture of distributions of the form
, so that the distribution of the general population from which the sample (1) is extracted is described by a mixture of distributions of the form
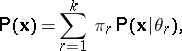 |
where 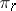 is the a priori probability (the specific weight of the elements) of the
is the a priori probability (the specific weight of the elements) of the  -th class in the general population. The problem is to give a "good" statistical estimation (with respect to a sample
-th class in the general population. The problem is to give a "good" statistical estimation (with respect to a sample 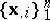 ) of the unknown parameters
) of the unknown parameters 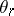 ,
, 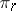 , and sometimes even
, and sometimes even 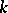 . This, in particular, allows one to reduce the problem of the classification of the elements to a scheme of discriminant analysis, although in this case training samples are absent.
. This, in particular, allows one to reduce the problem of the classification of the elements to a scheme of discriminant analysis, although in this case training samples are absent.
The methods and results of cluster analysis (classification, taxonomy, pattern recognition "without a teacher" , see [2], [6], [7]) are directed to the solution of the following problem. The geometric structure of the set of elements to be analyzed is given either by the coordinates of the corresponding points (that is, by the matrix 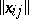 ,
, 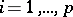 ,
, 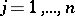 ), or by geometric characteristics of their mutual disposition, for example, by the matrix of pairwise distances
), or by geometric characteristics of their mutual disposition, for example, by the matrix of pairwise distances 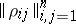 . It is required to partition the set of elements being investigated into a comparatively small (known in advance or not) number of classes, so that the elements of a class are at a small distance from each other, and at the same time different classes should, as far as possible, be sufficiently far from each other and could not be partitioned into other subsets equally far from each other.
. It is required to partition the set of elements being investigated into a comparatively small (known in advance or not) number of classes, so that the elements of a class are at a small distance from each other, and at the same time different classes should, as far as possible, be sufficiently far from each other and could not be partitioned into other subsets equally far from each other.
The problem of multi-dimensional scaling (see [6]) is related to the situation when the set of elements being investigated is given via a matrix of mutual distances 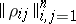 and consists of attributing to each of the elements a given number (
and consists of attributing to each of the elements a given number (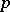 ) of coordinates so that the structure of the mutual distances between the elements, measured using these auxiliary coordinates, would on the average differ least from that given. It should be noted that the basic results and methods of cluster analysis and multi-dimensional scaling have usually been developed without any assumptions regarding the probabilistic nature of the initial data.
) of coordinates so that the structure of the mutual distances between the elements, measured using these auxiliary coordinates, would on the average differ least from that given. It should be noted that the basic results and methods of cluster analysis and multi-dimensional scaling have usually been developed without any assumptions regarding the probabilistic nature of the initial data.
The merits of multivariate statistical analysis in practice.
These consist mainly in processing the following three problems.
The problem of statistical investigation of dependence between the variables being analyzed.
Suppose that the set of recorded statistical variables  partitions, according to the meaning of these variables and the final aim of investigation, into a
partitions, according to the meaning of these variables and the final aim of investigation, into a 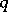 -dimensional subvector
-dimensional subvector 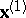 of (dependent) variables to be predicted and a
of (dependent) variables to be predicted and a 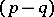 -dimensional subvector
-dimensional subvector 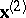 of predicting (independent) variables. Then it can be said that the problem is to determine, on the basis of a sample (1), a
of predicting (independent) variables. Then it can be said that the problem is to determine, on the basis of a sample (1), a 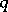 -dimensional vector-valued function
-dimensional vector-valued function 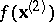 from the class of acceptable decisions
from the class of acceptable decisions 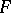 , which would give the best, in a specific sense, approximation of the behaviour of the subvector
, which would give the best, in a specific sense, approximation of the behaviour of the subvector 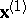 . Depending on the concrete form of the functional of the quality of the approximation and the nature of the variables being analyzed, one arrives at some scheme of multiple regression, variance, covariance, or confluence analysis [8].
. Depending on the concrete form of the functional of the quality of the approximation and the nature of the variables being analyzed, one arrives at some scheme of multiple regression, variance, covariance, or confluence analysis [8].
The problem of classifying elements.
This problem in a general (non-rigorous) formulation is that the whole set of elements (objects or variables) being analyzed, represented statistically as a matrix 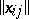 ,
, 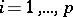 ,
, 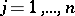 , or a matrix
, or a matrix 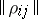 ,
, 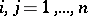 , partitions into a comparatively small number of homogeneous (in a specified sense) groups [7]. Depending on the behaviour of the a priori information and the concrete form of the functional giving the criteria for the quality of the classification, one arrives at some scheme of discriminant analysis, cluster analysis (taxonomy, pattern recognition "without a teacher" ), or splitting mixtures of distributions.
, partitions into a comparatively small number of homogeneous (in a specified sense) groups [7]. Depending on the behaviour of the a priori information and the concrete form of the functional giving the criteria for the quality of the classification, one arrives at some scheme of discriminant analysis, cluster analysis (taxonomy, pattern recognition "without a teacher" ), or splitting mixtures of distributions.
The problem of lowering the dimension of the factor space being investigated and the selection of the most informative variables.
This consists of defining a set of a comparatively small number 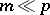 of variables
of variables 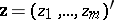 in the class of admissible transformations
in the class of admissible transformations  of the initial variables
of the initial variables 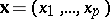 for which some exogeneously given measure of informativity for an
for which some exogeneously given measure of informativity for an 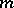 -dimensional system of tests attains its least upper bound (see [7]). Concretization of the functional giving the measure of self-informativity (that is, aimed at a maximal preservation of the information contained in the statistical ensemble (1) relative to the initial attributes themselves) results, in particular, in various schemes of factor analysis and principal components, and in the method of extremal grouping of tests. Functionals giving a measure of external informativity, that is, aimed at extracting from (1) maximum information relative to certain other variables or phenomena not directly contained in
-dimensional system of tests attains its least upper bound (see [7]). Concretization of the functional giving the measure of self-informativity (that is, aimed at a maximal preservation of the information contained in the statistical ensemble (1) relative to the initial attributes themselves) results, in particular, in various schemes of factor analysis and principal components, and in the method of extremal grouping of tests. Functionals giving a measure of external informativity, that is, aimed at extracting from (1) maximum information relative to certain other variables or phenomena not directly contained in  , lead to different methods of selecting the most informative variables in schemes of statistical research into dependences and discriminant analysis.
, lead to different methods of selecting the most informative variables in schemes of statistical research into dependences and discriminant analysis.
Fundamental mathematical tools in multivariate statistical analysis.
These consist of special methods of the theory of systems of linear equations and matrices (the method of solution of simple and generalized problems on eigen values and vectors; simple inversion and pseudo-inversion of matrices; a procedure for the diagonalization of matrices; etc.) and certain optimization algorithms (methods of coordinate-wise descent, conjugate gradients, branch-and-bound, various versions of random scanning and stochastic approximation, etc.).
References
| [1] | T.W. Anderson, "An introduction to multivariate statistical analysis" , Wiley (1958) |
| [2] | M.G. Kendall, A. Stuart, "The advanced theory of statistics" , 3 , Griffin (1983) |
| [3] | L.N. Bol'shev, Bull. Int. Stat. Inst. , 43 (1969) pp. 425–441 |
| [4] | J. Wishart, Biometrika , 20A (1928) pp. 32–52 |
| [5] | H. Hotelling, "The generalization of student's ratio" Ann. Math. Statist. , 2 (1931) pp. 360–378 |
| [6] | J.B. Kruskal, "Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis" Psychometrika , 29 (1964) pp. 1–27 |
| [7] | S.A. Aivazyan, V.M. Bukhshtaber, I.S. Yenyukov, L.D. Meshalkin, "Applied statistics: classification and reduction of dimensionality" , Moscow (1989) (In Russian) |
| [8] | S.A. Aivazyan, I.S. Yenyukov, L.D. Meshalkin, "Applied statistics: study of relationships" , Moscow (1985) (In Russian) |
Comments
References
| [a1] | R. Gnanadesikan, "Methods for statistical data analysis of multivariate observations" , Wiley (1977) |
| [a2] | M.J. Schervish, Stat. Science , 2 (1987) pp. 396–433 |
| [a3] | R. Farrell, "Techniques of multivariate calculation" , Springer (1976) |
| [a4] | M.L. Eaton, "Multivariate statistics: A vector space approach" , Wiley (1983) |
| [a5] | R.J. Muirhead, "Aspects of multivariate statistical theory" , Wiley (1982) |
Multi-dimensional statistical analysis. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Multi-dimensional_statistical_analysis&oldid=14286