Errors, theory of
The branch of mathematical statistics devoted to the inference of accurate conclusions about the numerical values of approximately measured quantities, as well as on the errors in the measurements. Repeated measurements of one and the same constant quantity generally give different results, since every measurement contains a certain error. There are three basic types of error: systematic, gross and random. Systematic errors always either overestimate or underestimate the results of measurements and arise for specific reasons (incorrect set-up of measuring equipment, the effect of environment, etc.), which systematically affect the measurements and alter them in one direction. The estimation of systematic errors is achieved using methods which go beyond the confines of mathematical statistics (see Processing of observations). Gross errors (often called outliers) arise from miscalculations, incorrect reading of the measuring equipment, etc. The results of measurements which contain gross errors differ greatly from other results of measurements and are therefore often easy to identify. Random errors arise from various reasons which have an unforeseen effect on each of the measurements, both in overestimating and in underestimating results.
The theory of errors is only concerned with the study of gross and random errors. The basic problems of the theory of errors are to study the distribution laws of random errors, to seek estimates (see Statistical estimator) of unknown parameters using the results of measurements, to establish the errors in these estimates, and to identify gross errors. Let the values 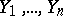 be obtained as a result of
be obtained as a result of  independent, equally accurate measurements of a certain unknown variable
independent, equally accurate measurements of a certain unknown variable 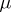 . The differences
. The differences
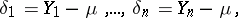 |
are called the true errors. In terms of the probability theory of errors all 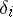 are treated as random variables; independence of measurements is understood to be mutual independence of the random variables
are treated as random variables; independence of measurements is understood to be mutual independence of the random variables  . The equal accuracy of the measurements is treated broadly as an identical distribution: The true errors of equally accurate measurements are identically distributed random variables. The mathematical expectation of the true errors
. The equal accuracy of the measurements is treated broadly as an identical distribution: The true errors of equally accurate measurements are identically distributed random variables. The mathematical expectation of the true errors 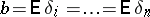 is then called the systematic error, while the differences
is then called the systematic error, while the differences 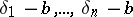 are called the random errors. Thus, the absence of a systematic error means that
are called the random errors. Thus, the absence of a systematic error means that 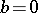 , and, in this situation,
, and, in this situation,  are random errors. The variable
are random errors. The variable 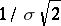 , where
, where 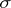 is the standard deviation, is called the measure of accuracy (when a systematic error occurs, the measure of accuracy is expressed by the relation
is the standard deviation, is called the measure of accuracy (when a systematic error occurs, the measure of accuracy is expressed by the relation 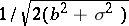 ). Equal accuracy of measurements is understood in a narrow sense to mean the equality of the measure of accuracy for all the results of the measurements. The incidence of gross errors signifies the disruption of equal accuracy (both in the broad and narrow sense) for certain specific measurements. As an estimator of the unknown value
). Equal accuracy of measurements is understood in a narrow sense to mean the equality of the measure of accuracy for all the results of the measurements. The incidence of gross errors signifies the disruption of equal accuracy (both in the broad and narrow sense) for certain specific measurements. As an estimator of the unknown value 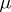 one usually takes the arithmetic mean from the results of the measurements:
one usually takes the arithmetic mean from the results of the measurements:
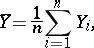 |
while the differences 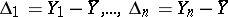 are called the apparent errors. The choice of
are called the apparent errors. The choice of 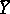 as an estimator for
as an estimator for 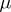 is based on the fact that for any sufficiently large number
is based on the fact that for any sufficiently large number  of equally accurate measurements with no systematic error,
of equally accurate measurements with no systematic error, 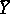 , with probability arbitrarily close to one, differs by an arbitrarily small amount from the unknown variable
, with probability arbitrarily close to one, differs by an arbitrarily small amount from the unknown variable 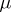 (see Law of large numbers);
(see Law of large numbers); 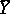 is free of systematic errors (estimators with this property are called unbiased, cf. also Unbiased estimator), and its variance is
is free of systematic errors (estimators with this property are called unbiased, cf. also Unbiased estimator), and its variance is
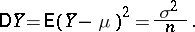 |
Experience has shown that in practice the random errors 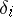 are very often subject to almost normal distributions (the reasons for this are revealed in the so-called limit theorems of probability theory). In this case the variable
are very often subject to almost normal distributions (the reasons for this are revealed in the so-called limit theorems of probability theory). In this case the variable 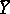 has an almost normal distribution with mathematical expectation
has an almost normal distribution with mathematical expectation 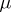 and variance
and variance 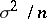 . If the distributions of
. If the distributions of 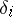 are exactly normal, then the variance of every other unbiased estimator for
are exactly normal, then the variance of every other unbiased estimator for 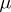 , for example the median (cf. Median (in statistics)), is not less than
, for example the median (cf. Median (in statistics)), is not less than 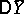 . If the distribution of
. If the distribution of 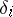 is not normal, then the latter property need not hold (see the example under Rao–Cramér inequality).
is not normal, then the latter property need not hold (see the example under Rao–Cramér inequality).
If the variance 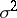 of separate measurements is previously unknown, then the variable
of separate measurements is previously unknown, then the variable
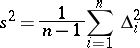 |
is used as estimator for it (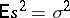 , i.e.
, i.e. 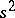 is an unbiased estimator for
is an unbiased estimator for 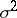 ). If the random errors
). If the random errors 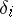 have a normal distribution, then the relation
have a normal distribution, then the relation
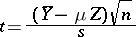 |
is subject to the Student distribution with 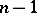 degrees of freedom. This can be used to estimate the error of the approximate equality
degrees of freedom. This can be used to estimate the error of the approximate equality 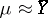 (see Least squares, method of).
(see Least squares, method of).
The variable 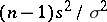 has under the same assumptions a "chi-squared" distribution with
has under the same assumptions a "chi-squared" distribution with 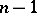 degrees of freedom. This enables one to estimate the error of the approximate equality
degrees of freedom. This enables one to estimate the error of the approximate equality 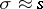 . It can be demonstrated that the relative error will not exceed the number
. It can be demonstrated that the relative error will not exceed the number 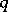 with probability
with probability
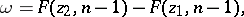 |
where 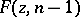 is the
is the 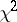 -distribution function,
-distribution function,
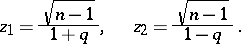 |
If certain measurements contain gross errors, then the above rules for estimating 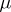 and
and 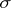 will give distorted results. It is therefore very important to be able to differentiate measurements which contain gross errors from those which are subject only to random errors
will give distorted results. It is therefore very important to be able to differentiate measurements which contain gross errors from those which are subject only to random errors 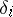 . For the case where
. For the case where 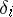 are independent and have an identical normal distribution, a comprehensive method for identifying measurements which contain gross errors was proposed by N.V. Smirnov [3].
are independent and have an identical normal distribution, a comprehensive method for identifying measurements which contain gross errors was proposed by N.V. Smirnov [3].
References
| [1] | Yu.V. Linnik, "Methode der kleinste Quadraten in moderner Darstellung" , Deutsch. Verlag Wissenschaft. (1961) (Translated from Russian) |
| [2] | L.N. Bol'shev, N.V. Smirnov, "Tables of mathematical statistics" , Libr. math. tables , 46 , Nauka (1983) (In Russian) (Processed by L.S. Bark and E.S. Kedrova) |
| [3] | N.V. Smirnov, "On the estimation of the maximum term in a series of observations" Dokl. Akad. Nauk SSSR , 33 : 5 (1941) pp. 346–349 (In Russian) |
Comments
Modern developments in the treatment of errors include robust estimation and outlier detection and treatment.
The intuitive definition of an outlier is: an observation which deviates so much from other observations as to arouse suspicions that it was generated by a different mechanism (than the one under observation). This includes errors such as can arise for instance because data were copied incorrectly. Outliers are dangerous for many statistical procedures. One way to deal with outliers is to use outlier tests to accept or reject the hypothesis that an observation 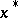 belongs to a sample from a random variable or not. The observations for which this hypothesis is rejected are then removed. Other methods for dealing with outliers include censoring, the use of robust methods and Winsorization (which is robust), of which the underlying idea is to move all excessively outlying observations in some systematic way to a position near the more central observations. One mechanism which may cause (apparent) outliers is when the data come from a heavy tailed distribution. Another one is when the data come from two distributions: a basic one which yields "good" observations and a second contaminating distribution. Which treatment of outliers is appropriate depends of course heavily on the mechanism generating the outliers. A selection of references on outliers and methods for treating them is [a1]–.
belongs to a sample from a random variable or not. The observations for which this hypothesis is rejected are then removed. Other methods for dealing with outliers include censoring, the use of robust methods and Winsorization (which is robust), of which the underlying idea is to move all excessively outlying observations in some systematic way to a position near the more central observations. One mechanism which may cause (apparent) outliers is when the data come from a heavy tailed distribution. Another one is when the data come from two distributions: a basic one which yields "good" observations and a second contaminating distribution. Which treatment of outliers is appropriate depends of course heavily on the mechanism generating the outliers. A selection of references on outliers and methods for treating them is [a1]–.
Robust statistics in a loose sense tries to deal with the fact that many often made assumptions such as normality, linearity, independence are at best approximations to the real situation. Thus, one looks for tests, statistical procedures
are at best approximations to the real situation. Thus, one looks for tests, statistical procedures which are, for instance, insensitive to the assumption that the underlying distribution is normal. Let the statistical model being used be, e.g., a parametrized family of distributions
which are, for instance, insensitive to the assumption that the underlying distribution is normal. Let the statistical model being used be, e.g., a parametrized family of distributions 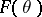 conceived of as lying in a larger space of distributions
conceived of as lying in a larger space of distributions 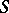 . One main aspect of robust statistics is then the study of the effects of deformations of
. One main aspect of robust statistics is then the study of the effects of deformations of  in
in 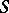 on the various statistical procedures being used. Similar concerns have motivated the study of deformations in other parts of mathematics, for instance deformations of dynamical systems. More generally, robust statistics is concerned with statistical concepts which describe the behaviour of statistical procedures not only under parametric models but also in the neighbourhoods of such models.
on the various statistical procedures being used. Similar concerns have motivated the study of deformations in other parts of mathematics, for instance deformations of dynamical systems. More generally, robust statistics is concerned with statistical concepts which describe the behaviour of statistical procedures not only under parametric models but also in the neighbourhoods of such models.
Robust statistics is by now is large active field. A selection of books on the topic is [a5]–[a7].
References
| [a1] | Th.S. Ferguson, "Rules for rejection of outliers" Rev. Inst. Int. Stat. , 29 (1961) pp. 29–43 |
| [a2] | D.M. Hawkins, "Identification of outliers" , Chapman & Hall (1980) |
| [a3] | W.J. Dixon, "Simplified estimation from censored normal samples" Ann. Math. Stat. , 31 (1960) pp. 385–391 |
| [a4a] | A.E. Sarhan, B.G. Greenberg, "Estimation of location and scale parameters by order statistics from singly and doubly censored samples I" Ann. Math. Stat. , 27 (1956) pp. 427–451 |
| [a4b] | A.E. Sarhan, B.G. Greenberg, "Estimation of location and scale parameters by order statistics from singly and doubly censored samples II" Ann. Math. Stat. , 29 (1958) pp. 79–105 |
| [a5] | P.J. Huber, "Robust statistics" , Wiley (1981) |
| [a6] | F.R. Hampel, E.M. Ronchetti, P.J. Rousseeuw, W.A. Stahel, "Robust statistics. The approach based on influence functions" , Wiley (1986) |
| [a7] | W.J.J. Rey, "Introduction to robust and quasi-robust statistical methods" , Springer (1983) |
| [a8] | W.T. Federer, "Statistics and society. Data collection and interpretation" , M. Dekker (1973) |
Errors, theory of. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Errors,_theory_of&oldid=28547