Extrapolation algorithm
In numerical analysis and in applied mathematics, many methods produce sequences of numbers or vectors 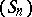 converging to a limit
converging to a limit 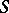 . This is the case in iterative methods but also when a result
. This is the case in iterative methods but also when a result 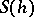 depends on a parameter
depends on a parameter  . An example is the trapezium formula for approximating a definite integral, or when a sequence of step-sizes
. An example is the trapezium formula for approximating a definite integral, or when a sequence of step-sizes 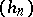 is used, thus leading to the sequence
is used, thus leading to the sequence 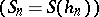 . Quite often in practice, the convergence of
. Quite often in practice, the convergence of 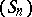 is slow and needs to be accelerated. For this purpose,
is slow and needs to be accelerated. For this purpose, 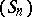 is transformed, by a sequence transformation
is transformed, by a sequence transformation 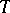 , into a new sequence
, into a new sequence 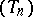 with the hope that
with the hope that 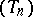 will converge to the same limit faster than
will converge to the same limit faster than 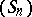 or, in other words, that
or, in other words, that 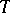 will accelerate the convergence of
will accelerate the convergence of 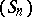 , which means
, which means
 |
Construction of a sequence transformation in the scalar case.
First, it is assumed that  behaves as a certain function
behaves as a certain function  of
of  depending on
depending on 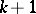 parameters
parameters  and
and  , and also, maybe, on some terms of the sequence
, and also, maybe, on some terms of the sequence 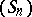 . These parameters are determined by imposing the interpolation conditions
. These parameters are determined by imposing the interpolation conditions
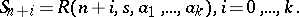 | (a1) |
Then  is taken as an approximation of the limit
is taken as an approximation of the limit 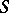 of the sequence
of the sequence 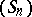 . Obviously,
. Obviously,  and
and  , obtained as the solution of (a1), depend on
, obtained as the solution of (a1), depend on  . For that reason,
. For that reason,  will be denoted by
will be denoted by 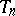 , which defines the sequence transformation
, which defines the sequence transformation 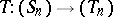 . If
. If 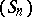 satisfies (a1) for all
satisfies (a1) for all  , where
, where  and the
and the  are constants independent of
are constants independent of  , then, by construction,
, then, by construction, 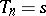 for all
for all  . Quite often, this condition is also necessary. The set of sequences satisfying this condition is called the kernel of the transformation
. Quite often, this condition is also necessary. The set of sequences satisfying this condition is called the kernel of the transformation 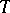 .
.
A sequence transformation constructed by such a procedure is called an extrapolation method.
Example.
Assume that 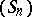 satisfies, for all
satisfies, for all  ,
, 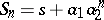 with
with 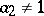 . Writing down (a1) with
. Writing down (a1) with 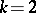 , and subtracting one relation from the next one, gives
, and subtracting one relation from the next one, gives
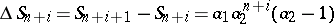 |
for 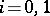 . Thus,
. Thus, 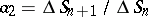 . Also,
. Also, 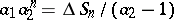 , which gives
, which gives 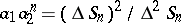 and finally
and finally
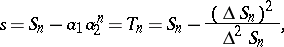 |
which is nothing else but the Aitken 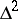 process. Another way of recovering this process is to assume that the sequence
process. Another way of recovering this process is to assume that the sequence 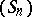 satisfies, for all
satisfies, for all  ,
, 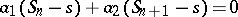 with
with  . So, the generality is not restricted by assuming that
. So, the generality is not restricted by assuming that  . As above, one finds by subtraction
. As above, one finds by subtraction 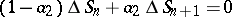 , which leads to
, which leads to 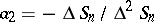 and finally to
and finally to 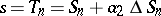 , which is the Aitken process again. It can also be written as
, which is the Aitken process again. It can also be written as
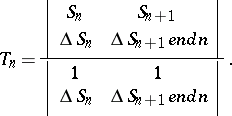 | (a2) |
Most sequence transformations can be written as a quotient of two determinants. As mentioned above, the kernel of a transformation depends on an integer 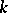 . To indicate this, denote
. To indicate this, denote 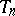 by
by 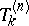 . Thus, the problem of the recursive computation of the
. Thus, the problem of the recursive computation of the 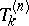 without computing these determinants arises. It can be proved (see, for example, [a2], pp. 18–26) that, since these quantities can be written as a quotient of two determinants, they can be recursively computed, for increasing values of
without computing these determinants arises. It can be proved (see, for example, [a2], pp. 18–26) that, since these quantities can be written as a quotient of two determinants, they can be recursively computed, for increasing values of  , by a triangular recursive scheme, which means that
, by a triangular recursive scheme, which means that 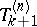 is obtained from
is obtained from 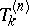 and
and 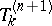 . Such a procedure is called an extrapolation algorithm. The converse of this result is also true, namely that any array of numbers
. Such a procedure is called an extrapolation algorithm. The converse of this result is also true, namely that any array of numbers 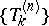 that can be computed by a triangular recursive scheme can be written as a ratio of two determinants.
that can be computed by a triangular recursive scheme can be written as a ratio of two determinants.
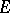 -algorithm.
-algorithm.
The most general extrapolation process currently known is the 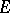 -algorithm. Its kernel is the set of sequences such that
-algorithm. Its kernel is the set of sequences such that 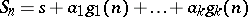 for all
for all  , where the
, where the 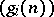 are known auxiliary sequences which can depend on certain terms of the sequence
are known auxiliary sequences which can depend on certain terms of the sequence 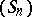 itself. Solving (a1), it is easy to see that
itself. Solving (a1), it is easy to see that
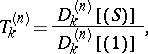 | (a3) |
where, for an arbitrary sequence 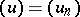 ,
,
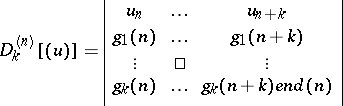 |
and where 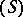 denotes the sequence
denotes the sequence 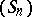 and
and 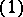 the sequence whose terms are all equal to one.
the sequence whose terms are all equal to one.
These quantities can be recursively computed by the 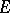 -algorithm, whose rules are as follows: for
-algorithm, whose rules are as follows: for 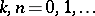 ,
,
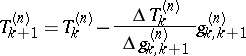 |
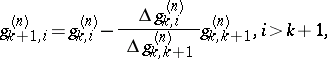 |
with 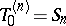 and
and 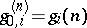 and where the operator
and where the operator 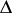 acts on the upper indices
acts on the upper indices  .
.
For the 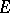 -algorithm it can be proved that if
-algorithm it can be proved that if 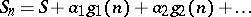 , where the
, where the 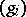 form an asymptotic series (that is,
form an asymptotic series (that is,  when
when  goes to infinity) and under certain additional technical assumptions, then, for any fixed value of
goes to infinity) and under certain additional technical assumptions, then, for any fixed value of 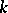 ,
, 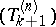 tends to
tends to 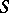 faster than
faster than 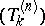 as
as  tends to infinity. This result is quite important since it shows that, for accelerating the convergence of a sequence
tends to infinity. This result is quite important since it shows that, for accelerating the convergence of a sequence 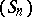 , it is necessary to know an asymptotic expansion of the error
, it is necessary to know an asymptotic expansion of the error 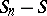 . Thus, there is a close connection between extrapolation and asymptotics, as explained in [a5].
. Thus, there is a close connection between extrapolation and asymptotics, as explained in [a5].
Generalization.
The Aitken process was generalized by D. Shanks, who considered a kernel of the form
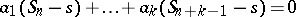 |
with 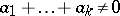 . The corresponding
. The corresponding 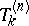 are given by the ratio of determinants (a3) with, in this case,
are given by the ratio of determinants (a3) with, in this case, 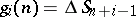 . It is an extension of (a2). These
. It is an extension of (a2). These 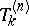 can be recursively computed by the
can be recursively computed by the  -algorithm of P. Wynn, whose rules are:
-algorithm of P. Wynn, whose rules are:
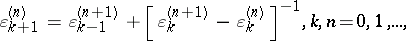 |
with 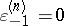 and
and 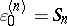 for
for 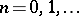 , and one obtains
, and one obtains 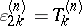 . The quantities
. The quantities 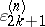 are intermediate results. This algorithm is related to Padé approximation. Indeed, if
are intermediate results. This algorithm is related to Padé approximation. Indeed, if 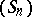 is the sequence of partial sums of a series
is the sequence of partial sums of a series 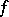 at the point
at the point 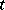 , then
, then 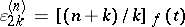 .
.
Among the well-known extrapolation algorithms, there is also the Richardson process (cf. also Richardson extrapolation), whose kernel is the set of sequences of the form 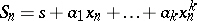 where
where 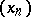 is an auxiliary known sequence. Thus, this process corresponds to polynomial extrapolation at the point
is an auxiliary known sequence. Thus, this process corresponds to polynomial extrapolation at the point  . The
. The 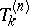 can again be written as (a3) with
can again be written as (a3) with 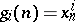 and they can be recursively computed by the Neville–Aitken scheme for constructing the interpolation polynomial.
and they can be recursively computed by the Neville–Aitken scheme for constructing the interpolation polynomial.
Obviously, an extrapolation algorithm will provide good approximations of the limit 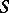 of the sequence
of the sequence  or, in other words, the transformation
or, in other words, the transformation  will accelerate the convergence, if the function
will accelerate the convergence, if the function 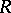 in (a1) well describes the exact behaviour of the sequence
in (a1) well describes the exact behaviour of the sequence 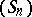 . This is the case, for example, in the Romberg method for accelerating the convergence of the sequence obtained by the trapezium formula for computing a definite integral. Indeed, using Euler–MacLaurin expansion (cf. Euler–MacLaurin formula), it can be proved that the error can be written as a series in
. This is the case, for example, in the Romberg method for accelerating the convergence of the sequence obtained by the trapezium formula for computing a definite integral. Indeed, using Euler–MacLaurin expansion (cf. Euler–MacLaurin formula), it can be proved that the error can be written as a series in 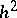 and the Romberg method is based on polynomial extrapolation at
and the Romberg method is based on polynomial extrapolation at  by a polynomial in
by a polynomial in  . Note that, sometimes, extrapolation algorithms are able to sum diverging sequences and series.
. Note that, sometimes, extrapolation algorithms are able to sum diverging sequences and series.
There exist many other extrapolation processes. It is important to define many such processes since each of them is only able to accelerate the convergence of certain classes of sequences and, as has been proved by J.P. Delahaye and B. Germain-Bonne [a4], a universal algorithm able to accelerate the convergence of all convergent sequences cannot exist. This is because this class is too large. Even for smaller classes, such as the class of monotonic sequences, such a universal algorithm cannot exist.
Vector sequences.
Clearly, for accelerating the convergence of vector sequences it is possible to use a scalar extrapolation method for each component of the vectors. However, in practice, vector sequences are often generated by an iterative process and applying a scalar transformation separately on each component does not take into account the connections existing between the various components. Thus, it is better to use an extrapolation algorithm specially built for vector sequences. So, there exists vector variants of most scalar algorithms. Quite often, such processes are related to projection methods [a1].
On extrapolation methods, see [a2], [a3] and [a7]. FORTRAN subroutines of many extrapolation algorithms can be found in [a2]. Various applications are described in [a6].
References
| [a1] | C. Brezinski, "Projection methods for systems of equations" , North-Holland (1997) |
| [a2] | C. Brezinski, M. Redivo Zaglia, "Extrapolation methods. Theory and practice" , North-Holland (1991) |
| [a3] | J.P. Delahaye, "Sequence transformations" , Springer (1988) |
| [a4] | J.P. Delahaye, B. Germain–Bonne, "Résultats négatifs en accélération de la convergence" Numer. Math. , 35 (1980) pp. 443–457 |
| [a5] | G. Walz, "Asymptotics and extrapolation" , Akad. Verlag (1996) |
| [a6] | E.J. Weniger, "Nonlinear sequence transformations for the acceleration of convergence and the summation of divergent series" Comput. Physics Reports , 10 (1989) pp. 189–371 |
| [a7] | J. Wimp, "Sequence transformations and their applications" , Acad. Press (1981) |
Extrapolation algorithm. Encyclopedia of Mathematics. URL: http://encyclopediaofmath.org/index.php?title=Extrapolation_algorithm&oldid=15933