Adaptive algorithm
The use of adaptive algorithms is now (1998) very widespread across such varied applications as system identification, adaptive control, transmission systems, adaptive filtering for signal processing, and several aspects of pattern recognition and learning. Many examples can be found in the literature [a8], [a1], [a5]; see also, e.g., Adaptive sampling. The aim of an adaptive algorithm is to estimate an unknown time-invariant (or slowly varying) parameter vector, traditionally denoted by 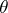 .
.
The study of adaptive algorithms is generally made through the theory of stochastic approximation.
Assume that observations 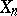 are related to the true parameter
are related to the true parameter 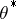 via an equation
via an equation
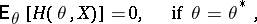 |
where 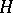 is known, but the distribution of
is known, but the distribution of 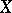 is unknown and may or may not depend on
is unknown and may or may not depend on 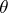 (as indicated by the subscript on
(as indicated by the subscript on  ). In many situations,
). In many situations, 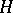 is the gradient of a functional to be minimized.
is the gradient of a functional to be minimized.
The general structure considered for stochastic algorithms is the following:
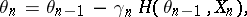 |
where 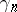 is a non-negative non-increasing sequence, typically
is a non-negative non-increasing sequence, typically 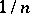 or a constant,
or a constant, 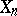 is the "somehow stationary" observed sequence and
is the "somehow stationary" observed sequence and 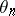 is at each
is at each  an improved estimate of
an improved estimate of 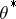 .
.
Note that when 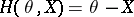 , and
, and 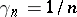 ,
, 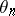 is simply the arithmetic mean of the
is simply the arithmetic mean of the 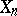 .
.
The easiest situation is when 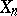 is a given sequence of independent identically-distributed random variables. However, this is not always the case: the classical Robbins–Monro algorithms correspond to the situation where a parameter
is a given sequence of independent identically-distributed random variables. However, this is not always the case: the classical Robbins–Monro algorithms correspond to the situation where a parameter 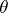 (e.g., a dosage of a chemical product) needs to be tuned so that the effect measured by
(e.g., a dosage of a chemical product) needs to be tuned so that the effect measured by 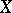 is at an average given level
is at an average given level 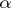 . In this case
. In this case 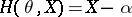 and
and 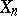 is the result of an experiment made with
is the result of an experiment made with 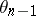 . Study of stochastic algorithms is generally restricted to those which have the Markovian structure introduced in [a1], where
. Study of stochastic algorithms is generally restricted to those which have the Markovian structure introduced in [a1], where 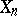 is a random variable depending only on
is a random variable depending only on 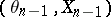 ; more precisely, the distribution of
; more precisely, the distribution of 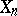 conditional to the whole past
conditional to the whole past 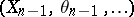 is given by a transition kernel
is given by a transition kernel 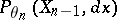 . In this case, the expectation above has to be taken with respect to the stationary distribution of the Markov chain
. In this case, the expectation above has to be taken with respect to the stationary distribution of the Markov chain 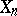 when
when 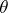 is fixed.
is fixed.
Decreasing gain.
In the case of decreasing gain, typical results which are proved are the almost-sure convergence of 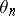 to a solution of the equation
to a solution of the equation 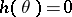 (where
(where 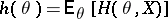 ), and, if
), and, if 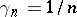 , the asymptotic normality of
, the asymptotic normality of 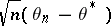 and the law of the iterated logarithm ([a3], [a6], [a1], [a4]). The asymptotic covariance matrix
and the law of the iterated logarithm ([a3], [a6], [a1], [a4]). The asymptotic covariance matrix 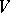 of
of  is the solution of the Lyapunov equation
is the solution of the Lyapunov equation
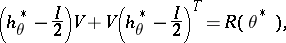 |
where
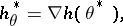 |
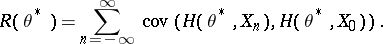 |
The expectation is taken with respect to the distribution of the sequence 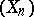 (in the general Markovian situation, one has to consider here the stationary distribution of the chain of transition kernels
(in the general Markovian situation, one has to consider here the stationary distribution of the chain of transition kernels 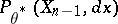 ). In particular, asymptotic normality occurs only if
). In particular, asymptotic normality occurs only if 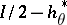 has only negative eigenvalues (otherwise the Lyapunov equation above has no solution). Improving this covariance may be done by insertion of a matrix gain (smallest
has only negative eigenvalues (otherwise the Lyapunov equation above has no solution). Improving this covariance may be done by insertion of a matrix gain (smallest 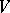 ),
),
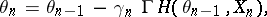 |
and a simple computation shows that the optimal gain is
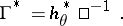 |
This matrix may be estimated during the algorithm, but convergence becomes quite difficult to prove. With this choice of the gain, the Cramér–Rao bound is attained. Another way is to use the Polyak–Ruppert averaging method [a7]:
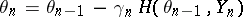 |
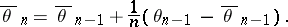 |
with a "larger" 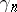 (typically
(typically 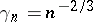 ). One can prove the asymptotic optimality of this algorithm.
). One can prove the asymptotic optimality of this algorithm.
Constant gain.
Constant-gain algorithms are used for tracking a slowly varying optimal parameter 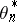 . The asymptotic behaviour of the algorithm may be studied when the speed of
. The asymptotic behaviour of the algorithm may be studied when the speed of 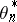 and
and 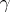 tend to zero [a1]; this so-called method of diffusion approximation consists in proving that, if
tend to zero [a1]; this so-called method of diffusion approximation consists in proving that, if 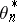 is fixed, then the trajectory of
is fixed, then the trajectory of 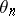 , suitably centred and rescaled in space and time, is well approximated by a diffusion. One shows that in the case of a smooth variation of
, suitably centred and rescaled in space and time, is well approximated by a diffusion. One shows that in the case of a smooth variation of 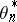 , the gain has to be tuned approximately proportional to
, the gain has to be tuned approximately proportional to 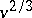 , where
, where  is the speed of variation of
is the speed of variation of 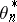 . On the other hand, if
. On the other hand, if 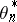 moves along a random walk, the gain has to be chosen proportional to the average amplitude of
moves along a random walk, the gain has to be chosen proportional to the average amplitude of 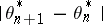 . Other authors study the stationary limit distribution of
. Other authors study the stationary limit distribution of 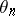 when
when 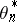 has a given distribution ([a2] and references therein). The direct on-line estimation of a good gain
has a given distribution ([a2] and references therein). The direct on-line estimation of a good gain 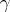 without a priori knowledge on the variation of
without a priori knowledge on the variation of 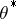 remains an important open problem.
remains an important open problem.
References
| [a1] | A. Benveniste, M. Métivier, P. Priouret, "Adaptive Algorithms and Stochastic Approximations" , Springer (1990) |
| [a2] | B. Delyon, A. Juditsky, "Asymptotical study of parameter tracking algorithms" SIAM J. Control and Optimization , 33 : 1 (1995) pp. 323–345 |
| [a3] | P. Hall, C.C. Heyde, "Martingale limit theory and its applications" , Acad. Press (1980) |
| [a4] | H.J. Kushner, D.S. Clark, "Stochastic Approximation Methods for Constrained and Unconstrained Systems" , Springer (1978) |
| [a5] | L. Ljung, T. Soderström, "Theory and practice of recursive identification" , MIT (1983) |
| [a6] | B.M. Nevel'son, R.Z. Khas'minskii, "Stochastic approximation and recursive estimation" , Transl. Math. Monogr. , 47 , Amer. Math. Soc. (1976) |
| [a7] | B.T. Polyak, "New stochastic approximation type procedures" Autom. Remote Contr. , 51 : 7 (1960) pp. 937–946 |
| [a8] | G.N. Saridis, "Stochastic approximation methods for identification and control — a survey" IEEE-AC , 19 : l6 (1974) |
Adaptive algorithm. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Adaptive_algorithm&oldid=49937