Algorithmic information theory
The branch of mathematical logic which gives a more exact formulation of the basic concepts of the theory of information, based on the concepts of an algorithm and a computable function. Algorithmic information theory attempts to give a base to these concepts without recourse to probability theory, so that the concepts of entropy and quantity of information might be applicable to individual objects. It also gives rise to its own problems, which are related to the study of the entropy of specific individual objects.
The key concept of algorithmic information theory is that of the entropy of an individual object, also called the (Kolmogorov) complexity of the object. The intuitive meaning of this concept is the minimum amount of information needed to reconstruct a given object. An exact definition of the concept of complexity of an individual object, and (on the basis of this concept) of the concept of the quantity of information in an individual object 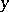 relative to an individual object
relative to an individual object  , was given by A.N. Kolmogorov in 1962–1965, after which the development of algorithmic information theory began.
, was given by A.N. Kolmogorov in 1962–1965, after which the development of algorithmic information theory began.
Without loss of generality, only binary words (linear strings of 0's and 1's) are considered. The complexity of a word  is understood to mean the length
is understood to mean the length 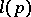 of the shortest binary word
of the shortest binary word 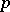 which contains all the information required to reconstruct
which contains all the information required to reconstruct  with the aid of some definite decoding procedure. A precise definition of this concept follows.
with the aid of some definite decoding procedure. A precise definition of this concept follows.
Let 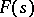 be an arbitrary universal partial recursive function. Then the complexity of the word
be an arbitrary universal partial recursive function. Then the complexity of the word  with respect to
with respect to 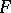 will be
will be
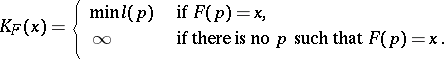 |
The word 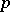 such that
such that 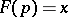 is known as the code, or the program, by which
is known as the code, or the program, by which 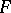 reconstructs the word
reconstructs the word  . The following theorem is valid: There exists a partial recursive function
. The following theorem is valid: There exists a partial recursive function  (an optimal function), such that for any partial recursive function
(an optimal function), such that for any partial recursive function 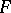 the following inequality holds:
the following inequality holds:
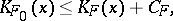 |
where 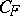 is a constant which is independent of
is a constant which is independent of  . This theorem yields an invariant (up to an additive constant) definition of complexity: The complexity
. This theorem yields an invariant (up to an additive constant) definition of complexity: The complexity  of the word
of the word  is the complexity
is the complexity  with respect to some partial recursive function
with respect to some partial recursive function  , which has been fixed once and for all. Clearly,
, which has been fixed once and for all. Clearly, 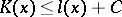 , where
, where 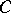 is a constant independent of
is a constant independent of  .
.
Using 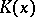 one may also determine the complexity
one may also determine the complexity 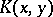 of pairs of words
of pairs of words 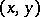 ; to do this, the pairs
; to do this, the pairs 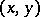 are effectively coded as one word
are effectively coded as one word 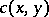 , and the complexity
, and the complexity 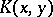 is understood to mean
is understood to mean 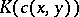 .
.
P. Martin-Löf studied the behaviour of the complexity of the initial segments of infinite binary sequences. Let 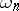 denote the initial segment of a sequence
denote the initial segment of a sequence 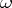 , consisting of the
, consisting of the  initial characters. Then almost all (according to the Lebesgue measure) infinite binary sequences
initial characters. Then almost all (according to the Lebesgue measure) infinite binary sequences 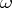 have the following properties: a) for infinitely many natural numbers
have the following properties: a) for infinitely many natural numbers  the inequality
the inequality  , where
, where  is some constant, is valid; and b) for all natural numbers
is some constant, is valid; and b) for all natural numbers  larger than some value
larger than some value 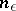 ,
,  , where
, where  is an arbitrary positive number (the Martin-Löf theorem). Conversely, for any sequence
is an arbitrary positive number (the Martin-Löf theorem). Conversely, for any sequence 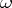 there exist infinitely many
there exist infinitely many  such that
such that  .
.
The concept of complexity is also employed in the study of algorithmic problems. Here, a more natural concept is the so-called complexity of solution of the word  . The intuitive meaning of this concept is the minimum quantity of information required to find, for each number
. The intuitive meaning of this concept is the minimum quantity of information required to find, for each number 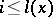 , the
, the 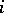 -th character of word
-th character of word  (the length of the word
(the length of the word  need not necessarily be known). More exactly, the complexity of solution of the word
need not necessarily be known). More exactly, the complexity of solution of the word  by a partial recursive function
by a partial recursive function 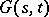 means that
means that
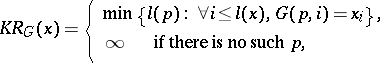 |
The following theorem is valid: There exists a partial recursive function 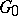 (an optimal function) such that any other partial recursive function
(an optimal function) such that any other partial recursive function 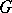 satisfies the inequality
satisfies the inequality 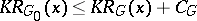 , where
, where 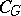 is a constant independent of
is a constant independent of  . The complexity of solution,
. The complexity of solution, 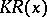 , of the word
, of the word  is the complexity
is the complexity 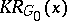 of some optimal partial recursive function
of some optimal partial recursive function  which has been fixed once and for all. Clearly,
which has been fixed once and for all. Clearly,  and
and 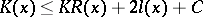 . It is possible, by using
. It is possible, by using 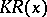 , to determine, for any set
, to determine, for any set 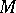 of natural numbers, the complexity
of natural numbers, the complexity  for the
for the  -segment of the set
-segment of the set 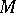 :
:  , where
, where 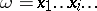 is the characteristic sequence of the set
is the characteristic sequence of the set  (
( if
if 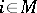 , and
, and  if
if 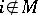 ).
).
Algorithmic problems are usually represented as problems of belonging to some recursively enumerable set 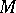 . If some value
. If some value  is given, and the problem of belonging to
is given, and the problem of belonging to 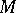 is restricted to the first
is restricted to the first  natural numbers only, then one obtains a bounded algorithmic problem. The magnitude
natural numbers only, then one obtains a bounded algorithmic problem. The magnitude 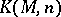 may be intuitively understood as expressing the quantity of information required to solve this bounded problem. In particular, the set
may be intuitively understood as expressing the quantity of information required to solve this bounded problem. In particular, the set 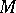 is recursive if and only if
is recursive if and only if 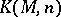 is bounded from above by some constant.
is bounded from above by some constant.
It follows from the Martin-Löf theorem that there exist sets for which 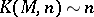 . It was also found that sets with maximum degree of complexity exist even among sets defined by arithmetic predicates with two quantifiers. However, the following theorem applies to recursively enumerable sets: 1) for any recursively enumerable set
. It was also found that sets with maximum degree of complexity exist even among sets defined by arithmetic predicates with two quantifiers. However, the following theorem applies to recursively enumerable sets: 1) for any recursively enumerable set  and any value
and any value  , the inequality
, the inequality 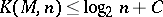 , where
, where 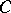 does not depend on
does not depend on  , is valid; and 2) there exists a recursively enumerable set
, is valid; and 2) there exists a recursively enumerable set  such that for any
such that for any  the inequality
the inequality 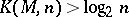 holds. At the same time there exists a recursively enumerable set
holds. At the same time there exists a recursively enumerable set 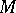 such that if the time
such that if the time 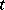 of computation of an arbitrary general recursive function is bounded, the estimate
of computation of an arbitrary general recursive function is bounded, the estimate 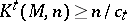 , where
, where  does not depend on
does not depend on  , is valid.
, is valid.
Sets which are universal with respect to a certain type of reducibility may also be defined in these terms (cf. Universal set): A set  is weakly tabularly universal if and only if there exists an unbounded general recursive function
is weakly tabularly universal if and only if there exists an unbounded general recursive function 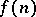 such that the inequality
such that the inequality 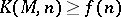 is valid for all values of
is valid for all values of  .
.
In studying the complexity of bounded algorithmic problems other measures of complexity may also be employed, e.g. the minimum of the length of the coding of the normal algorithm which solves the bounded problem in question. It was found, however, that asymptotically exact relations (cf. Algorithm, complexity of description of an) exist between the complexities introduced above and the analogues of these complexities expressed as the minimum length of the coding of an algorithm (or as the minimum number of internal states of a Turing machine).
Another concept which is introduced in constructing algorithmic information theory is that of conditional complexity of a word  , for a known
, for a known 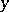 , using a partial recursive function
, using a partial recursive function 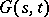 :
:
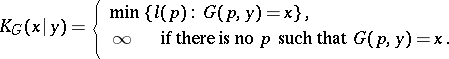 |
This concept is related to the theorem on the existence of an optimal function  , and the conditional complexity
, and the conditional complexity 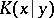 of a word
of a word  , if
, if 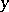 is known, is defined as the complexity
is known, is defined as the complexity 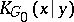 using an optimal function
using an optimal function 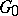 fixed once and for all. The intuitive meaning of
fixed once and for all. The intuitive meaning of 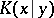 is the minimum quantity of information which must be added to the information contained in the word
is the minimum quantity of information which must be added to the information contained in the word 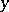 for the reconstitution of the word
for the reconstitution of the word  to be possible. Clearly,
to be possible. Clearly, 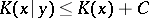 .
.
The next central concept of algorithmic information theory is the concept of the amount of information in an individual object 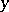 relative to an individual object
relative to an individual object  :
:
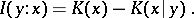 |
The quantity 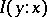 is called the algorithmic amount of information in
is called the algorithmic amount of information in 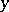 about
about  . The quantities
. The quantities 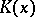 and
and 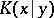 are sometimes called the algorithmic entropy of
are sometimes called the algorithmic entropy of  and the algorithmic conditional entropy of
and the algorithmic conditional entropy of  for a given
for a given 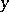 . The formulas for the decomposition of the entropy
. The formulas for the decomposition of the entropy 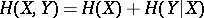 and of the commutation of information
and of the commutation of information 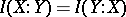 are valid in the algorithmic concept up to terms of order
are valid in the algorithmic concept up to terms of order 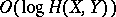 :
:
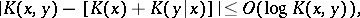 |
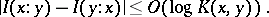 |
There exists a certain relation (due to Kolmogorov) between the algorithmic and the classical definitions of the amount of information (or, more exactly, between the complexity of a word according to Kolmogorov and the entropy of the Shannon distribution of frequencies): Let a number  be given, let the word
be given, let the word  of length
of length 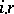 consist of
consist of 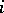 words of length
words of length  , and let the
, and let the 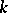 -th word of length
-th word of length  appear in
appear in  with a frequency
with a frequency 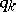 (
(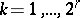 ); one then has
); one then has
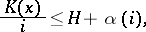 |
where
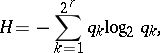 |
and 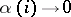 as
as 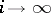 . In the general case no closer connection can be established between entropy and complexity. This is because entropy is intended to study sequences subject to frequency laws only. Consequently, one may establish the following relation for random sequences
. In the general case no closer connection can be established between entropy and complexity. This is because entropy is intended to study sequences subject to frequency laws only. Consequently, one may establish the following relation for random sequences  in measure between the magnitudes under study, which corresponds to independent trials:
in measure between the magnitudes under study, which corresponds to independent trials:
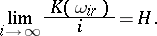 |
Similar considerations apply to an arbitrary ergodic stationary stochastic process.
References
| [1] | A.N. Kolmogorov, "Three approaches to the quantitative definition of information" Problems in Information Transmission , 1 (1965) pp. 1–7 Problemy Peredachi Informatsii , 1 : 1 (1965) pp. 3–11 |
| [2] | A.N. Kolmogorov, "On the logical foundations of information theory and probability theory" Problems Inform. Transmission , 5 : 3 (1969) pp. 1–4 Problemy Peredachi Informatsii , 5 : 3 (1969) pp. 3–7 |
| [3] | A.K. Zvonkin, L.A. Levin, "The complexity of finite objects and the developments of the concepts of information and randomness by means of the theory of algorithms" Russian Math. Surveys , 25 : 6 (1970) pp. 82–124 Uspekhi Mat. Nauk , 25 : 6 (1970) pp. 85–127 |
| [4] | Ya.M. Bardzin', "Complexity of programs to determine whether natural numbers not greater than  belong to a recursively enumerable set" Soviet Math. Dokl. , 9 : 5 (1968) pp. 1251–1254 Dokl. Akad. Nauk SSSR , 182 : 6 (1968) pp. 1249–1252 belong to a recursively enumerable set" Soviet Math. Dokl. , 9 : 5 (1968) pp. 1251–1254 Dokl. Akad. Nauk SSSR , 182 : 6 (1968) pp. 1249–1252 |
| [5] | M.I. Kanovich, "Complexity of resolution of a recursively enumerable set as a criterion of its universality" Soviet Math. Dokl. , 11 : 5 (1970) pp. 1224–1228 Dokl. Akad. Nauk SSSR , 194 : 3 (1970) pp. 500–503 |
Comments
The theory of Kolmogorov complexity, or "algorithmic information theory" , originated in the independent work of R.J. Solomonoff, Kolmogorov, L. Levin, Martin-Löf and G.J. Chaitin. Recently, J. Hartmanis has refined the theory by also considering the amount of work (time complexity) involved in reconstructing the original data from its description.
References
| [a1] | J. Hartmanis, "Generalized Kolmogorov complexity and the structure of feasible computations" , Proc. 24th IEEE Symposium on Foundations of Computer Science (1983) pp. 439–445 |
| [a2] | R.J. Solomonoff, "A formal theory of inductive inference, Part I and Part II" Information and Control , 7 (1964) pp. 1–22 |
| [a3] | P. Martin-Löf, "The definition of random sequences" Information and Control , 9 (1966) pp. 602–619 |
| [a4] | G.J. Chaitin, "Randomness and mathematical proof" Scientific American , May (1975) pp. 47–52 |
| [a5] | G.J. Chaitin, "Algorithmic information theory" IBM J. Res. Dev. , 21 (1977) pp. 350–359 |
Algorithmic information theory. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Algorithmic_information_theory&oldid=45076