EM algorithm
expectation-maximization algorithm
An iterative optimization procedure [a4] for computing
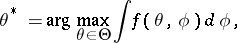 | (a1) |
where 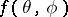 is a non-negative real valued function which is integrable as a function of
is a non-negative real valued function which is integrable as a function of 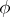 for each
for each 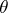 . The EM algorithm was developed for statistical inference in problems with incomplete data or problems that can be formulated as such (e.g., with latent-variable modeling) and is a very popular method of computing maximum likelihood, restricted maximum likelihood, penalized maximum likelihood, and maximum posterior estimates. The name, EM algorithm, stems from this context, where "E" stands for the expectation (i.e., integration) step and "M" stands for the maximization step. In particular, the algorithm starts with an initial value
. The EM algorithm was developed for statistical inference in problems with incomplete data or problems that can be formulated as such (e.g., with latent-variable modeling) and is a very popular method of computing maximum likelihood, restricted maximum likelihood, penalized maximum likelihood, and maximum posterior estimates. The name, EM algorithm, stems from this context, where "E" stands for the expectation (i.e., integration) step and "M" stands for the maximization step. In particular, the algorithm starts with an initial value 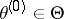 and iterates until convergence the two following steps for
and iterates until convergence the two following steps for 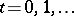 :'
:'
<tbody> </tbody>
|
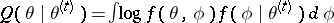 ,
,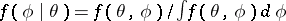 ;
;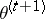 by maximizing
by maximizing 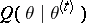 ,
,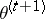 so that
so that for all
for all 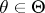 .
.The usefulness of the EM algorithm is apparent when both of these steps can be accomplished with minimal analytic and computation effort but either the direct maximization or the integration in (a1) is difficult. The attractive convergence properties of the algorithm along with its many generalizations and extensions will be discussed below. First, however, an illustration of the algorithm via several applications is given.
Applications.
Maximum-likelihood estimation with missing observations.
The standard notation and terminology for the EM algorithm stem from this important class of applications. In this case the function 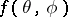 is the complete-data likelihood function, which is written
is the complete-data likelihood function, which is written 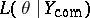 , where
, where 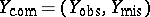 is the complete data which consists of the observed data,
is the complete data which consists of the observed data, 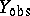 , and the missing data,
, and the missing data, 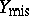 ,
, 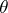 is a model parameter, and
is a model parameter, and 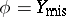 . One is interested in computing the value of
. One is interested in computing the value of 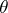 that maximizes
that maximizes 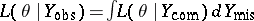 , the maximum-likelihood estimate. Here it is assumed that
, the maximum-likelihood estimate. Here it is assumed that 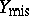 is missing at random [a26]; more complicated missing data mechanisms can also be accounted for in the formulation of
is missing at random [a26]; more complicated missing data mechanisms can also be accounted for in the formulation of  . More generally, one can augment
. More generally, one can augment 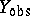 to
to 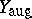 , the augmented data, via a many-to-one mapping,
, the augmented data, via a many-to-one mapping, 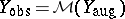 , with the understanding that the augmented-data likelihood,
, with the understanding that the augmented-data likelihood, 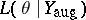 , is linked to
, is linked to 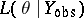 via
via 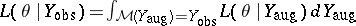 .
.
The EM algorithm builds on the intuitive notion that:
i) if there were no missing data, maximum-likelihood estimation would be easy; and
ii) if the model parameters were known, the missing data could easily be imputed (i.e., predicted) by its conditional expectation. These two observations correspond to the M-step and the E-step, respectively, with the proviso that not the missing data, but rather the complete-data log-likelihood should be imputed by its conditional expectation. In particular, the E-step reduces to computing
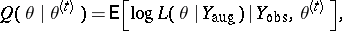 |
the conditional expectation of the complete-data log-likelihood. If the complete-data model is from an exponential family, then 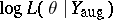 is linear in a set of complete-data sufficient statistics. In this common case which includes multivariate normal, Poisson, multinomial, and exponential models (among others), computing
is linear in a set of complete-data sufficient statistics. In this common case which includes multivariate normal, Poisson, multinomial, and exponential models (among others), computing 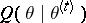 involves routine calculations. The M-step then involves computing the maximum-likelihood estimates as if there were no missing data, by using the imputed complete-data sufficient statistics from the E-step as inputs.
involves routine calculations. The M-step then involves computing the maximum-likelihood estimates as if there were no missing data, by using the imputed complete-data sufficient statistics from the E-step as inputs.
Linear inverse problems with positivity restrictions.
Consider the system of equations
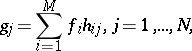 |
where 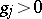 ,
, 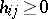 ,
, 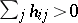 are known, and one wishes to solve for
are known, and one wishes to solve for 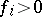 . Such problems are omnipresent in scientific and engineering applications and can be solved with the EM algorithm [a30]. First one notes that, without loss of generality, one may assume that
. Such problems are omnipresent in scientific and engineering applications and can be solved with the EM algorithm [a30]. First one notes that, without loss of generality, one may assume that 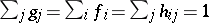 , that is,
, that is, 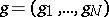 ,
, 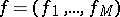 and
and 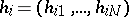 for
for 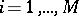 are discrete probability measures (see [a30] for details). Thus,
are discrete probability measures (see [a30] for details). Thus, 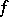 can be viewed as the mixing weights in a finite mixture model, i.e.,
can be viewed as the mixing weights in a finite mixture model, i.e., 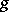 . A finite mixture model is a hierarchical model in that one can suppose that an integer
. A finite mixture model is a hierarchical model in that one can suppose that an integer 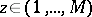 is chosen according to
is chosen according to 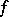 , and then data are generated conditional on
, and then data are generated conditional on  according to
according to 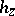 . The marginal distribution of the data generated is
. The marginal distribution of the data generated is 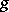 . If one considers
. If one considers  to be missing data, one can derive an EM algorithm of the form
to be missing data, one can derive an EM algorithm of the form
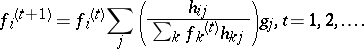 |
Y. Vardi and D. Lee [a30] demonstrate that this iteration converges to the value that minimizes the Kullback–Leibler information divergence between 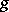 and
and  over all non-negative
over all non-negative 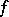 , which is the desired non-negative solution if it exists.
, which is the desired non-negative solution if it exists.
Multivariate 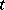 -model, a latent variable model.
-model, a latent variable model.
The previous example illustrates an important principle in the application of the EM algorithm. Namely, one is often initially interested in optimizing a function 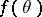 and purposely embeds
and purposely embeds 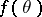 in a function,
in a function, 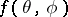 , with a larger domain, such that
, with a larger domain, such that 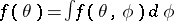 , in order to use the EM algorithm. In the previous example, this was accomplished by identifying
, in order to use the EM algorithm. In the previous example, this was accomplished by identifying 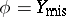 with
with  . Similar strategies are often fruitful in various latent variable models. Consider, for example, the multivariate
. Similar strategies are often fruitful in various latent variable models. Consider, for example, the multivariate 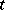 -model, which is useful for robust estimation (cf. Robust statistics; see also, e.g., [a9], [a11]),
-model, which is useful for robust estimation (cf. Robust statistics; see also, e.g., [a9], [a11]),
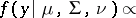 | (a2) |
 |
where 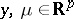 ,
, 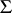 is a positive-definite
is a positive-definite 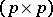 -matrix,
-matrix, 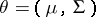 , and
, and 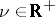 is the known degree of freedom. Given a random sample
is the known degree of freedom. Given a random sample 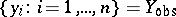 , assumed to be from (a2), one wishes to find the maximizer of
, assumed to be from (a2), one wishes to find the maximizer of  , which is known to have no general closed-form solution. In order to apply the EM algorithm, one embeds
, which is known to have no general closed-form solution. In order to apply the EM algorithm, one embeds  into a larger model
into a larger model  . This is accomplished via the well-known representation
. This is accomplished via the well-known representation
 | (a3) |
where 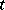 follows the
follows the 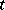 -distribution in (a2),
-distribution in (a2), 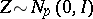 , and
, and  is a mean chi-square variable with
is a mean chi-square variable with  degrees of freedom independent of
degrees of freedom independent of 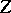 . In (a3), one sees that the distribution of
. In (a3), one sees that the distribution of 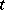 conditional on
conditional on 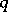 is multivariate normal. Thus, if one had observed
is multivariate normal. Thus, if one had observed 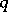 , maximum-likelihood estimation would be easy. One therefore defines
, maximum-likelihood estimation would be easy. One therefore defines 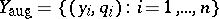 and
and 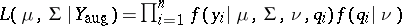 , which is easy to maximize as a function of
, which is easy to maximize as a function of 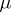 and
and 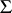 due to the conditional normality of
due to the conditional normality of  . Thus, since
. Thus, since 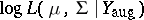 is linear in
is linear in 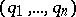 , the
, the 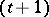 st iteration of the EM algorithm has a simple E-step that computes
st iteration of the EM algorithm has a simple E-step that computes
 |
where 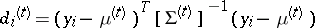 . The M-step then maximizes
. The M-step then maximizes 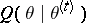 to obtain
to obtain
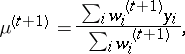 |
and
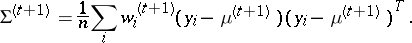 | (a4) |
Given the weights 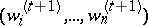 , the M-step corresponds to weighted least squares, thus this EM algorithm, which often goes by the name iteratively reweighted least squares (IRLS), is trivial to program and use, and, as will be seen in the next section, exhibits unusually stable convergence.
, the M-step corresponds to weighted least squares, thus this EM algorithm, which often goes by the name iteratively reweighted least squares (IRLS), is trivial to program and use, and, as will be seen in the next section, exhibits unusually stable convergence.
Properties of the EM algorithm.
The EM algorithm has enjoyed wide popularity in many scientific fields from the 1970s onwards (e.g., [a18], [a23]). This is primarily due to easy implementation and stable convergence. As the previous paragraph illustrates, the EM algorithm is often easy to program and use. Although the algorithm may take many iterations to converge relative to other optimization routines (e.g., Newton–Raphson), each iteration is often easy to program and quick to compute. Moreover, the EM algorithm is less sensitive to poor starting values, and can be easier to use with many parameters since the iterations necessarily remain in the parameter space and no second derivatives are required. Finally, the EM algorithm has the very important property that the objective function is increased at each iteration. That is, by the definition of 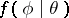 ,
,
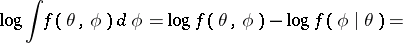 | (a5) |
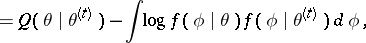 |
where the second equality follows by averaging over 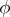 according to
according to 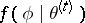 . Since the first term of (a5) is maximized by
. Since the first term of (a5) is maximized by 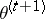 , and the second is minimized by
, and the second is minimized by 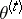 (under the assumption that the support of
(under the assumption that the support of 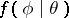 does not depend on
does not depend on 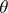 ), one obtains
), one obtains
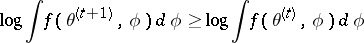 |
for 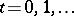 . This property not only contributes to the stability of the algorithm, but also is very valuable for diagnosing implementation errors.
. This property not only contributes to the stability of the algorithm, but also is very valuable for diagnosing implementation errors.
Although the EM algorithm is not guaranteed to converge to even a local mode (it can converge to a saddle point [a25] or even a local minimum [a1]), this can easily be avoided in practice by using several "overdispersed" starting values. (Details of convergence properties are developed in, a.o., [a4], [a32], [a2], [a21].) Running the EM algorithm with several starting values is also recommended because it can help one to find multiple local modes of 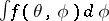 , an important advantage for statistical analysis.
, an important advantage for statistical analysis.
Extensions and enhancements.
The advantages of the EM algorithm are diminished when either the E-step or the M-step are difficult to compute or the algorithm is very slow to converge. There are a number of extensions to the EM algorithm that can be successful in dealing with these difficulties.
For example, the ECM algorithm ([a20], [a17]) is useful when 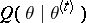 is difficult to maximize as a function of
is difficult to maximize as a function of 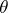 , but can be easily maximized when
, but can be easily maximized when 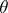 is constrained to one of several subspaces of the original parameter space. One assumes that the aggregation of these subspaces is space-filling in the sense that the sequence of conditional maximizations searches the entire parameter space. Thus, ECM replaces the M-step with a sequence of CM-steps (i.e., conditional maximizations) while maintaining the convergence properties of the EM algorithm, including monotone convergence.
is constrained to one of several subspaces of the original parameter space. One assumes that the aggregation of these subspaces is space-filling in the sense that the sequence of conditional maximizations searches the entire parameter space. Thus, ECM replaces the M-step with a sequence of CM-steps (i.e., conditional maximizations) while maintaining the convergence properties of the EM algorithm, including monotone convergence.
The situation is somewhat more difficult when the E-step is difficult to compute, since numerical integration can be very expensive computationally. The Monte-Carlo EM algorithm [a31] suggests using Monte-Carlo integration in the E-step. In some cases, Markov chain Monte-Carlo integration methods have been used successfully (e.g., [a15], [a16], [a22], [a3]). The nested EM algorithm [a27] offers a general strategy for efficient implementation of Markov chain Monte Carlo within the E-step of the EM algorithm.
Much emphasis in recent research is on speeding up the EM algorithm without sacrificing its stability or simplicity. A very fruitful method is through efficient data augmentation, that is, simple and "small" augmentation schemes, where "small" is measured by the so-called Fisher information — see [a23] and the accompanying discussion for details. Briefly, the smaller the augmentation, the better 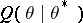 approximates
approximates 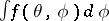 and thus the faster the algorithm; here,
and thus the faster the algorithm; here, 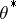 is the limit of the EM sequence — note that
is the limit of the EM sequence — note that 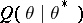 and
and 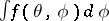 share the same stationary point(s) [a4]. Thus, the SAGE [a5], the ECME [a11], and the more general the AECM [a23] algorithms build on the ECM algorithm by allowing this approximation to vary from CM-step to CM-step, in order to obtain a better approximation for some CM-steps as long as this does not complicate the resulting CM-step. X.L. Meng and D.A. van Dyk [a23] also introduce a working parameter into
share the same stationary point(s) [a4]. Thus, the SAGE [a5], the ECME [a11], and the more general the AECM [a23] algorithms build on the ECM algorithm by allowing this approximation to vary from CM-step to CM-step, in order to obtain a better approximation for some CM-steps as long as this does not complicate the resulting CM-step. X.L. Meng and D.A. van Dyk [a23] also introduce a working parameter into 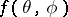 , that is, they define
, that is, they define  such that
such that
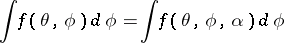 |
for all 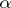 in some class
in some class 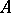 . They then choose
. They then choose 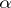 in order to optimize the approximation in terms of the rate of convergence of the resulting algorithm while maintaining the simplicity and stability of the EM algorithm. This results in simple, stable, and fast algorithms in a number of statistical applications. For example, in the
in order to optimize the approximation in terms of the rate of convergence of the resulting algorithm while maintaining the simplicity and stability of the EM algorithm. This results in simple, stable, and fast algorithms in a number of statistical applications. For example, in the 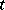 -model this procedure results in replacing the update for
-model this procedure results in replacing the update for 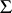 given in (a4) with
given in (a4) with
 |
The rest of the algorithm remains the same and this simple change clearly maintains the simplicity of the algorithm but can result in a dramatic reduction in computational time compared to the standard IRLS algorithm.
The parameter-expanded EM algorithm or PXEM algorithm [a12] also works with a working parameter, but rather than conditioning on the optimal 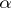 it marginalizes out
it marginalizes out 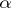 by fitting it in each iteration. Detailed discussion and comparison of such conditional augmentation and marginal augmentation in the more general context of stochastic simulations (e.g., the Gibbs sampler) can be found in [a24], [a13], and [a28].
by fitting it in each iteration. Detailed discussion and comparison of such conditional augmentation and marginal augmentation in the more general context of stochastic simulations (e.g., the Gibbs sampler) can be found in [a24], [a13], and [a28].
Other acceleration techniques have been developed by combining the EM algorithm with various numerical methods, such as Aitken acceleration (e.g., [a14]), Newton–Raphson [a7], quasi-Newton methods (e.g., [a8]), and conjugate-gradient acceleration [a6]. These methods, however, typically sacrifice monotone convergence and therefore require extra programming and special monitoring.
A final pair of extensions are designed to compute
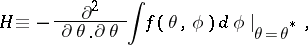 |
whose inverse gives a large-sample variance of 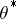 in statistical analysis. The supplemented EM [a19] and supplemented ECM [a29] algorithms combine the analytically computable
in statistical analysis. The supplemented EM [a19] and supplemented ECM [a29] algorithms combine the analytically computable
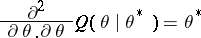 |
with numerical differentiation of the EM mapping in order to compute 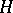 via a simple matrix identity.
via a simple matrix identity.
References
| [a1] | O. Arslan, P.D.L. Constable, J.T. Kent, "Domains of convergence for the EM algorithm: A cautionary tale in a location estimation problem" Statist. Comput. , 3 (1993) pp. 103–108 |
| [a2] | R.A. Boyles, "On the convergence of the EM algorithm" J.R. Statist. Soc. , B45 (1983) pp. 47–50 |
| [a3] | J.S.K. Chan, A.Y.C. Kuk, "Maximum likelihood estimation for probit-linear mixed models with correlated random effects" Biometrics , 53 (1997) pp. 86–97 |
| [a4] | A.P. Dempster, N.M. Laird, D.B. Rubin, "Maximum likelihood estimation from incomplete-data via the EM algorithm (with discussion)" J. R. Statist. Soc. , B39 (1977) pp. 1–38 |
| [a5] | J.A. Fessler, A.O. Hero, "Space-alternating generalized expectation-maximization algorithm" IEEE Trans. Signal Processing , 42 (1994) pp. 2664–77 |
| [a6] | M. Jamshidian, R.I. Jennrich, "Conjugate gradient acceleration of the EM algorithm" J. Amer. Statist. Assoc. , 88 (1993) pp. 221–228 |
| [a7] | K. Lange, "A gradient algorithm locally equivalent to the EM algorithm" J. R. Statist. Soc. , B57 (1995) pp. 425–438 |
| [a8] | K. Lange, "A quasi-Newtonian acceleration of the EM algorithm" Statistica Sinica , 5 (1995) pp. 1–18 |
| [a9] | K. Lange, R.J.A. Little, J.M.G. Taylor, "Robust statistical modeling using the t-distribution" J. Amer. Statist. Assoc. , 84 (1989) pp. 881–896 |
| [a10] | C. Liu, D.B. Rubin, "The ECME algorithm: a simple extension of EM and ECM with fast monotone convergence" Biometrika , 81 (1994) pp. 633–48 |
| [a11] | C. Liu, D.B. Rubin, "ML estimation of the t-distribution using EM and its extensions, ECM and ECME" Statistica Sinica , 5 (1995) pp. 19–40 |
| [a12] | C. Liu, D.B. Rubin, Y.N. Wu, "Parameter expansion to accelerate EM: the PX-EM algorithm" Biometrika (1998) pp. 755–770 |
| [a13] | J.S. Liu, Y. Wu, "Parameter expansion for data augmentation" J. Amer. Statist. Assoc. , to appear (1999) |
| [a14] | T.A. Louis, "Finding the observed information matrix when using the EM algorithm" J. R. Statist. Soc. , B44 (1982) pp. 226–233 |
| [a15] | C.E. McCulloch, "Maximum likelihood variance components estimation for binary data" J. Amer. Statist. Assoc. , 89 (1994) pp. 330–335 |
| [a16] | C.E. McCulloch, "Maximum likelihood algorithms for generalized linear mixed models" J. Amer. Statist. Assoc. , 92 (1997) pp. 162–170 |
| [a17] | X.L. Meng, "On the rate of convergence of the ECM algorithm" Ann. Math. Stat. , 22 (1994) pp. 326–339 |
| [a18] | X.L. Meng, S. Pedlow, "EM: A bibliographic review with missing articles" , Proc. Statist. Comput. Sect. 24-27 Washington, D.C. , Amer. Statist. Assoc. (1992) |
| [a19] | X.L. Meng, D.B. Rubin, "Using EM to obtain asymptotic variance-covariance matrices: the SEM algorithm" J. Amer. Statist. Assoc. , 86 (1991) pp. 899–909 |
| [a20] | X.L. Meng, D.B. Rubin, "Maximum likelihood estimation via the ECM algorithm: a general framework" Biometrika , 80 (1993) pp. 267–78 |
| [a21] | X.L. Meng, D.B. Rubin, "On the global and componentwise rates of convergence of the EM algorithm" LALG , 199 (1994) pp. 413–425 |
| [a22] | X.L. Meng, S. Schilling, "Fitting full-information item factor models and an empirical investigation of bridge sampling" J. Amer. Statist. Assoc. , 91 (1996) pp. 1254–1267 |
| [a23] | X.L. Meng, D.A. van Dyk, "The EM algorithm — an old folk song sung to a fast new tune (with discussion)" J. R. Statist. Soc. , B59 (1997) pp. 511–567 |
| [a24] | X.L. Meng, D.A. van Dyk, "Seeking efficient data augmentation schemes via conditional and marginal augmentation" Biometrika (1999) pp. 301–320 |
| [a25] | G.D. Murray, "Comments on the paper by A.P. Dempster, N.M. Laird and D.B. Rubin" J. R. Statist. Soc. , B39 (1977) pp. 27–28 |
| [a26] | D.B. Rubin, "Inference and missing data" Biometrika , 63 (1976) pp. 581–592 |
| [a27] | D.A. van Dyk, "Nesting EM Algorithms for computational efficiency" Statistica Sinica , to appear (2000) |
| [a28] | D.A. van Dyk, X.L. Meng, "The art of data augmentation" Statist. Sci. , Submitted (1999) |
| [a29] | D.A. van Dyk, X.L. Meng, D.B. Rubin, "Maximum likelihood estimation via the ECM algorithm: computing the asymptotic variance" Statistica Sinica , 5 (1995) pp. 55–75 |
| [a30] | Y. Vardi, D. Lee, "From image deblurring to optimal investments: maximum likelihood solutions for positive linear inverse problems (with discussion)" J. R. Statist. Soc. , B55 (1993) pp. 569–598 |
| [a31] | G.C.G. Wei, M.A. Tanner, "A Monte Carlo implementation of the EM algorithm and the poor man's data augmentation algorithm" J. Amer. Statist. Assoc. , 85 (1990) pp. 699–704 |
| [a32] | C.F.J. Wu, "On the convergence properties of the EM algorithm" Ann. Math. Stat. , 11 (1983) pp. 95–103 |
EM algorithm. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=EM_algorithm&oldid=15013