Difference between revisions of "Rényi test"
Ulf Rehmann (talk | contribs) m (tex encoded by computer) |
Ulf Rehmann (talk | contribs) m (Undo revision 48598 by Ulf Rehmann (talk)) Tag: Undo |
||
| Line 1: | Line 1: | ||
| − | < | + | A [[Statistical test|statistical test]] used for testing a simple non-parametric hypothesis <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r0812701.png" /> (cf. [[Non-parametric methods in statistics|Non-parametric methods in statistics]]), according to which independent identically-distributed random variables <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r0812702.png" /> have a given continuous distribution function <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r0812703.png" />, against the alternatives: |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r0812704.png" /></td> </tr></table> | |
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r0812705.png" /></td> </tr></table> | |
| − | |||
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r0812706.png" /></td> </tr></table> | |
| − | |||
| − | |||
| − | |||
| − | + | where <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r0812707.png" /> is the empirical distribution function constructed with respect to the sample <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r0812708.png" /> and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r0812709.png" />, <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127010.png" />, is a weight function. If | |
| − | |||
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127011.png" /></td> </tr></table> | |
| − | |||
| − | |||
| − | |||
| − | where | + | where <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127012.png" /> is any fixed number from the interval <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127013.png" />, then the Rényi test, which was intended for testing <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127014.png" /> against the alternatives <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127015.png" />, <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127016.png" />, <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127017.png" />, is based on the Rényi statistics |
| − | is the | ||
| − | |||
| − | |||
| − | is | ||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127018.png" /></td> </tr></table> | |
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127019.png" /></td> </tr></table> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127020.png" /></td> </tr></table> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127021.png" /></td> </tr></table> | |
| − | = | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127022.png" /></td> </tr></table> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127023.png" /></td> </tr></table> | |
| − | = | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | where <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127024.png" /> are the members of the series of order statistics | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127025.png" /></td> </tr></table> | |
| − | = | ||
| − | |||
| − | |||
| − | + | constructed with respect to the observations <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127026.png" />. | |
| − | |||
| − | + | The statistics <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127027.png" /> and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127028.png" /> satisfy the same probability law and, if <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127029.png" />, then | |
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127030.png" /></td> <td valign="top" style="width:5%;text-align:right;">(1)</td></tr></table> | |
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127031.png" /></td> <td valign="top" style="width:5%;text-align:right;">(2)</td></tr></table> | |
| − | |||
| − | |||
| − | |||
| − | + | where <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127032.png" /> is the distribution function of the standard normal law (cf. [[Normal distribution|Normal distribution]]) and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127033.png" /> is the Rényi distribution function, | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127034.png" /></td> </tr></table> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | If <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127035.png" />, then | |
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127036.png" /></td> </tr></table> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | It follows from (1) and (2) that for larger values of <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127037.png" /> the following approximate values may be used to calculate the <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127038.png" />-percent critical values <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127039.png" /> for the statistics <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127040.png" /> and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127041.png" />: | |
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127042.png" /></td> </tr></table> | |
| − | |||
| − | + | respectively, where <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127043.png" /> and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127044.png" /> are the inverse functions to <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127045.png" /> and <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127046.png" />, respectively. This means that if <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127047.png" />, then <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127048.png" />. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | Furthermore, if <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127049.png" />, then it is advisable to use the approximate equation | |
| − | the | ||
| − | |||
| − | |||
| − | |||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127050.png" /></td> </tr></table> | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | when calculating the values of the Rényi distribution function <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127051.png" />; its degree of error does not exceed <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127052.png" />. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | when calculating the values of the Rényi distribution function | ||
| − | its degree of error does not exceed | ||
In addition to the Rényi test discused here, there are also similar tests, corresponding to the weight function | In addition to the Rényi test discused here, there are also similar tests, corresponding to the weight function | ||
| − | + | <table class="eq" style="width:100%;"> <tr><td valign="top" style="width:94%;text-align:center;"><img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127053.png" /></td> </tr></table> | |
| − | |||
| − | where | + | where <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127054.png" /> is any fixed number from the interval <img align="absmiddle" border="0" src="https://www.encyclopediaofmath.org/legacyimages/r/r081/r081270/r08127055.png" />. |
| − | is any fixed number from the interval | ||
====References==== | ====References==== | ||
<table><TR><TD valign="top">[1]</TD> <TD valign="top"> A. Rényi, "On the theory of order statistics" ''Acta Math. Acad. Sci. Hungar.'' , '''4''' (1953) pp. 191–231</TD></TR><TR><TD valign="top">[2]</TD> <TD valign="top"> J. Hájek, Z. Sidák, "Theory of rank tests" , Acad. Press (1967)</TD></TR><TR><TD valign="top">[3]</TD> <TD valign="top"> L.N. Bol'shev, N.V. Smirnov, "Tables of mathematical statistics" , ''Libr. math. tables'' , '''46''' , Nauka (1983) (In Russian) (Processed by L.S. Bark and E.S. Kedrova)</TD></TR></table> | <table><TR><TD valign="top">[1]</TD> <TD valign="top"> A. Rényi, "On the theory of order statistics" ''Acta Math. Acad. Sci. Hungar.'' , '''4''' (1953) pp. 191–231</TD></TR><TR><TD valign="top">[2]</TD> <TD valign="top"> J. Hájek, Z. Sidák, "Theory of rank tests" , Acad. Press (1967)</TD></TR><TR><TD valign="top">[3]</TD> <TD valign="top"> L.N. Bol'shev, N.V. Smirnov, "Tables of mathematical statistics" , ''Libr. math. tables'' , '''46''' , Nauka (1983) (In Russian) (Processed by L.S. Bark and E.S. Kedrova)</TD></TR></table> | ||
Revision as of 14:53, 7 June 2020
A statistical test used for testing a simple non-parametric hypothesis 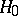 (cf. Non-parametric methods in statistics), according to which independent identically-distributed random variables
(cf. Non-parametric methods in statistics), according to which independent identically-distributed random variables 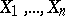 have a given continuous distribution function
have a given continuous distribution function 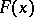 , against the alternatives:
, against the alternatives:
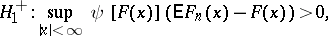 |
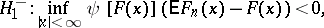 |
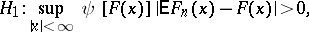 |
where 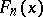 is the empirical distribution function constructed with respect to the sample
is the empirical distribution function constructed with respect to the sample 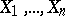 and
and 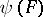 ,
, 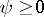 , is a weight function. If
, is a weight function. If
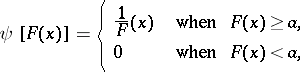 |
where  is any fixed number from the interval
is any fixed number from the interval 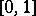 , then the Rényi test, which was intended for testing
, then the Rényi test, which was intended for testing 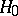 against the alternatives
against the alternatives 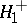 ,
, 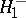 ,
, 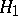 , is based on the Rényi statistics
, is based on the Rényi statistics
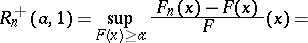 |
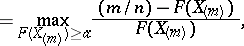 |
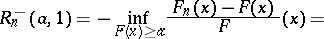 |
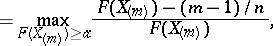 |
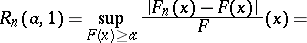 |
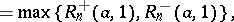 |
where 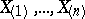 are the members of the series of order statistics
are the members of the series of order statistics
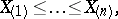 |
constructed with respect to the observations 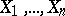 .
.
The statistics 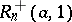 and
and 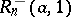 satisfy the same probability law and, if
satisfy the same probability law and, if 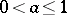 , then
, then
 | (1) |
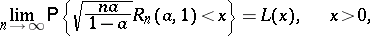 | (2) |
where 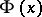 is the distribution function of the standard normal law (cf. Normal distribution) and
is the distribution function of the standard normal law (cf. Normal distribution) and 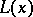 is the Rényi distribution function,
is the Rényi distribution function,
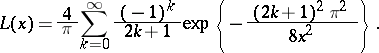 |
If 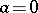 , then
, then
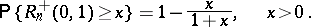 |
It follows from (1) and (2) that for larger values of  the following approximate values may be used to calculate the
the following approximate values may be used to calculate the 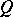 -percent critical values
-percent critical values 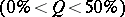 for the statistics
for the statistics 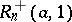 and
and 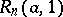 :
:
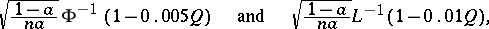 |
respectively, where 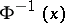 and
and 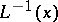 are the inverse functions to
are the inverse functions to 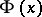 and
and 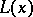 , respectively. This means that if
, respectively. This means that if 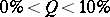 , then
, then 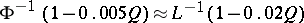 .
.
Furthermore, if 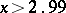 , then it is advisable to use the approximate equation
, then it is advisable to use the approximate equation
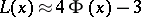 |
when calculating the values of the Rényi distribution function 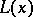 ; its degree of error does not exceed
; its degree of error does not exceed 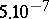 .
.
In addition to the Rényi test discused here, there are also similar tests, corresponding to the weight function
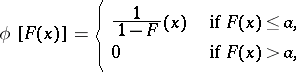 |
where  is any fixed number from the interval
is any fixed number from the interval 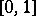 .
.
References
| [1] | A. Rényi, "On the theory of order statistics" Acta Math. Acad. Sci. Hungar. , 4 (1953) pp. 191–231 |
| [2] | J. Hájek, Z. Sidák, "Theory of rank tests" , Acad. Press (1967) |
| [3] | L.N. Bol'shev, N.V. Smirnov, "Tables of mathematical statistics" , Libr. math. tables , 46 , Nauka (1983) (In Russian) (Processed by L.S. Bark and E.S. Kedrova) |
Rényi test. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=R%C3%A9nyi_test&oldid=48598